 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding The Calibration Benefits of Sharpness-Aware Minimization
May 29, 2025Deep neural networks have been increasingly used in safety-critical applications such as medical diagnosis and autonomous driving. However, many studies suggest that they are prone to being poorly calibrated and have a propensity for overconfidence, which may have disastrous consequences. In this paper, unlike standard training such as stochastic gradient descent, we show that the recently proposed sharpness-aware minimization (SAM) counteracts this tendency towards overconfidence. The theoretical analysis suggests that SAM allows us to learn models that are already well-calibrated by implicitly maximizing the entropy of the predictive distribution. Inspired by this finding, we further propose a variant of SAM, coined as CSAM, to ameliorate model calibration. Extensive experiments on various datasets, including ImageNet-1K, demonstrate the benefits of SAM in reducing calibration error. Meanwhile, CSAM performs even better than SAM and consistently achieves lower calibration error than other approaches
Polar R-CNN: End-to-End Lane Detection with Fewer Anchors
Nov 03, 2024



Lane detection is a critical and challenging task in autonomous driving, particularly in real-world scenarios where traffic lanes can be slender, lengthy, and often obscured by other vehicles, complicating detection efforts. Existing anchor-based methods typically rely on prior lane anchors to extract features and subsequently refine the location and shape of lanes. While these methods achieve high performance, manually setting prior anchors is cumbersome, and ensuring sufficient coverage across diverse datasets often requires a large amount of dense anchors. Furthermore, the use of Non-Maximum Suppression (NMS) to eliminate redundant predictions complicates real-world deployment and may underperform in complex scenarios. In this paper, we propose Polar R-CNN, an end-to-end anchor-based method for lane detection. By incorporating both local and global polar coordinate systems, Polar R-CNN facilitates flexible anchor proposals and significantly reduces the number of anchors required without compromising