 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate SMT Counting Beyond Discrete Domains
Jul 24, 2025Satisfiability Modulo Theory (SMT) solvers have advanced automated reasoning, solving complex formulas across discrete and continuous domains. Recent progress in propositional model counting motivates extending SMT capabilities toward model counting, especially for hybrid SMT formulas. Existing approaches, like bit-blasting, are limited to discrete variables, highlighting the challenge of counting solutions projected onto the discrete domain in hybrid formulas. We introduce pact, an SMT model counter for hybrid formulas that uses hashing-based approximate model counting to estimate solutions with theoretical guarantees. pact makes a logarithmic number of SMT solver calls relative to the projection variables, leveraging optimized hash functions. pact achieves significant performance improvements over baselines on a large suite of benchmarks. In particular, out of 14,202 instances, pact successfully finished on 603 instances, while Baseline could only finish on 13 instances.
Enumerate-Conjecture-Prove: Formally Solving Answer-Construction Problems in Math Competitions
May 24, 2025Mathematical reasoning lies at the heart of artificial intelligence, underpinning applications in education, program verification, and research-level mathematical discovery. Mathematical competitions, in particular, present two challenging problem types: theorem-proving, requiring rigorous proofs of stated conclusions, and answer-construction, involving hypothesizing and formally verifying mathematical objects. Large Language Models (LLMs) effectively generate creative candidate answers but struggle with formal verification, while symbolic provers ensure rigor but cannot efficiently handle creative conjecture generation. We introduce the Enumerate-Conjecture-Prove (ECP) framework, a modular neuro-symbolic method integrating LLM-based enumeration and pattern-driven conjecturing with formal theorem proving. We present ConstructiveBench, a dataset of 3,431 answer-construction problems in various math competitions with verified Lean formalizations. On the ConstructiveBench dataset, ECP improves the accuracy of answer construction from the Chain-of-Thought (CoT) baseline of 14.54% to 45.06% with the gpt-4.1-mini model. Moreover, combining with ECP's constructed answers, the state-of-the-art DeepSeek-Prover-V2-7B model generates correct proofs for 858 of the 3,431 constructive problems in Lean, achieving 25.01% accuracy, compared to 9.86% for symbolic-only baselines. Our code and dataset are publicly available at GitHub and HuggingFace, respectively.
Towards Practical First-Order Model Counting
Feb 17, 2025First-order model counting (FOMC) is the problem of counting the number of models of a sentence in first-order logic. Since lifted inference techniques rely on reductions to variants of FOMC, the design of scalable methods for FOMC has attracted attention from both theoreticians and practitioners over the past decade. Recently, a new approach based on first-order knowledge compilation was proposed. This approach, called Crane, instead of simply providing the final count, generates definitions of (possibly recursive) functions that can be evaluated with different arguments to compute the model count for any domain size. However, this approach is not fully automated, as it requires manual evaluation of the constructed functions. The primary contribution of this work is a fully automated compilation algorithm, called Gantry, which transforms the function definitions into C++ code equipped with arbitrary-precision arithmetic. These additions allow the new FOMC algorithm to scale to domain sizes over 500,000 times larger than the current state of the art, as demonstrated through experimental results.
Towards Projected and Incremental Pseudo-Boolean Model Counting
Dec 19, 2024Model counting is a fundamental task that involves determining the number of satisfying assignments to a logical formula, typically in conjunctive normal form (CNF). While CNF model counting has received extensive attention over recent decades, interest in Pseudo-Boolean (PB) model counting is just emerging partly due to the greater flexibility of PB formulas. As such, we observed feature gaps in existing PB counters such as a lack of support for projected and incremental settings, which could hinder adoption. In this work, our main contribution is the introduction of the PB model counter PBCount2, the first exact PB model counter with support for projected and incremental model counting. Our counter, PBCount2, uses our Least Occurrence Weighted Min Degree (LOW-MD) computation ordering heuristic to support projected model counting and a cache mechanism to enable incremental model counting. In our evaluations, PBCount2 completed at least 1.40x the number of benchmarks of competing methods for projected model counting and at least 1.18x of competing methods in incremental model counting.
Model Counting in the Wild
Aug 13, 2024



