 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding The Calibration Benefits of Sharpness-Aware Minimization
May 29, 2025Deep neural networks have been increasingly used in safety-critical applications such as medical diagnosis and autonomous driving. However, many studies suggest that they are prone to being poorly calibrated and have a propensity for overconfidence, which may have disastrous consequences. In this paper, unlike standard training such as stochastic gradient descent, we show that the recently proposed sharpness-aware minimization (SAM) counteracts this tendency towards overconfidence. The theoretical analysis suggests that SAM allows us to learn models that are already well-calibrated by implicitly maximizing the entropy of the predictive distribution. Inspired by this finding, we further propose a variant of SAM, coined as CSAM, to ameliorate model calibration. Extensive experiments on various datasets, including ImageNet-1K, demonstrate the benefits of SAM in reducing calibration error. Meanwhile, CSAM performs even better than SAM and consistently achieves lower calibration error than other approaches
Retinex-MEF: Retinex-based Glare Effects Aware Unsupervised Multi-Exposure Image Fusion
Mar 10, 2025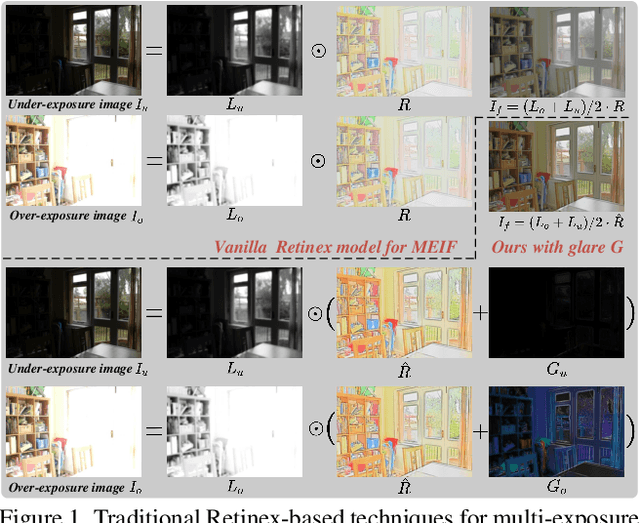
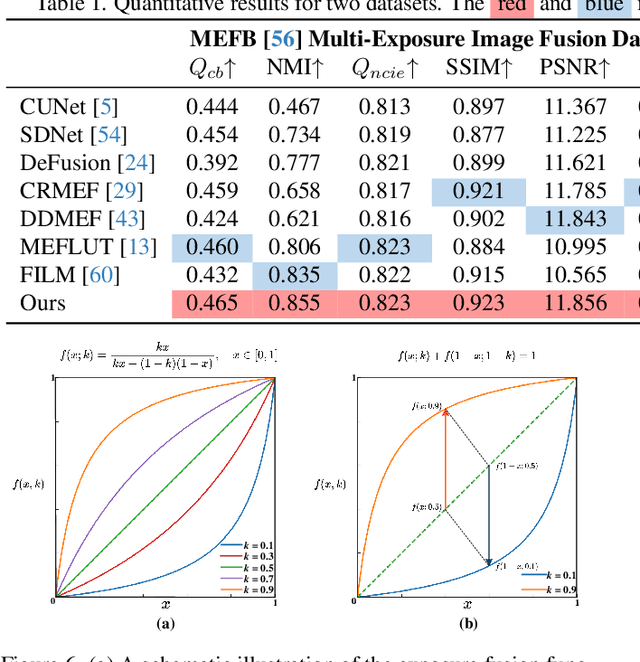
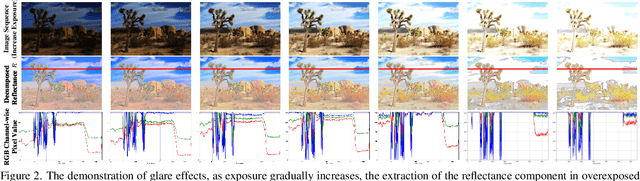
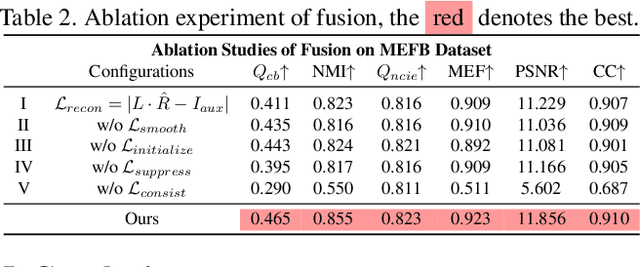
Multi-exposure image fusion consolidates multiple low dynamic range images of the same scene into a singular high dynamic range image. Retinex theory, which separates image illumination from scene reflectance, is naturally adopted to ensure consistent scene representation and effective information fusion across varied exposure levels. However, the conventional pixel-wise multiplication of illumination and reflectance inadequately models the glare effect induced by overexposure. To better adapt this theory for multi-exposure image fusion, we introduce an unsupervised and controllable method termed~\textbf{(Retinex-MEF)}. Specifically, our method decomposes multi-exposure images into separate illumination components and a shared reflectance component, and effectively modeling the glare induced by overexposure. Employing a bidirectional loss constraint to learn the common reflectance component, our approach effectively mitigates the glare effect. Furthermore, we establish a controllable exposure fusion criterion, enabling global exposure adjustments while preserving contrast, thus overcoming the constraints of fixed-level fusion. A series of experiments across multiple datasets, including underexposure-overexposure fusion, exposure control fusion, and homogeneous extreme exposure fusion, demonstrate the effective decomposition and flexible fusion capability of our model.
