 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal High-Probability Regret for Online Convex Optimization with Two-Point Bandit Feedback
Mar 26, 2026We consider the problem of Online Convex Optimization (OCO) with two-point bandit feedback in an adversarial environment. In this setting, a player attempts to minimize a sequence of adversarially generated convex loss functions, while only observing the value of each function at two points. While it is well-known that two-point feedback allows for gradient estimation, achieving tight high-probability regret bounds for strongly convex functions still remained open as highlighted by \citet{agarwal2010optimal}. The primary challenge lies in the heavy-tailed nature of bandit gradient estimators, which makes standard concentration analysis difficult. In this paper, we resolve this open challenge by providing the first high-probability regret bound of $O(d(\log T + \log(1/δ))/μ)$ for $μ$-strongly convex losses. Our result is minimax optimal with respect to both the time horizon $T$ and the dimension $d$.
On the Convergence of Single-Loop Stochastic Bilevel Optimization with Approximate Implicit Differentiation
Feb 27, 2026Stochastic Bilevel Optimization has emerged as a fundamental framework for meta-learning and hyperparameter optimization. Despite the practical prevalence of single-loop algorithms--which update lower and upper variables concurrently--their theoretical understanding, particularly in the stochastic regime, remains significantly underdeveloped compared to their multi-loop counterparts. Existing analyses often yield suboptimal convergence rates or obscure the critical dependence on the lower-level condition number $κ$, frequently burying it within generic Lipschitz constants. In this paper, we bridge this gap by providing a refined convergence analysis of the Single-loop Stochastic Approximate Implicit Differentiation (SSAID) algorithm. We prove that SSAID achieves an $ε$-stationary point with an oracle complexity of $\mathcal{O}(κ^7 ε^{-2})$. Our result is noteworthy in two aspects: (i) it matches the optimal $\mathcal{O}(ε^{-2})$ rate of state-of-the-art multi-loop methods (e.g., stocBiO) while maintaining the computational efficiency of a single-loop update; and (ii) it provides the first explicit, fine-grained characterization of the $κ$-dependence for stochastic AID-based single-loop methods. This work demonstrates that SSAID is not merely a heuristic approach, but admits a rigorous theoretical foundation with convergence guarantees competitive with mainstream multi-loop frameworks.
From $O(mn)$ to $O(r^2)$: Two-Sided Low-Rank Communication for Adam in Distributed Training with Memory Efficiency
Feb 08, 2026As foundation models continue to scale, pretraining increasingly relies on data-parallel distributed optimization, making bandwidth-limited gradient synchronization a key bottleneck. Orthogonally, projection-based low-rank optimizers were mainly designed for memory efficiency, but remain suboptimal for communication-limited training: one-sided synchronization still transmits an $O(rn)$ object for an $m\times n$ matrix gradient and refresh steps can dominate peak communicated bytes. We propose TSR, which brings two-sided low-rank communication to Adam-family updates (TSR-Adam) by synchronizing a compact core $U^\top G V\in\mathbb{R}^{r\times r}$, reducing the dominant per-step payload from $O(mn)$ to $O(r^2)$ while keeping moment states in low-dimensional cores. To further reduce the peak communication from subspace refresh, TSR-Adam adopts a randomized SVD-based refresh that avoids full-gradient synchronization. We additionally extend low-rank communication to embedding gradients with embedding-specific ranks and refresh schedules, yielding additional communication and memory savings over keeping embeddings dense. Across pretraining from 60M to 1B model scales, TSR-Adam reduces average communicated bytes per step by $13\times$, and on GLUE fine-tuning it reduces communication by $25\times$, while achieving comparable performance; we further provide a theoretical stationarity analysis for the proposed update. Code is available at https://github.com/DKmiyan/TSR-Adam.