Model counting is a fundamental problem in automated reasoning with applications in probabilistic inference, network reliability, neural network verification, and more. Although model counting is computationally intractable from a theoretical perspective due to its #P-completeness, the past decade has seen significant progress in developing state-of-the-art model counters to address scalability challenges. In this work, we conduct a rigorous assessment of the scalability of model counters in the wild. To this end, we surveyed 11 application domains and collected an aggregate of 2262 benchmarks from these domains. We then evaluated six state-of-the-art model counters on these instances to assess scalability and runtime performance. Our empirical evaluation demonstrates that the performance of model counters varies significantly across different application domains, underscoring the need for careful selection by the end user. Additionally, we investigated the behavior of different counters with respect to two parameters suggested by the model counting community, finding only a weak correlation. Our analysis highlights the challenges and opportunities for portfolio-based approaches in model counting.
The Cardinality of Identifying Code Sets for Soccer Ball Graph with Application to Remote Sensing
Jul 19, 2024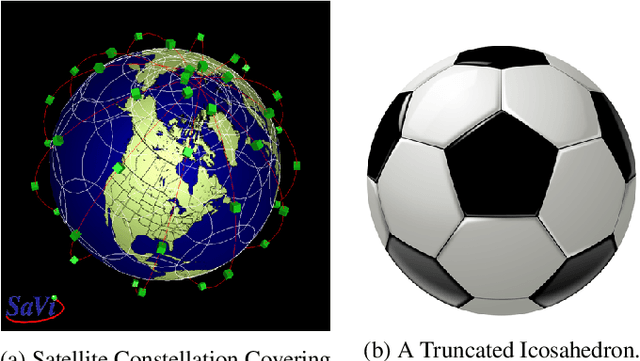

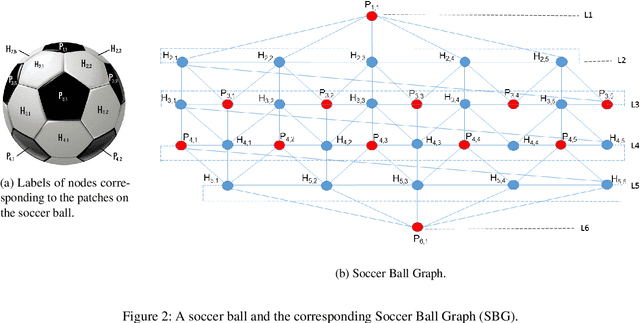

In the context of satellite monitoring of the earth, we can assume that the surface of the earth is divided into a set of regions. We assume that the impact of a big social/environmental event spills into neighboring regions. Using Identifying Code Sets (ICSes), we can deploy sensors in such a way that the region in which an event takes place can be uniquely identified, even with fewer sensors than regions. As Earth is almost a sphere, we use a soccer ball as a model. We construct a Soccer Ball Graph (SBG), and provide human-oriented, analytical proofs that 1) the SBG has at least 26 ICSes of cardinality ten, implying that there are at least 26 different ways to deploy ten satellites to monitor the Earth and 2) that the cardinality of the minimum Identifying Code Set (MICS) for the SBG is at least nine. We then provide a machine-oriented formal proof that the cardinality of the MICS for the SBG is in fact ten, meaning that one must deploy at least ten satellites to monitor the Earth in the SBG model. We also provide machine-oriented proof that there are exactly 26 ICSes of cardinality ten for the SBG.
Formally Certified Approximate Model Counting
Jun 17, 2024Approximate model counting is the task of approximating the number of solutions to an input Boolean formula. The state-of-the-art approximate model counter for formulas in conjunctive normal form (CNF), ApproxMC, provides a scalable means of obtaining model counts with probably approximately correct (PAC)-style guarantees. Nevertheless, the validity of ApproxMC's approximation relies on a careful theoretical analysis of its randomized algorithm and the correctness of its highly optimized implementation, especially the latter's stateful interactions with an incremental CNF satisfiability solver capable of natively handling parity (XOR) constraints. We present the first certification framework for approximate model counting with formally verified guarantees on the quality of its output approximation. Our approach combines: (i) a static, once-off, formal proof of the algorithm's PAC guarantee in the Isabelle/HOL proof assistant; and (ii) dynamic, per-run, verification of ApproxMC's calls to an external CNF-XOR solver using proof certificates. We detail our general approach to establish a rigorous connection between these two parts of the verification, including our blueprint for turning the formalized, randomized algorithm into a verified proof checker, and our design of proof certificates for both ApproxMC and its internal CNF-XOR solving steps. Experimentally, we show that certificate generation adds little overhead to an approximate counter implementation, and that our certificate checker is able to fully certify $84.7\%$ of instances with generated certificates when given the same time and memory limits as the counter.
Locally-Minimal Probabilistic Explanations
Dec 20, 2023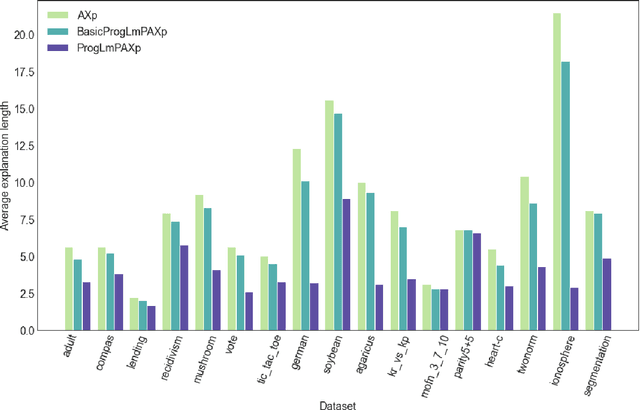