performance.Additionally, we introduce a triplet head with heuristic structure that supports NMS-free paradigm, enhancing deployment efficiency and performance in scenarios with dense lanes.Our method achieves competitive results on five popular lane detection benchmarks--Tusimple, CULane,LLAMAS, CurveLanes, and DL-Rai--while maintaining a lightweight design and straightforward structure. Our source code is available at https://github.com/ShqWW/PolarRCNN.
Exclusive Style Removal for Cross Domain Novel Class Discovery
Jun 26, 2024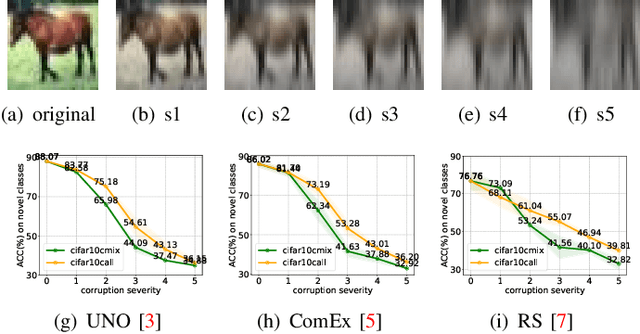
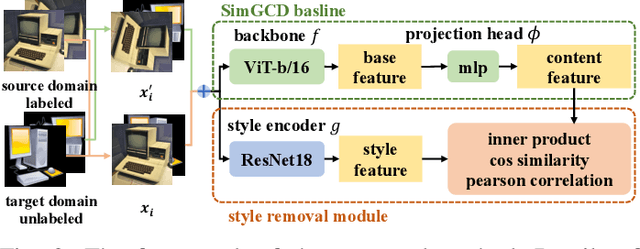
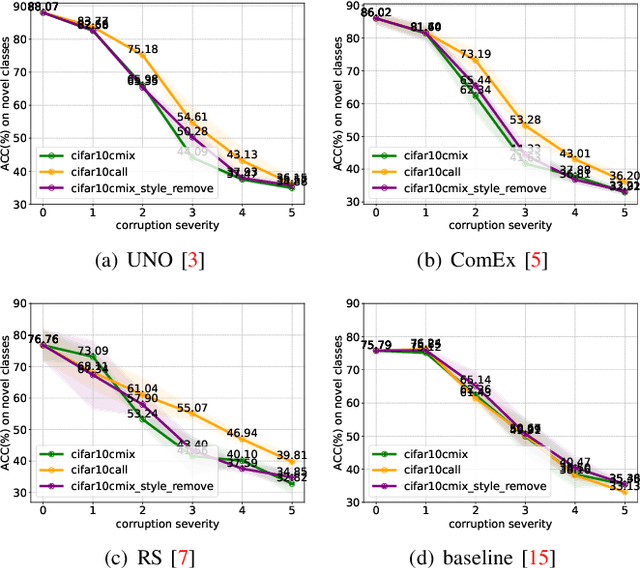

As a promising field in open-world learning, \textit{Novel Class Discovery} (NCD) is usually a task to cluster unseen novel classes in an unlabeled set based on the prior knowledge of labeled data within the same domain. However, the performance of existing NCD methods could be severely compromised when novel classes are sampled from a different distribution with the labeled ones. In this paper, we explore and establish the solvability of NCD in cross domain setting with the necessary condition that style information must be removed. Based on the theoretical analysis, we introduce an exclusive style removal module for extracting style information that is distinctive from the baseline features, thereby facilitating inference. Moreover, this module is easy to integrate with other NCD methods, acting as a plug-in to improve performance on novel classes with different distributions compared to the seen labeled set. Additionally, recognizing the non-negligible influence of different backbones and pre-training strategies on the performance of the NCD methods, we build a fair benchmark for future NCD research. Extensive experiments on three common datasets demonstrate the effectiveness of our proposed module.
Stabilizing Sharpness-aware Minimization Through A Simple Renormalization Strategy
Jan 14, 2024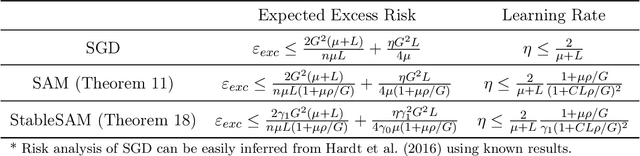
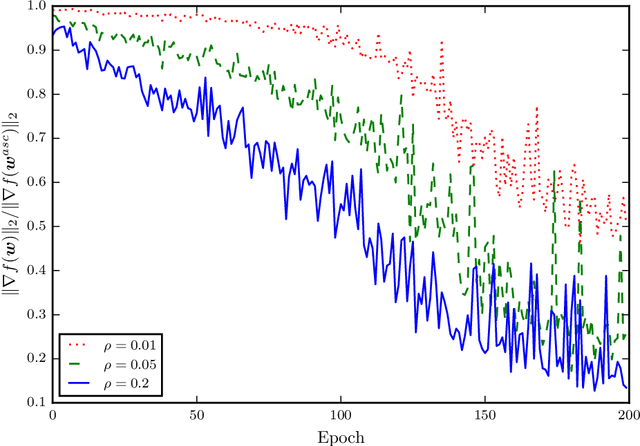
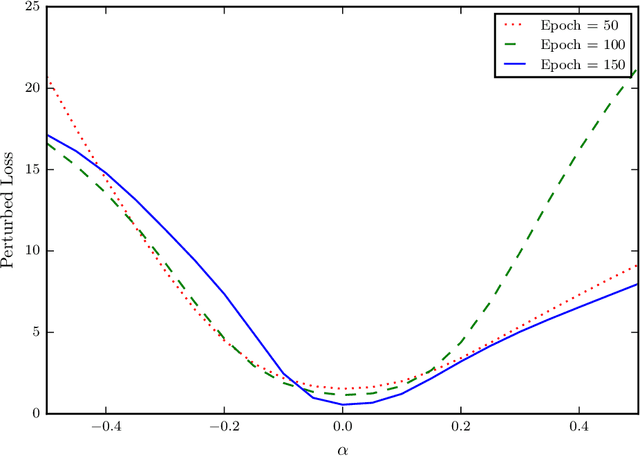
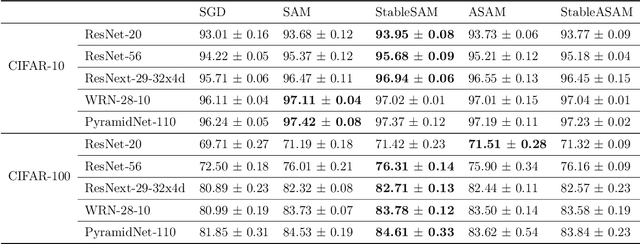