ESSAM: A Novel Competitive Evolution Strategies Approach to Reinforcement Learning for Memory Efficient LLMs Fine-Tuning
Feb 01, 2026Reinforcement learning (RL) has become a key training step for improving mathematical reasoning in large language models (LLMs), but it often has high GPU memory usage, which makes it hard to use in settings with limited resources. To reduce these issues, we propose Evolution Strategies with Sharpness-Aware Maximization (ESSAM), a full parameter fine-tuning framework that tightly combines the zero-order search in parameter space from Evolution Strategies (ES) with the Sharpness-Aware Maximization (SAM) to improve generalization. We conduct fine-tuning experiments on the mainstream mathematica reasoning task GSM8K. The results show that ESSAM achieves an average accuracy of 78.27\% across all models and its overall performance is comparable to RL methods. It surpasses classic RL algorithm PPO with an accuracy of 77.72\% and is comparable to GRPO with an accuracy of 78.34\%, and even surpassing them on some models. In terms of GPU memory usage, ESSAM reduces the average GPU memory usage by $18\times$ compared to PPO and by $10\times$ compared to GRPO, achieving an extremely low GPU memory usage.
Explicit and Non-asymptotic Query Complexities of Rank-Based Zeroth-order Algorithm on Stochastic Smooth Functions
Dec 22, 2025Zeroth-order (ZO) optimization with ordinal feedback has emerged as a fundamental problem in modern machine learning systems, particularly in human-in-the-loop settings such as reinforcement learning from human feedback, preference learning, and evolutionary strategies. While rank-based ZO algorithms enjoy strong empirical success and robustness properties, their theoretical understanding, especially under stochastic objectives and standard smoothness assumptions, remains limited. In this paper, we study rank-based zeroth-order optimization for stochastic functions where only ordinal feedback of the stochastic function is available. We propose a simple and computationally efficient rank-based ZO algorithm. Under standard assumptions including smoothness, strong convexity, and bounded second moments of stochastic gradients, we establish explicit non-asymptotic query complexity bounds for both convex and nonconvex objectives. Notably, our results match the best-known query complexities of value-based ZO algorithms, demonstrating that ordinal information alone is sufficient for optimal query efficiency in stochastic settings. Our analysis departs from existing drift-based and information-geometric techniques, offering new tools for the study of rank-based optimization under noise. These findings narrow the gap between theory and practice and provide a principled foundation for optimization driven by human preferences.
MSCR: Exploring the Vulnerability of LLMs' Mathematical Reasoning Abilities Using Multi-Source Candidate Replacement
Nov 11, 2025LLMs demonstrate performance comparable to human abilities in complex tasks such as mathematical reasoning, but their robustness in mathematical reasoning under minor input perturbations still lacks systematic investigation. Existing methods generally suffer from limited scalability, weak semantic preservation, and high costs. Therefore, we propose MSCR, an automated adversarial attack method based on multi-source candidate replacement. By combining three information sources including cosine similarity in the embedding space of LLMs, the WordNet dictionary, and contextual predictions from a masked language model, we generate for each word in the input question a set of semantically similar candidates, which are then filtered and substituted one by one to carry out the attack. We conduct large-scale experiments on LLMs using the GSM8K and MATH500 benchmarks. The results show that even a slight perturbation involving only a single word can significantly reduce the accuracy of all models, with the maximum drop reaching 49.89% on GSM8K and 35.40% on MATH500, while preserving the high semantic consistency of the perturbed questions. Further analysis reveals that perturbations not only lead to incorrect outputs but also substantially increase the average response length, which results in more redundant reasoning paths and higher computational resource consumption. These findings highlight the robustness deficiencies and efficiency bottlenecks of current LLMs in mathematical reasoning tasks.