A Label-Free High-Precision Residual Moveout Picking Method for Travel Time Tomography based on Deep Learning
Mar 08, 2025Residual moveout (RMO) provides critical information for travel time tomography. The current industry-standard method for fitting RMO involves scanning high-order polynomial equations. However, this analytical approach does not accurately capture local saltation, leading to low iteration efficiency in tomographic inversion. Supervised learning-based image segmentation methods for picking can effectively capture local variations; however, they encounter challenges such as a scarcity of reliable training samples and the high complexity of post-processing. To address these issues, this study proposes a deep learning-based cascade picking method. It distinguishes accurate and robust RMOs using a segmentation network and a post-processing technique based on trend regression. Additionally, a data synthesis method is introduced, enabling the segmentation network to be trained on synthetic datasets for effective picking in field data. Furthermore, a set of metrics is proposed to quantify the quality of automatically picked RMOs. Experimental results based on both model and real data demonstrate that, compared to semblance-based methods, our approach achieves greater picking density and accuracy.
Deep Unfolding Multi-modal Image Fusion Network via Attribution Analysis
Feb 03, 2025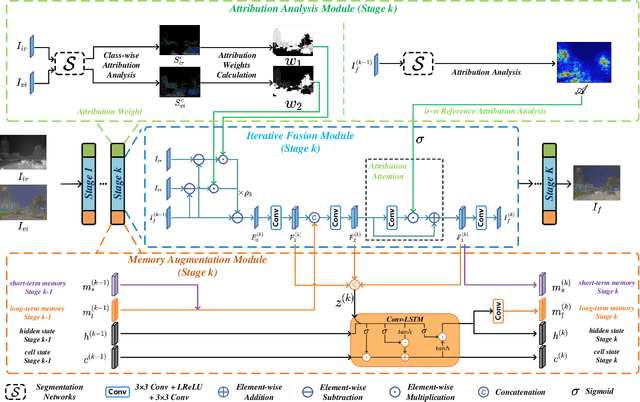

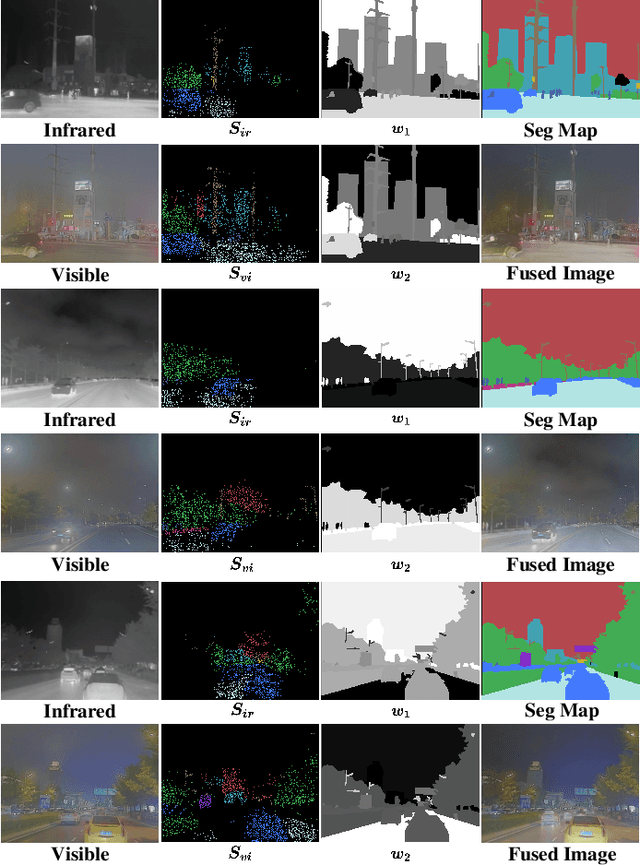
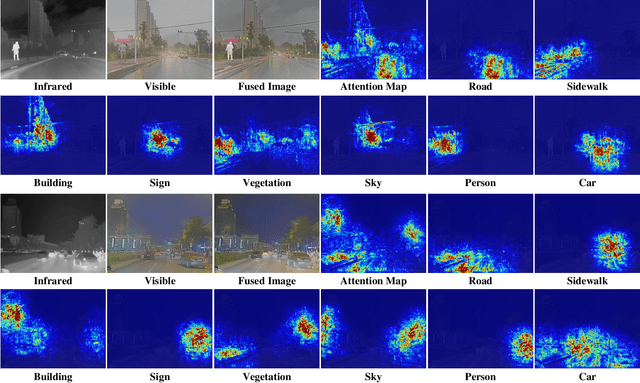
Multi-modal image fusion synthesizes information from multiple sources into a single image, facilitating downstream tasks such as semantic segmentation. Current approaches primarily focus on acquiring informative fusion images at the visual display stratum through intricate mappings. Although some approaches attempt to jointly optimize image fusion and downstream tasks, these efforts often lack direct guidance or interaction, serving only to assist with a predefined fusion loss. To address this, we propose an ``Unfolding Attribution Analysis Fusion network'' (UAAFusion), using attribution analysis to tailor fused images more effectively for semantic segmentation, enhancing the interaction between the fusion and segmentation. Specifically, we utilize attribution analysis techniques to explore the contributions