Recently, sharpness-aware minimization (SAM) has attracted a lot of attention because of its surprising effectiveness in improving generalization performance.However, training neural networks with SAM can be highly unstable since the loss does not decrease along the direction of the exact gradient at the current point, but instead follows the direction of a surrogate gradient evaluated at another point nearby. To address this issue, we propose a simple renormalization strategy, dubbed StableSAM, so that the norm of the surrogate gradient maintains the same as that of the exact gradient. Our strategy is easy to implement and flexible enough to integrate with SAM and its variants, almost at no computational cost. With elementary tools from convex optimization and learning theory, we also conduct a theoretical analysis of sharpness-aware training, revealing that compared to stochastic gradient descent (SGD), the effectiveness of SAM is only assured in a limited regime of learning rate. In contrast, we show how StableSAM extends this regime of learning rate and when it can consistently perform better than SAM with minor modification. Finally, we demonstrate the improved performance of StableSAM on several representative data sets and tasks.
Trajectory-dependent Generalization Bounds for Deep Neural Networks via Fractional Brownian Motion
Jun 09, 2022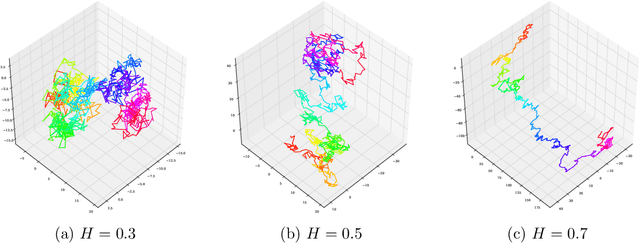
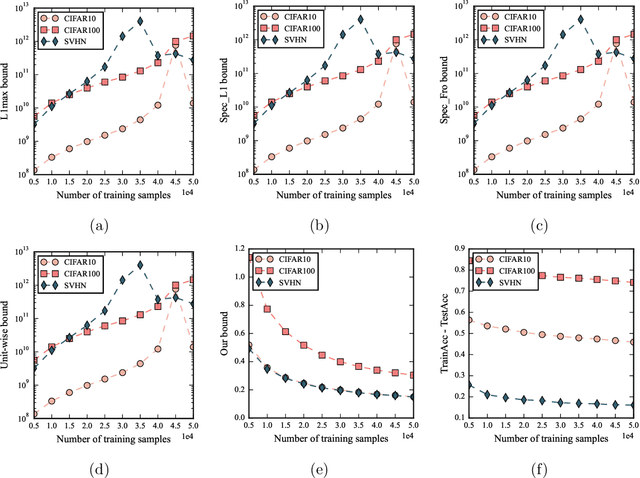
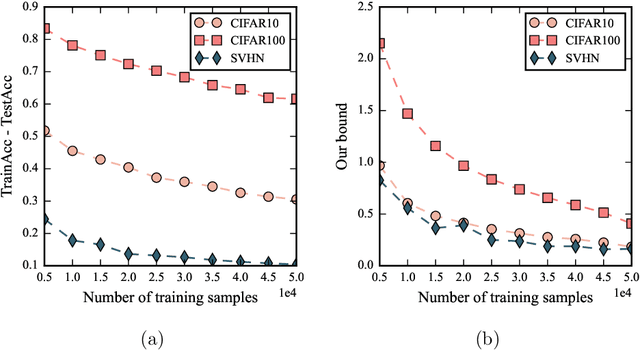
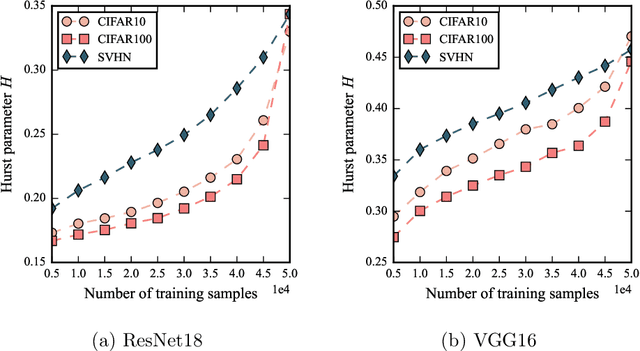
Despite being tremendously overparameterized, it is appreciated that deep neural networks trained by stochastic gradient descent (SGD) generalize surprisingly well. Based on the Rademacher complexity of a pre-specified hypothesis set, different norm-based generalization bounds have been developed to explain this phenomenon. However, recent studies suggest these bounds might be problematic as they increase with the training set size, which is contrary to empirical evidence. In this study, we argue that the hypothesis set SGD explores is trajectory-dependent and thus may provide a tighter bound over its Rademacher complexity. To this end, we characterize the SGD recursion via a stochastic differential equation by assuming the incurred stochastic gradient noise follows the fractional