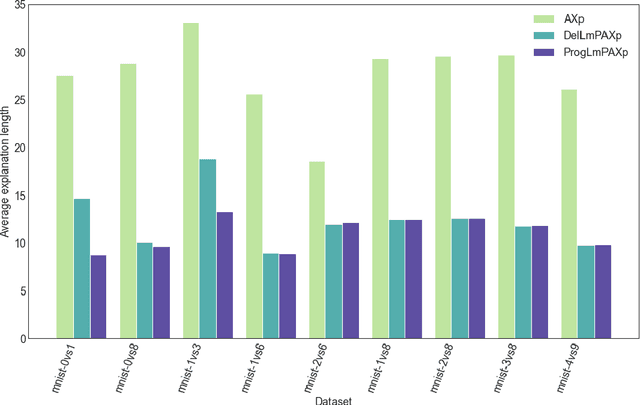
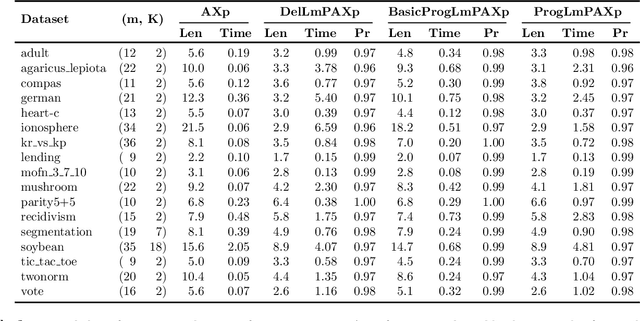
Formal abductive explanations offer crucial guarantees of rigor and so are of interest in high-stakes uses of machine learning (ML). One drawback of abductive explanations is explanation size, justified by the cognitive limits of human decision-makers. Probabilistic abductive explanations (PAXps) address this limitation, but their theoretical and practical complexity makes their exact computation most often unrealistic. This paper proposes novel efficient algorithms for the computation of locally-minimal PXAps, which offer high-quality approximations of PXAps in practice. The experimental results demonstrate the practical efficiency of the proposed algorithms.
Auditable Algorithms for Approximate Model Counting
Dec 19, 2023Model counting, or counting the satisfying assignments of a Boolean formula, is a fundamental problem with diverse applications. Given #P-hardness of the problem, developing algorithms for approximate counting is an important research area. Building on the practical success of SAT-solvers, the focus has recently shifted from theory to practical implementations of approximate counting algorithms. This has brought to focus new challenges, such as the design of auditable approximate counters that not only provide an approximation of the model count, but also a certificate that a verifier with limited computational power can use to check if the count is indeed within the promised bounds of approximation. Towards generating certificates, we start by examining the best-known deterministic approximate counting algorithm that uses polynomially many calls to a $\Sigma_2^P$ oracle. We show that this can be audited via a $\Sigma_2^P$ oracle with the query constructed over $n^2 \log^2 n$ variables, where the original formula has $n$ variables. Since $n$ is often large, we ask if the count of variables in the certificate can be reduced -- a crucial question for potential implementation. We show that this is indeed possible with a tradeoff in the counting algorithm's complexity. Specifically, we develop new deterministic approximate counting algorithms that invoke a $\Sigma_3^P$ oracle, but can be certified using a $\Sigma_2^P$ oracle using certificates on far fewer variables: our final algorithm uses only $n \log n$ variables. Our study demonstrates that one can simplify auditing significantly if we allow the counting algorithm to access a slightly more powerful oracle. This shows for the first time how audit complexity can be traded for complexity of approximate counting.
Engineering an Exact Pseudo-Boolean Model Counter
Dec 19, 2023



Model counting, a fundamental task in computer science, involves determining the number of satisfying assignments to a Boolean formula, typically represented in conjunctive normal form (CNF). While model counting for CNF formulas has received extensive attention with a broad range of applications, the study of model counting for Pseudo-Boolean (PB) formulas has been relatively overlooked. Pseudo-Boolean formulas, being more succinct than propositional Boolean formulas, offer greater flexibility in representing real-world problems. Consequently, there is a crucial need to investigate efficient techniques for model counting for PB formulas. In this work, we propose the first exact Pseudo-Boolean model counter, PBCount, that relies on knowledge compilation approach via algebraic decision diagrams. Our extensive empirical evaluation shows that PBCount can compute counts for 1513 instances while the current state-of-the-art approach could only handle 1013 instances. Our work opens up several avenues for future work in the context of model counting for PB formulas, such as the development of preprocessing techniques and exploration of approaches other than knowledge compilation.