Numerical Sensitivity and Robustness: Exploring the Flaws of Mathematical Reasoning in Large Language Models
Nov 11, 2025
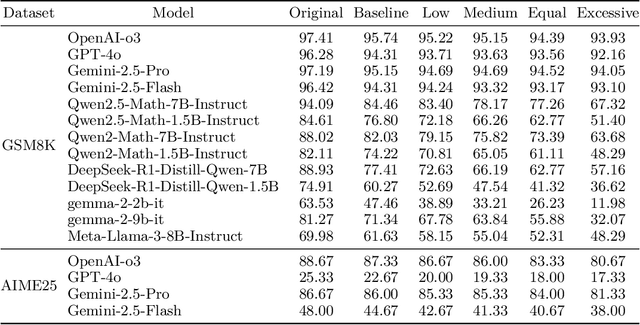

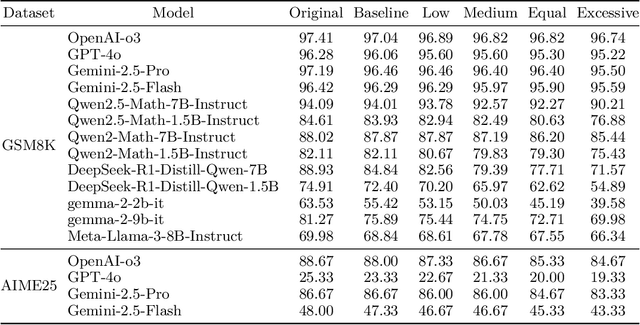
LLMs have made significant progress in the field of mathematical reasoning, but whether they have true the mathematical understanding ability is still controversial. To explore this issue, we propose a new perturbation framework to evaluate LLMs' reasoning ability in complex environments by injecting additional semantically irrelevant perturbation sentences and gradually increasing the perturbation intensity. At the same time, we use an additional perturbation method: core questioning instruction missing, to further analyze the LLMs' problem-solving mechanism. The experimental results show that LLMs perform stably when facing perturbation sentences without numbers, but there is also a robustness boundary. As the perturbation intensity increases, the performance exhibits varying degrees of decline; when facing perturbation sentences with numbers, the performance decreases more significantly, most open source models with smaller parameters decrease by nearly or even more than 10%, and further increasing with the enhancement of perturbation intensity, with the maximum decrease reaching 51.55%. Even the most advanced commercial LLMs have seen a 3%-10% performance drop. By analyzing the reasoning process of LLMs in detail, We find that models are more sensitive to perturbations with numerical information and are more likely to give incorrect answers when disturbed by irrelevant numerical information. The higher the perturbation intensity, the more obvious these defects are. At the same time, in the absence of core questioning instruction, models can still maintain an accuracy of 20%-40%, indicating that LLMs may rely on memory templates or pattern matching to complete the task, rather than logical reasoning. In general, our work reveals the shortcomings and limitations of current LLMs in their reasoning capabilities, which is of great significance for the further development of LLMs.
Frustratingly Easy Task-aware Pruning for Large Language Models
Oct 26, 2025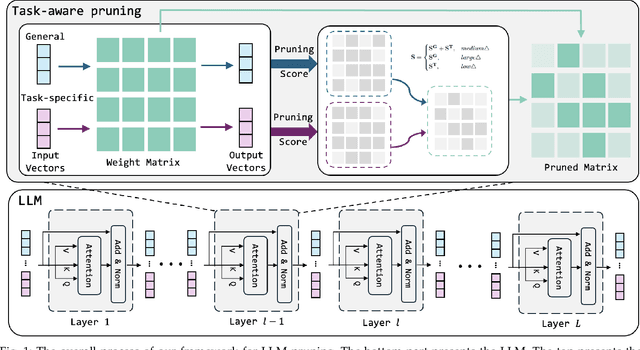
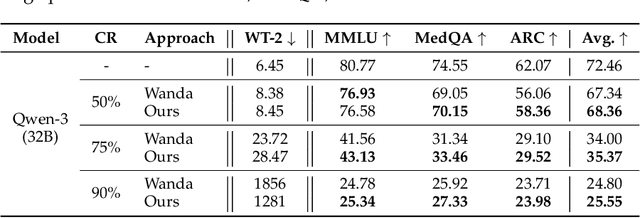
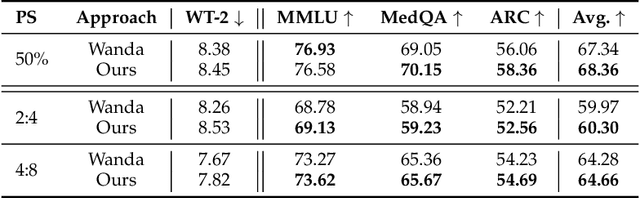
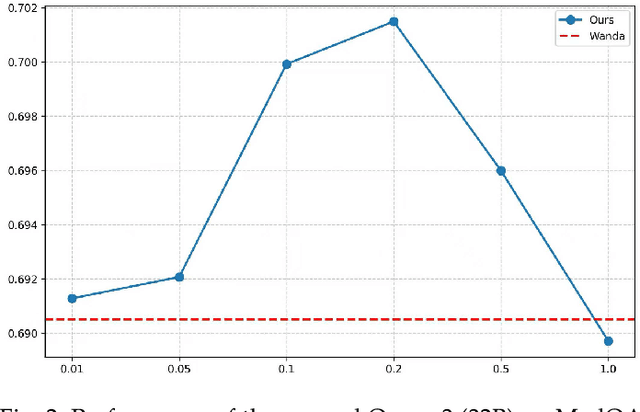
Pruning provides a practical solution to reduce the resources required to run large language models (LLMs) to benefit from their effective capabilities as well as control their cost for training and inference. Research on LLM pruning often ranks the importance of LLM parameters using their magnitudes and calibration-data activations and removes (or masks) the less important ones, accordingly reducing LLMs' size. However, these approaches primarily focus on preserving the LLM's ability to generate fluent sentences, while neglecting performance on specific domains and tasks. In this paper, we propose a simple yet effective pruning approach for LLMs that preserves task-specific capabilities while shrinking their parameter space. We first analyze how conventional pruning minimizes loss perturbation under general-domain calibration and extend this formulation by incorporating task-specific feature distributions into the importance computation of existing pruning algorithms. Thus, our framework computes separate importance scores using both general and task-specific calibration data, partitions parameters into shared and exclusive groups based on activation-norm differences, and then fuses their scores to guide the pruning process. This design enables our method to integrate seamlessly with various foundation pruning techniques and preserve the LLM's specialized abilities under compression. Experiments on widely used benchmarks demonstrate that our approach is effective and consistently outperforms the baselines with identical pruning ratios and different settings.