Brownian motion. We then identify the Rademacher complexity in terms of the covering numbers and relate it to the Hausdorff dimension of the optimization trajectory. By invoking the hypothesis set stability, we derive a novel generalization bound for deep neural networks. Extensive experiments demonstrate that it predicts well the generalization gap over several common experimental interventions. We further show that the Hurst parameter of the fractional Brownian motion is more informative than existing generalization indicators such as the power-law index and the upper Blumenthal-Getoor index.
Understanding Long Range Memory Effects in Deep Neural Networks
May 06, 2021
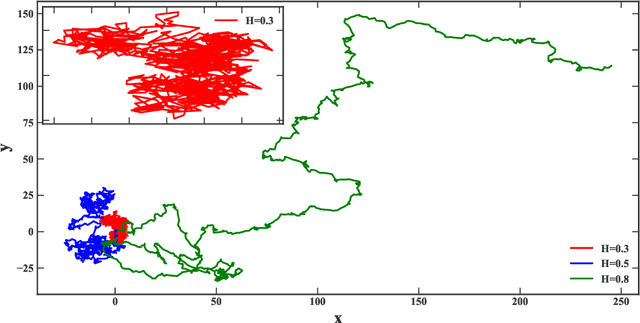
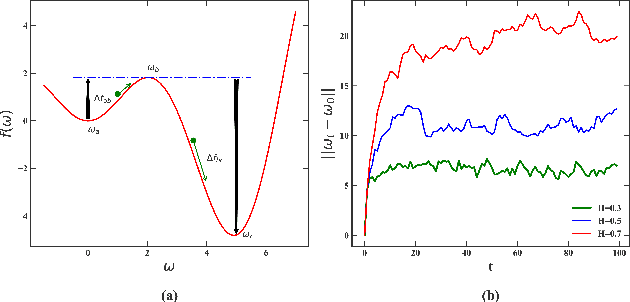
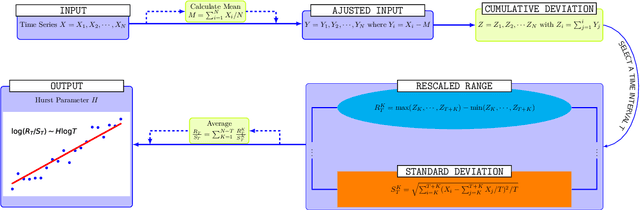
\textit{Stochastic gradient descent} (SGD) is of fundamental importance in deep learning. Despite its simplicity, elucidating its efficacy remains challenging. Conventionally, the success of SGD is attributed to the \textit{stochastic gradient noise} (SGN) incurred in the training process. Based on this general consensus, SGD is frequently treated and analyzed as the Euler-Maruyama discretization of a \textit{stochastic differential equation} (SDE) driven by either Brownian or L\'evy stable motion. In this study, we argue that SGN is neither Gaussian nor stable. Instead, inspired by the long-time correlation emerging in SGN series, we propose that SGD can be viewed as a discretization of an SDE driven by \textit{fractional Brownian motion} (FBM). Accordingly, the different convergence behavior of SGD dynamics is well grounded. Moreover, the first passage time of an SDE driven by FBM is approximately derived. This indicates a lower escaping rate for a larger Hurst parameter, and thus SGD stays longer in flat minima. This happens to coincide with the well-known phenomenon that SGD favors flat minima that generalize well. Four groups of experiments are conducted to validate our conjecture, and it is demonstrated that long-range memory effects persist across various model architectures, datasets, and training strategies. Our study opens up a new perspective and may contribute to a better understanding of SGD.
