 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Sharpness-aware Minimization Through A Simple Renormalization Strategy
Paper and Code
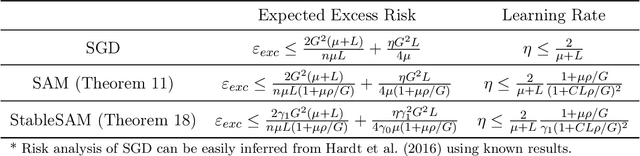
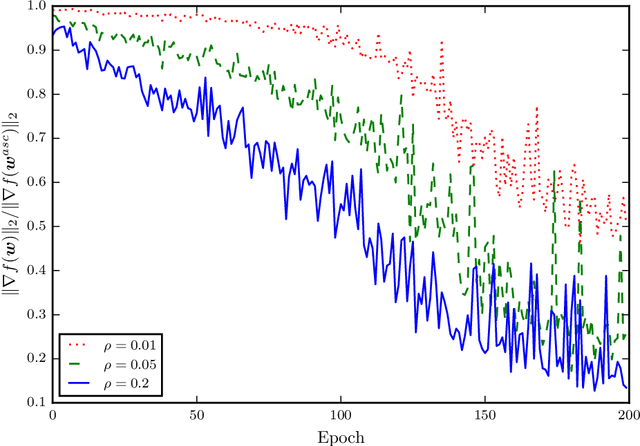
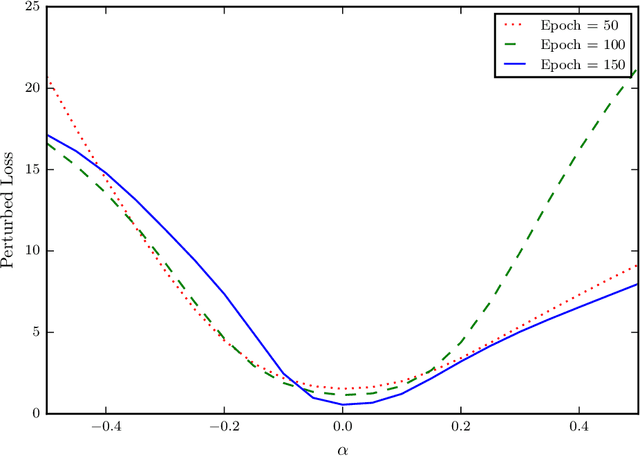
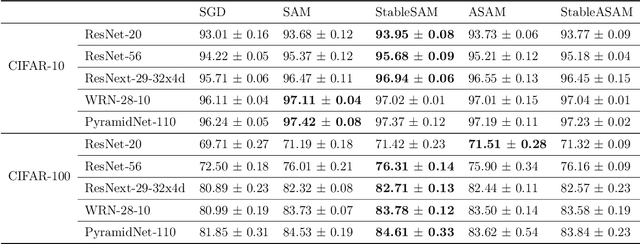
Recently, sharpness-aware minimization (SAM) has attracted a lot of attention because of its surprising effectiveness in improving generalization performance.However, training neural networks with SAM can be highly unstable since the loss does not decrease along the direction of the exact gradient at the current point, but instead follows the direction of a surrogate gradient evaluated at another point nearby. To address this issue, we propose a simple renormalization strategy, dubbed StableSAM, so that the norm of the surrogate gradient maintains the same as that of the exact gradient. Our strategy is easy to implement and flexible enough to integrate with SAM and its variants, almost at no computational cost. With elementary tools from convex optimization and learning theory, we also conduct a theoretical analysis of sharpness-aware training, revealing that compared to stochastic gradient descent (SGD), the effectiveness of SAM is only assured in a limited regime of learning rate. In contrast, we show how StableSAM extends this regime of learning rate and when it can consistently perform better than SAM with minor modification. Finally, we demonstrate the improved performance of StableSAM on several representative data sets and tasks.