of semantic regions in the source images to task discrimination. At the same time, our fusion algorithm incorporates more beneficial features from the source images, thereby allowing the segmentation to guide the fusion process. Our method constructs a model-driven unfolding network that uses optimization objectives derived from attribution analysis, with an attribution fusion loss calculated from the current state of the segmentation network. We also develop a new pathway function for attribution analysis, specifically tailored to the fusion tasks in our unfolding network. An attribution attention mechanism is integrated at each network stage, allowing the fusion network to prioritize areas and pixels crucial for high-level recognition tasks. Additionally, to mitigate the information loss in traditional unfolding networks, a memory augmentation module is incorporated into our network to improve the information flow across various network layers. Extensive experiments demonstrate our method's superiority in image fusion and applicability to semantic segmentation.
Simultaneous Automatic Picking and Manual Picking Refinement for First-Break
Feb 03, 2025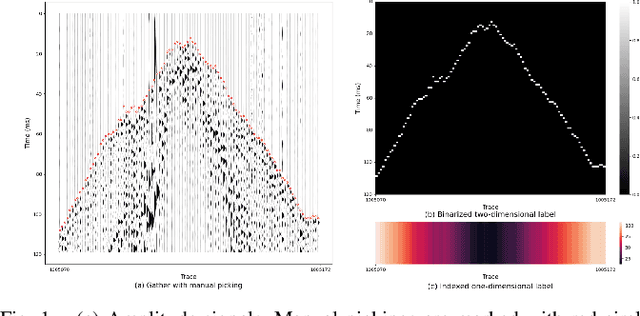
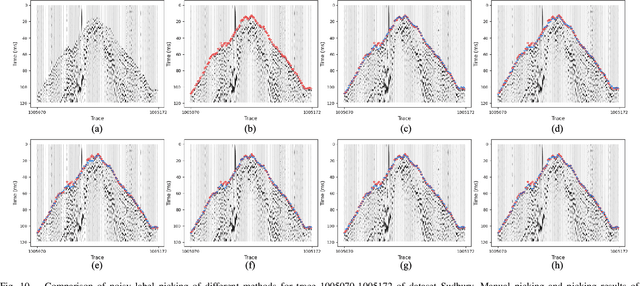
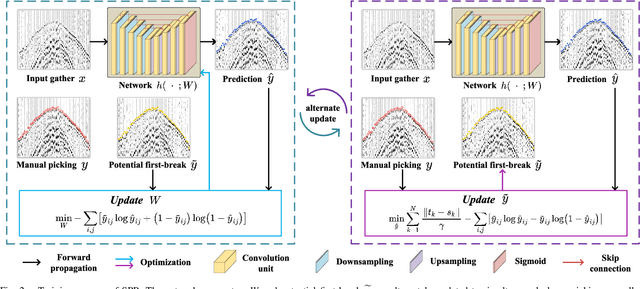
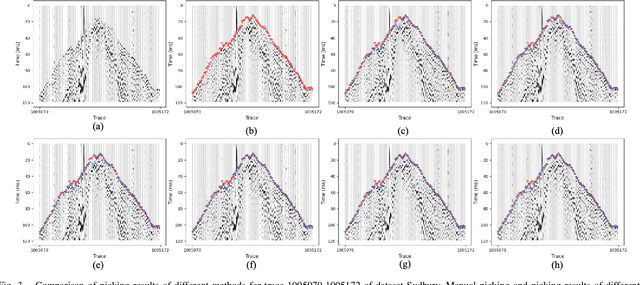
First-break picking is a pivotal procedure in processing microseismic data for geophysics and resource exploration. Recent advancements in deep learning have catalyzed the evolution of automated methods for identifying first-break. Nevertheless, the complexity of seismic data acquisition and the requirement for detailed, expert-driven labeling often result in outliers and potential mislabeling within manually labeled datasets. These issues can negatively affect the training of neural networks, necessitating algorithms that handle outliers or mislabeled data effectively. We introduce the Simultaneous Picking and Refinement (SPR) algorithm, designed to handle datasets plagued by outlier samples or even noisy labels. Unlike conventional approaches that regard manual picks as ground truth, our method treats the true first-break as a latent variable within a probabilistic model that includes a first-break labeling prior. SPR aims to uncover this variable, enabling dynamic adjustments and improved accuracy