 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of In-Context-Learning-Based Text-to-SQL Errors
Jan 16, 2025


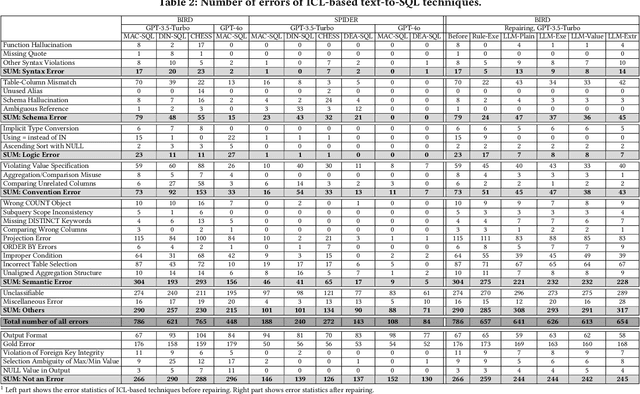
Large language models (LLMs) have been adopted to perform text-to-SQL tasks, utilizing their in-context learning (ICL) capability to translate natural language questions into structured query language (SQL). However, such a technique faces correctness problems and requires efficient repairing solutions. In this paper, we conduct the first comprehensive study of text-to-SQL errors. Our study covers four representative ICL-based techniques, five basic repairing methods, two benchmarks, and two LLM settings. We find that text-to-SQL errors are widespread and summarize 29 error types of 7 categories. We also find that existing repairing attempts have limited correctness improvement at the cost of high computational overhead with many mis-repairs. Based on the findings, we propose MapleRepair, a novel text-to-SQL error detection and repairing framework. The evaluation demonstrates that MapleRepair outperforms existing solutions by repairing 13.8% more queries with neglectable mis-repairs and 67.4% less overhead.
Double Variance Reduction: A Smoothing Trick for Composite Optimization Problems without First-Order Gradient
May 28, 2024