FZOO: Fast Zeroth-Order Optimizer for Fine-Tuning Large Language Models towards Adam-Scale Speed
Jun 10, 2025Fine-tuning large language models (LLMs) often faces GPU memory bottlenecks: the backward pass of first-order optimizers like Adam increases memory usage to more than 10 times the inference level (e.g., 633 GB for OPT-30B). Zeroth-order (ZO) optimizers avoid this cost by estimating gradients only from forward passes, yet existing methods like MeZO usually require many more steps to converge. Can this trade-off between speed and memory in ZO be fundamentally improved? Normalized-SGD demonstrates strong empirical performance with greater memory efficiency than Adam. In light of this, we introduce FZOO, a Fast Zeroth-Order Optimizer toward Adam-Scale Speed. FZOO reduces the total forward passes needed for convergence by employing batched one-sided estimates that adapt step sizes based on the standard deviation of batch losses. It also accelerates per-batch computation through the use of Rademacher random vector perturbations coupled with CUDA's parallel processing. Extensive experiments on diverse models, including RoBERTa-large, OPT (350M-66B), Phi-2, and Llama3, across 11 tasks validate FZOO's effectiveness. On average, FZOO outperforms MeZO by 3 percent in accuracy while requiring 3 times fewer forward passes. For RoBERTa-large, FZOO achieves average improvements of 5.6 percent in accuracy and an 18 times reduction in forward passes compared to MeZO, achieving convergence speeds comparable to Adam. We also provide theoretical analysis proving FZOO's formal equivalence to a normalized-SGD update rule and its convergence guarantees. FZOO integrates smoothly into PEFT techniques, enabling even larger memory savings. Overall, our results make single-GPU, high-speed, full-parameter fine-tuning practical and point toward future work on memory-efficient pre-training.
Towards Understanding The Calibration Benefits of Sharpness-Aware Minimization
May 29, 2025Deep neural networks have been increasingly used in safety-critical applications such as medical diagnosis and autonomous driving. However, many studies suggest that they are prone to being poorly calibrated and have a propensity for overconfidence, which may have disastrous consequences. In this paper, unlike standard training such as stochastic gradient descent, we show that the recently proposed sharpness-aware minimization (SAM) counteracts this tendency towards overconfidence. The theoretical analysis suggests that SAM allows us to learn models that are already well-calibrated by implicitly maximizing the entropy of the predictive distribution. Inspired by this finding, we further propose a variant of SAM, coined as CSAM, to ameliorate model calibration. Extensive experiments on various datasets, including ImageNet-1K, demonstrate the benefits of SAM in reducing calibration error. Meanwhile, CSAM performs even better than SAM and consistently achieves lower calibration error than other approaches