Discrete Cosine Transform Network for Guided Depth Map Super-Resolution
Apr 14, 2021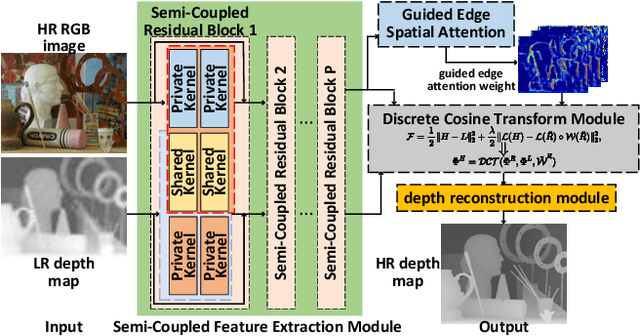
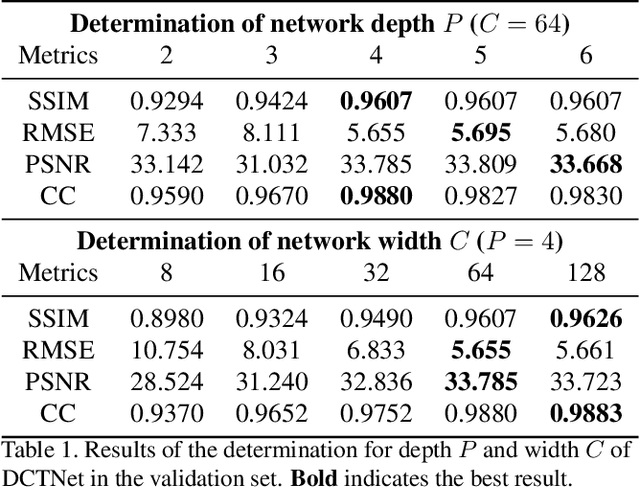
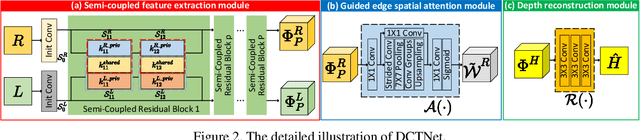
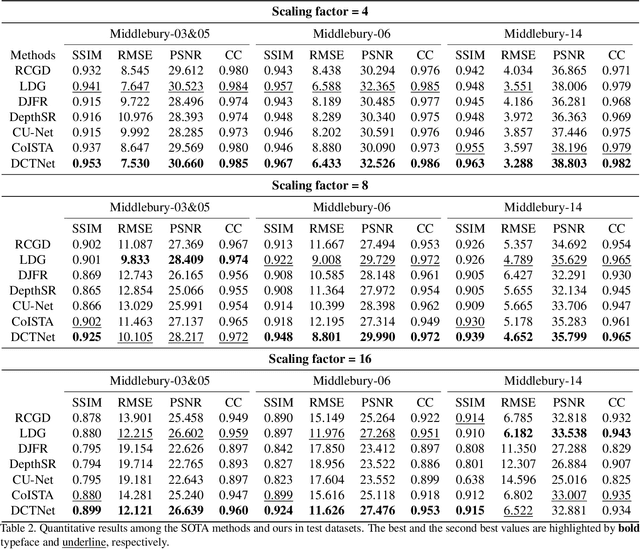
Guided depth super-resolution (GDSR) is a hot topic in multi-modal image processing. The goal is to use high-resolution (HR) RGB images to provide extra information on edges and object contours, so that low-resolution depth maps can be upsampled to HR ones. To solve the issues of RGB texture over-transferred, cross-modal feature extraction difficulty and unclear working mechanism of modules in existing methods, we propose an advanced Discrete Cosine Transform Network (DCTNet), which is composed of four components. Firstly, the paired RGB/depth images are input into the semi-coupled feature extraction module. The shared convolution kernels extract the cross-modal common features, and the private kernels extract their unique features, respectively. Then the RGB features are input into the edge attention mechanism to highlight the edges useful for upsampling. Subsequently, in the Discrete Cosine Transform (DCT) module, where DCT is employed to solve the optimization problem designed for image domain GDSR. The solution is then extended to implement the multi-channel RGB/depth features upsampling, which increases the rationality of DCTNet, and is more flexible and effective than conventional methods. The final depth prediction is output by the reconstruction module. Numerous qualitative and quantitative experiments demonstrate the effectiveness of our method, which can generate accurate and HR depth maps, surpassing state-of-the-art methods. Meanwhile, the rationality of modules is also proved by ablation experiments.
