 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Fusion via Vision-Language Model
Paper and Code
Feb 03, 2024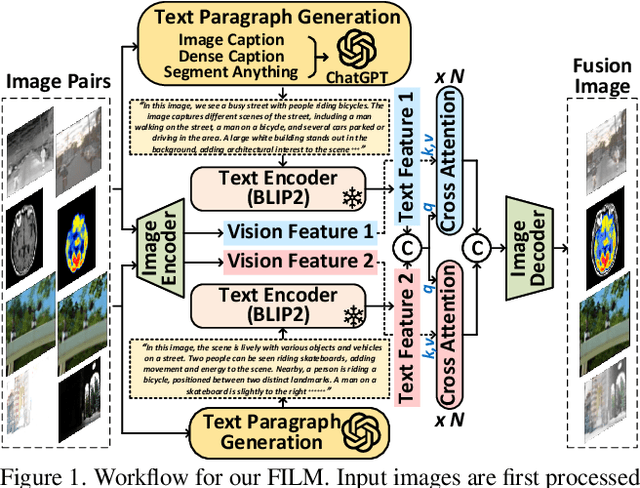
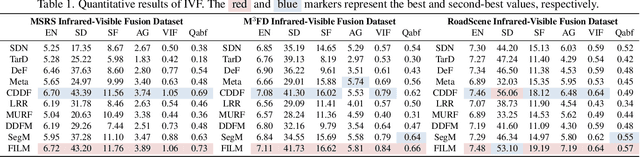
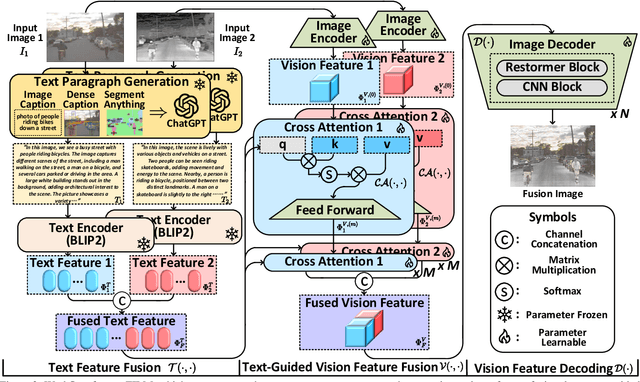
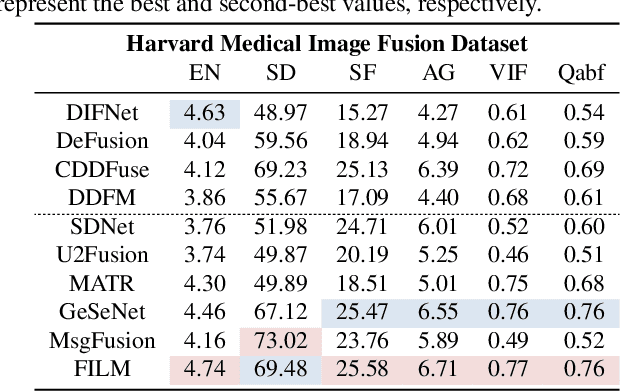
Image fusion integrates essential information from multiple source images into a single composite, emphasizing the highlighting structure and textures, and refining imperfect areas. Existing methods predominantly focus on pixel-level and semantic visual features for recognition. However, they insufficiently explore the deeper semantic information at a text-level beyond vision. Therefore, we introduce a novel fusion paradigm named image Fusion via vIsion-Language Model (FILM), for the first time, utilizing explicit textual information in different source images to guide image fusion. In FILM, input images are firstly processed to generate semantic prompts, which are then fed into ChatGPT to obtain rich textual descriptions. These descriptions are fused in the textual domain and guide the extraction of crucial visual features from the source images through cross-attention, resulting in a deeper level of contextual understanding directed by textual semantic information. The final fused image is created by vision feature decoder. This paradigm achieves satisfactory results in four image fusion tasks: infrared-visible, medical, multi-exposure, and multi-focus image fusion. We also propose a vision-language dataset containing ChatGPT-based paragraph descriptions for the ten image fusion datasets in four fusion tasks, facilitating future research in vision-language model-based image fusion. Code and dataset will be released.