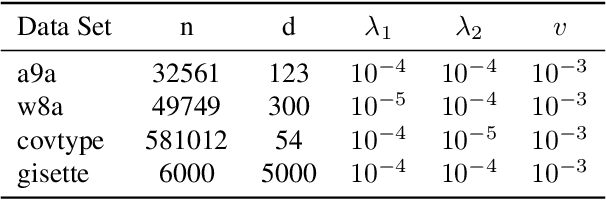
Variance reduction techniques are designed to decrease the sampling variance, thereby accelerating convergence rates of first-order (FO) and zeroth-order (ZO) optimization methods. However, in composite optimization problems, ZO methods encounter an additional variance called the coordinate-wise variance, which stems from the random gradient estimation. To reduce this variance, prior works require estimating all partial derivatives, essentially approximating FO information. This approach demands O(d) function evaluations (d is the dimension size), which incurs substantial computational costs and is prohibitive in high-dimensional scenarios. This paper proposes the Zeroth-order Proximal Double Variance Reduction (ZPDVR) method, which utilizes the averaging trick to reduce both sampling and coordinate-wise variances. Compared to prior methods, ZPDVR relies solely on random gradient estimates, calls the stochastic zeroth-order oracle (SZO) in expectation $\mathcal{O}(1)$ times per iteration, and achieves the optimal $\mathcal{O}(d(n + \kappa)\log (\frac{1}{\epsilon}))$ SZO query complexity in the strongly convex and smooth setting, where $\kappa$ represents the condition number and $\epsilon$ is the desired accuracy. Empirical results validate ZPDVR's linear convergence and demonstrate its superior performance over other related methods.
Towards Better Fairness-Utility Trade-off: A Comprehensive Measurement-Based Reinforcement Learning Framework
Jul 21, 2023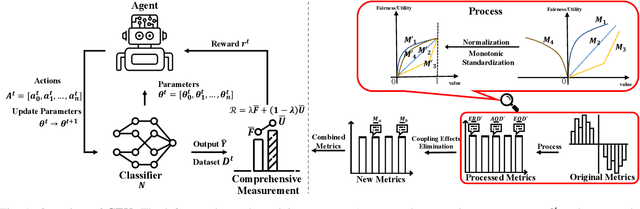
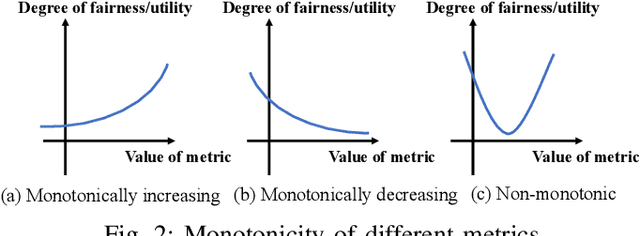
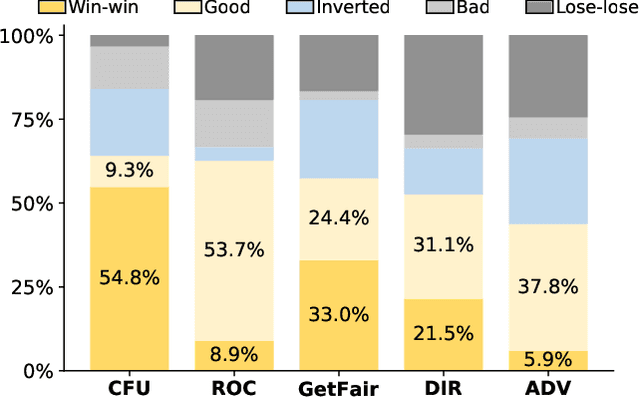
Machine learning is widely used to make decisions with societal impact such as bank loan approving, criminal sentencing, and resume filtering. How to ensure its fairness while maintaining utility is a challenging but crucial issue. Fairness is a complex and context-dependent concept with over 70 different measurement metrics. Since existing regulations are often vague in terms of which metric to use and different organizations may prefer different fairness metrics, it is important to have means of improving fairness comprehensively. Existing mitigation techniques often target at one specific fairness metric and have limitations in improving multiple notions of fairness simultaneously. In this work, we propose CFU (Comprehensive Fairness-Utility), a reinforcement learning-based framework, to efficiently improve the fairness-utility trade-off in machine learning classifiers. A comprehensive measurement that can simultaneously consider multiple fairness notions as well as utility is established, and new metrics are proposed based on an in-depth analysis of the relationship between different fairness metrics. The reward function of CFU is constructed with comprehensive measurement and new metrics. We conduct extensive experiments to evaluate CFU on 6 tasks, 3 machine learning models, and 15 fairness-utility measurements. The results demonstrate that CFU can improve the classifier on multiple fairness metrics without sacrificing its utility. It outperforms all state-of-the-art techniques and has witnessed a 37.5% improvement on average.
Boosting Verified Training for Robust Image Classifications via Abstraction
Mar 21, 2023



This paper proposes a novel, abstraction-based, certified training method for robust image classifiers. Via abstraction, all perturbed images are mapped into intervals before feeding into neural networks for training. By training on intervals, all the perturbed images that are mapped to the same interval are classified as the same label, rendering the variance of training sets to be small and the loss landscape of the models to be smooth. Consequently, our approach significantly improves the robustness of trained models. For the abstraction, our training method also enables a sound and complete black-box verification approach, which is orthogonal and scalable to arbitrary types of neural networks regardless of their sizes and architectures. We evaluate our method on a wide range of benchmarks in different scales. The experimental results show that our method outperforms state of the art by (i) reducing the verified errors of trained models up to 95.64%; (ii) totally achieving up to 602.50x speedup; and (iii) scaling up to larger models with up to 138 million trainable parameters. The demo is available at https://github.com/zhangzhaodi233/ABSCERT.git.
OccRob: Efficient SMT-Based Occlusion Robustness Verification of Deep Neural Networks
Jan 27, 2023