Deep Convolutional Sparse Coding Network for Pansharpening with Guidance of Side Information
Mar 10, 2021
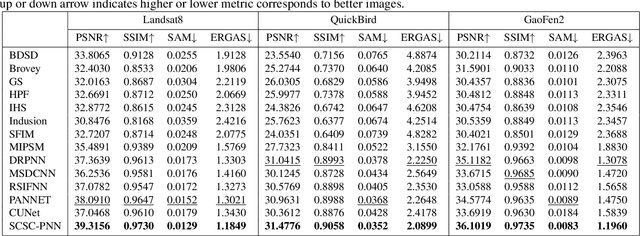
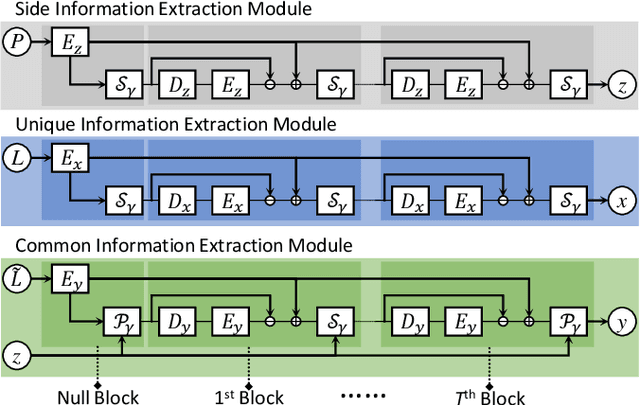
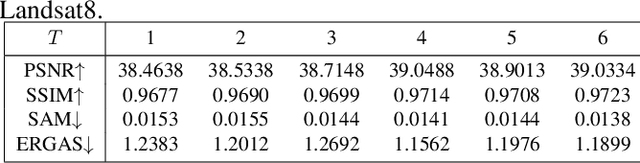
Pansharpening is a fundamental issue in remote sensing field. This paper proposes a side information partially guided convolutional sparse coding (SCSC) model for pansharpening. The key idea is to split the low resolution multispectral image into a panchromatic image related feature map and a panchromatic image irrelated feature map, where the former one is regularized by the side information from panchromatic images. With the principle of algorithm unrolling techniques, the proposed model is generalized as a deep neural network, called as SCSC pansharpening neural network (SCSC-PNN). Compared with 13 classic and state-of-the-art methods on three satellites, the numerical experiments show that SCSC-PNN is superior to others. The codes are available at https://github.com/xsxjtu/SCSC-PNN.