across the dataset. This strategy mitigates the impact of outliers or inaccuracies in manual labels. Intra-site picking experiments and cross-site generalization experiments on publicly available data confirm our method's performance in identifying first-break and its generalization across different sites. Additionally, our investigations into noisy signals and labels underscore SPR's resilience to both types of noise and its capability to refine misaligned manual annotations. Moreover, the flexibility of SPR, not being limited to any single network architecture, enhances its adaptability across various deep learning-based picking methods. Focusing on learning from data that may contain outliers or partial inaccuracies, SPR provides a robust solution to some of the principal obstacles in automatic first-break picking.
Task-driven Image Fusion with Learnable Fusion Loss
Dec 04, 2024Multi-modal image fusion aggregates information from multiple sensor sources, achieving superior visual quality and perceptual characteristics compared to any single source, often enhancing downstream tasks. However, current fusion methods for downstream tasks still use predefined fusion objectives that potentially mismatch the downstream tasks, limiting adaptive guidance and reducing model flexibility. To address this, we propose Task-driven Image Fusion (TDFusion), a fusion framework incorporating a learnable fusion loss guided by task loss. Specifically, our fusion loss includes learnable parameters modeled by a neural network called the loss generation module. This module is supervised by the loss of downstream tasks in a meta-learning manner. The learning objective is to minimize the task loss of the fused images, once the fusion module has been optimized by the fusion loss. Iterative updates between the fusion module and the loss module ensure that the fusion network evolves toward minimizing task loss, guiding the fusion process toward the task objectives. TDFusion's training relies solely on the loss of downstream tasks, making it adaptable to any specific task. It can be applied to any architecture of fusion and task networks. Experiments demonstrate TDFusion's performance in both fusion and task-related applications, including four public fusion datasets, semantic segmentation, and object detection. The code will be released.