Occlusion is a prevalent and easily realizable semantic perturbation to deep neural networks (DNNs). It can fool a DNN into misclassifying an input image by occluding some segments, possibly resulting in severe errors. Therefore, DNNs planted in safety-critical systems should be verified to be robust against occlusions prior to deployment. However, most existing robustness verification approaches for DNNs are focused on non-semantic perturbations and are not suited to the occlusion case. In this paper, we propose the first efficient, SMT-based approach for formally verifying the occlusion robustness of DNNs. We formulate the occlusion robustness verification problem and prove it is NP-complete. Then, we devise a novel approach for encoding occlusions as a part of neural networks and introduce two acceleration techniques so that the extended neural networks can be efficiently verified using off-the-shelf, SMT-based neural network verification tools. We implement our approach in a prototype called OccRob and extensively evaluate its performance on benchmark datasets with various occlusion variants. The experimental results demonstrate our approach's effectiveness and efficiency in verifying DNNs' robustness against various occlusions, and its ability to generate counterexamples when these DNNs are not robust.
AI-enabled Automatic Multimodal Fusion of Cone-Beam CT and Intraoral Scans for Intelligent 3D Tooth-Bone Reconstruction and Clinical Applications
Mar 11, 2022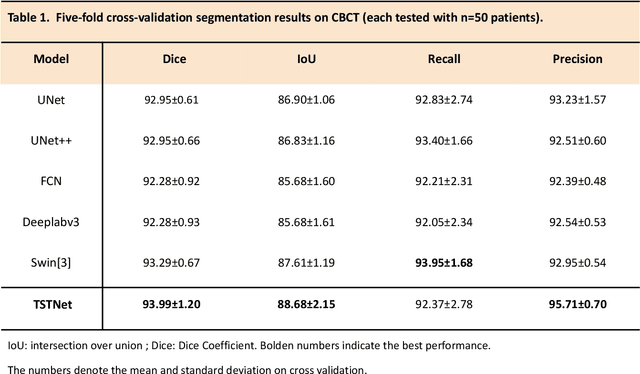
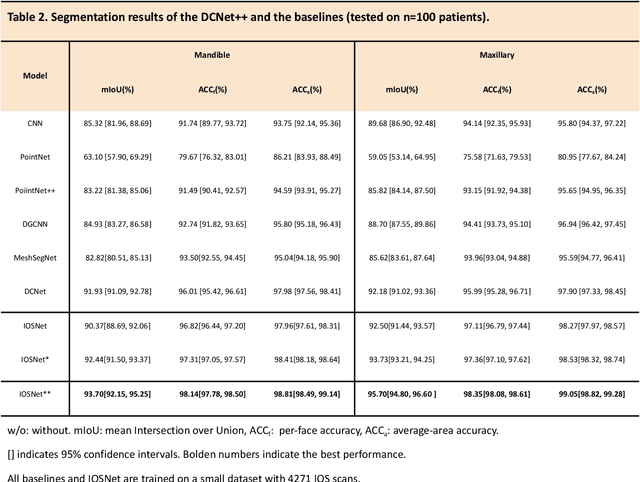

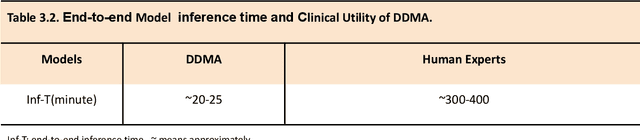
A critical step in virtual dental treatment planning is to accurately delineate all tooth-bone structures from CBCT with high fidelity and accurate anatomical information. Previous studies have established several methods for CBCT segmentation using deep learning. However, the inherent resolution discrepancy of CBCT and the loss of occlusal and dentition information largely limited its clinical applicability. Here, we present a Deep Dental Multimodal Analysis (DDMA) framework consisting of a CBCT segmentation model, an intraoral scan (IOS) segmentation model (the most accurate digital dental model), and a fusion model to generate 3D fused crown-root-bone structures with high fidelity and accurate occlusal and dentition information. Our model was trained with a large-scale dataset with 503 CBCT and 28,559 IOS meshes manually annotated by experienced human experts. For CBCT segmentation, we use a five-fold cross validation test, each with 50 CBCT, and our model achieves an average Dice coefficient and IoU of 93.99% and 88.68%, respectively, significantly outperforming the baselines. For IOS segmentations, our model achieves an mIoU of 93.07% and 95.70% on the maxillary and mandible on a test set of 200 IOS meshes, which are 1.77% and 3.52% higher than the state-of-art method. Our DDMA framework takes about 20 to 25 minutes to generate the fused 3D mesh model following the sequential processing order, compared to over 5 hours by human experts. Notably, our framework has been incorporated into a software by a clear aligner manufacturer, and real-world clinical cases demonstrate that our model can visualize crown-root-bone structures during the entire orthodontic treatment and can predict risks like dehiscence and fenestration. These findings demonstrate the potential of multi-modal deep learning to improve the quality of digital dental models and help dentists make better clinical decisions.