Deep Gradient Projection Networks for Pan-sharpening
Mar 08, 2021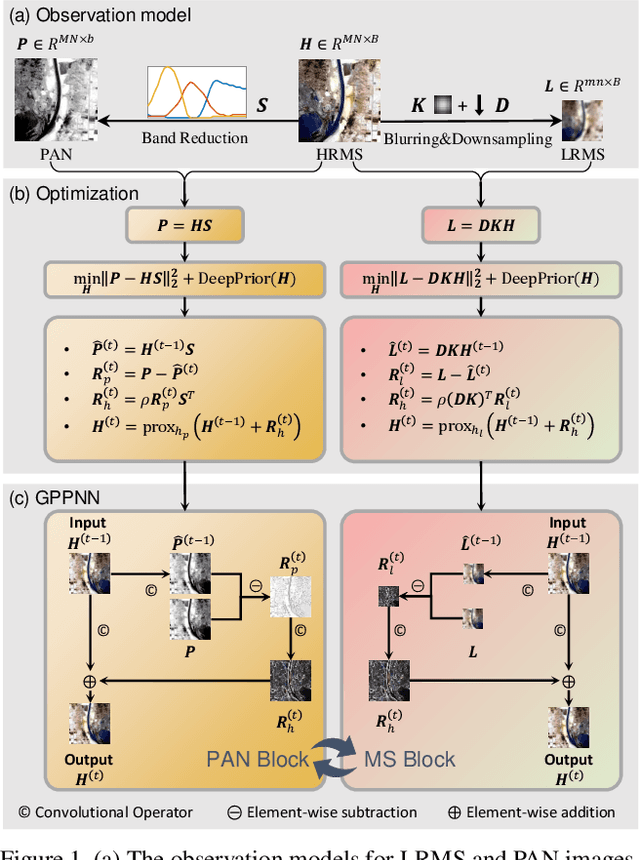
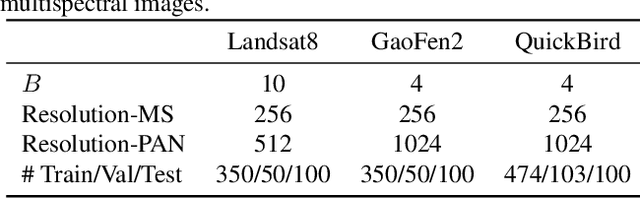
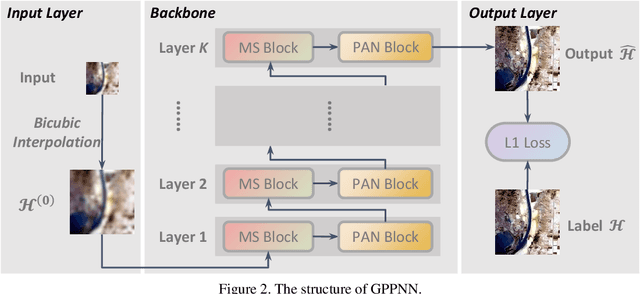
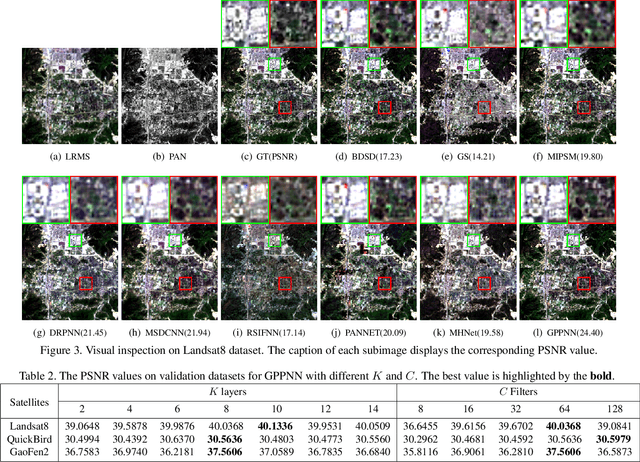
Pan-sharpening is an important technique for remote sensing imaging systems to obtain high resolution multispectral images. Recently, deep learning has become the most popular tool for pan-sharpening. This paper develops a model-based deep pan-sharpening approach. Specifically, two optimization problems regularized by the deep prior are formulated, and they are separately responsible for the generative models for panchromatic images and low resolution multispectral images. Then, the two problems are solved by a gradient projection algorithm, and the iterative steps are generalized into two network blocks. By alternatively stacking the two blocks, a novel network, called gradient projection based pan-sharpening neural network, is constructed. The experimental results on different kinds of satellite datasets demonstrate that the new network outperforms state-of-the-art methods both visually and quantitatively. The codes are available at https://github.com/xsxjtu/GPPNN.