Enhancing Sound Source Localization via False Negative Elimination
Aug 29, 2024



Sound source localization aims to localize objects emitting the sound in visual scenes. Recent works obtaining impressive results typically rely on contrastive learning. However, the common practice of randomly sampling negatives in prior arts can lead to the false negative issue, where the sounds semantically similar to visual instance are sampled as negatives and incorrectly pushed away from the visual anchor/query. As a result, this misalignment of audio and visual features could yield inferior performance. To address this issue, we propose a novel audio-visual learning framework which is instantiated with two individual learning schemes: self-supervised predictive learning (SSPL) and semantic-aware contrastive learning (SACL). SSPL explores image-audio positive pairs alone to discover semantically coherent similarities between audio and visual features, while a predictive coding module for feature alignment is introduced to facilitate the positive-only learning. In this regard SSPL acts as a negative-free method to eliminate false negatives. By contrast, SACL is designed to compact visual features and remove false negatives, providing reliable visual anchor and audio negatives for contrast. Different from SSPL, SACL releases the potential of audio-visual contrastive learning, offering an effective alternative to achieve the same goal. Comprehensive experiments demonstrate the superiority of our approach over the state-of-the-arts. Furthermore, we highlight the versatility of the learned representation by extending the approach to audio-visual event classification and object detection tasks. Code and models are available at: https://github.com/zjsong/SACL.
Seismic First Break Picking in a Higher Dimension Using Deep Graph Learning
Apr 12, 2024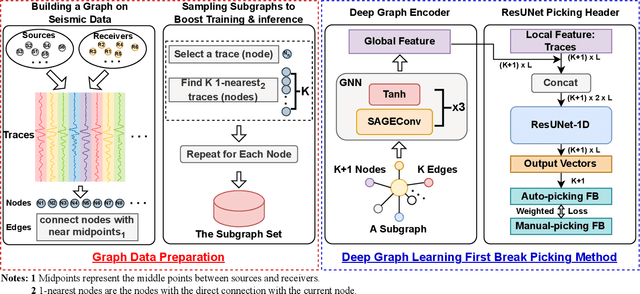
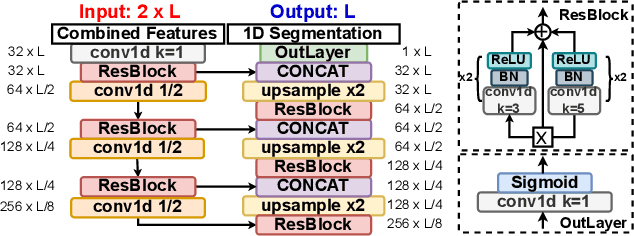
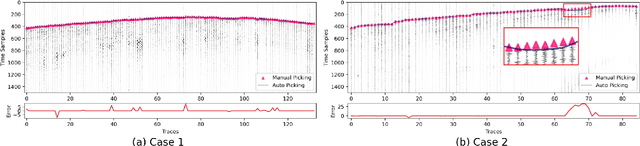
Contemporary automatic first break (FB) picking methods typically analyze 1D signals, 2D source gathers, or 3D source-receiver gathers. Utilizing higher-dimensional data, such as 2D or 3D, incorporates global features, improving the stability of local picking. Despite the benefits, high-dimensional data requires structured input and increases computational demands. Addressing this, we propose a novel approach using deep graph learning called DGL-FB, constructing a large graph to efficiently extract information. In this graph, each seismic trace is represented as a node, connected by edges that reflect similarities. To manage the size of the graph, we develop a subgraph sampling technique to streamline model training and inference. Our proposed framework, DGL-FB, leverages deep graph learning for FB picking. It encodes subgraphs into global features using a deep graph encoder. Subsequently, the encoded global features are combined with local node signals and fed into a ResUNet-based 1D segmentation network for FB detection. Field survey evaluations of DGL-FB show superior accuracy and stability compared to a 2D U-Net-based benchmark method.