FGF-GAN: A Lightweight Generative Adversarial Network for Pansharpening via Fast Guided Filter
Dec 31, 2020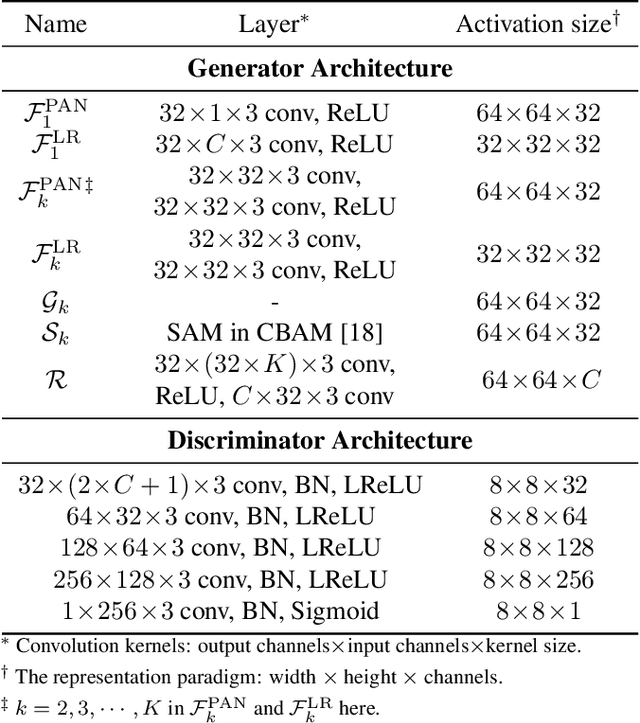
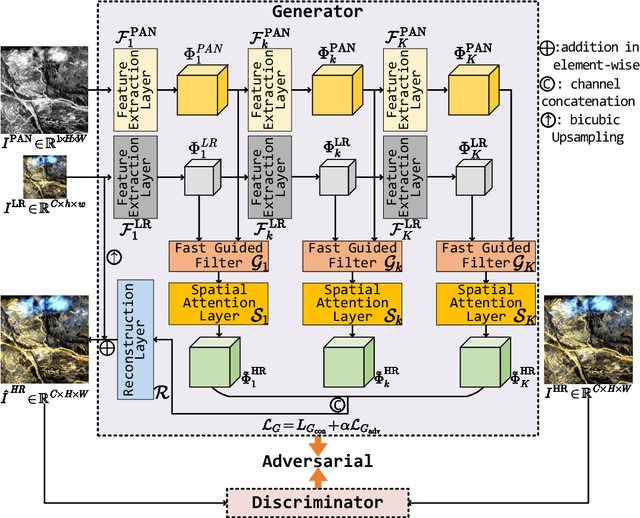
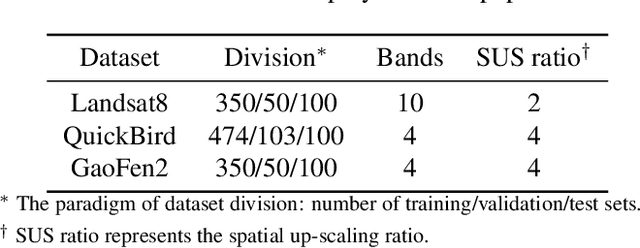

Pansharpening is a widely used image enhancement technique for remote sensing. Its principle is to fuse the input high-resolution single-channel panchromatic (PAN) image and low-resolution multi-spectral image and to obtain a high-resolution multi-spectral (HRMS) image. The existing deep learning pansharpening method has two shortcomings. First, features of two input images need to be concatenated along the channel dimension to reconstruct the HRMS image, which makes the importance of PAN images not prominent, and also leads to high computational cost. Second, the implicit information of features is difficult to extract through the manually designed loss function. To this end, we propose a generative adversarial network via the fast guided filter (FGF) for pansharpening. In generator, traditional channel concatenation is replaced by FGF to better retain the spatial information while reducing the number of parameters. Meanwhile, the fusion objects can be highlighted by the spatial attention module. In addition, the latent information of features can be preserved effectively through adversarial training. Numerous experiments illustrate that our network generates high-quality HRMS images that can surpass existing methods, and with fewer parameters.