Image Fusion via Vision-Language Model
Feb 03, 2024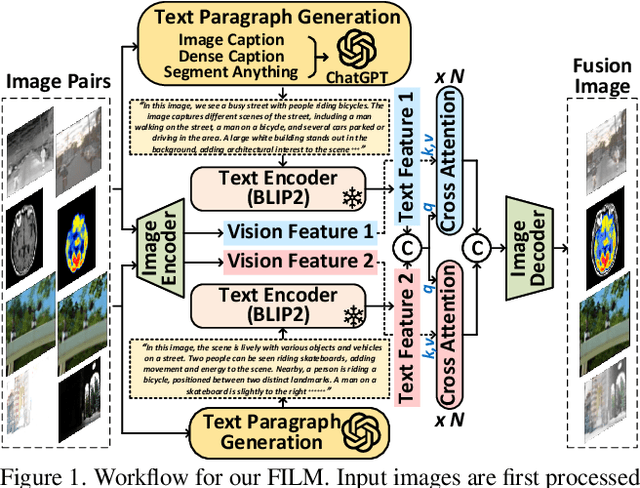
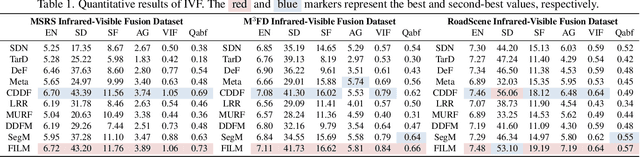
Image fusion integrates essential information from multiple source images into a single composite, emphasizing the highlighting structure and textures, and refining imperfect areas. Existing methods predominantly focus on pixel-level and semantic visual features for recognition. However, they insufficiently explore the deeper semantic information at a text-level beyond vision. Therefore, we introduce a novel fusion paradigm named image Fusion via vIsion-Language Model (FILM), for the first time, utilizing explicit textual information in different source images to guide image fusion. In FILM, input images are firstly processed to generate semantic prompts, which are then fed into ChatGPT to obtain rich textual descriptions. These descriptions are fused in the textual domain and guide the extraction of crucial visual features from the source images through cross-attention, resulting in a deeper level of contextual understanding directed by textual semantic information. The final fused image is created by vision feature decoder. This paradigm achieves satisfactory results in four image fusion tasks: infrared-visible, medical, multi-exposure, and multi-focus image fusion. We also propose a vision-language dataset containing ChatGPT-based paragraph descriptions for the ten image fusion datasets in four fusion tasks, facilitating future research in vision-language model-based image fusion. Code and dataset will be released.
Stabilizing Sharpness-aware Minimization Through A Simple Renormalization Strategy
Jan 14, 2024
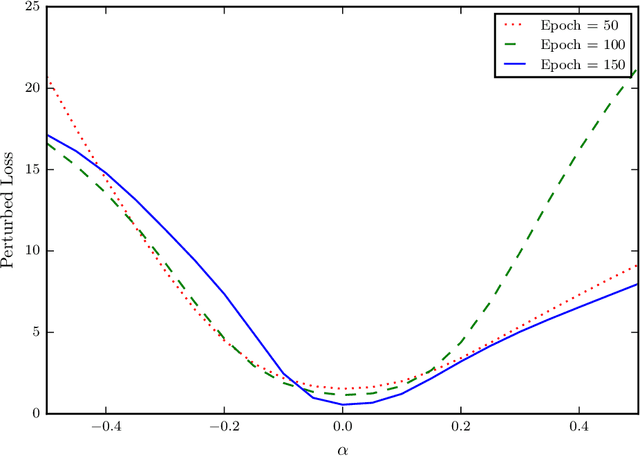
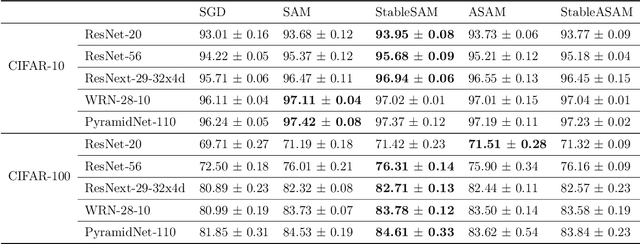
Recently, sharpness-aware minimization (SAM) has attracted a lot of attention because of its surprising effectiveness in improving generalization performance.However, training neural networks with SAM can be highly unstable since the loss does not decrease along the direction of the exact gradient at the current point, but instead follows the direction of a surrogate gradient evaluated at another point nearby. To address this issue, we propose a simple renormalization strategy, dubbed StableSAM, so that the norm of the surrogate gradient maintains the same as that of the exact gradient. Our strategy is easy to implement and flexible enough to integrate with SAM and its variants, almost at no computational cost. With elementary tools from convex optimization and learning theory, we also conduct a theoretical analysis of sharpness-aware training, revealing that compared to stochastic gradient descent (SGD), the effectiveness of SAM is only assured in a limited regime of learning rate. In contrast, we show how StableSAM extends this regime of learning rate and when it can consistently perform better than SAM with minor modification. Finally, we demonstrate the improved performance of StableSAM on several representative data sets and tasks.