 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVGen-Bench: A Task-Driven Benchmark for Multi-Granular Evaluation of Text-to-Audio-Video Generation
Apr 09, 2026Text-to-Audio-Video (T2AV) generation is rapidly becoming a core interface for media creation, yet its evaluation remains fragmented. Existing benchmarks largely assess audio and video in isolation or rely on coarse embedding similarity, failing to capture the fine-grained joint correctness required by realistic prompts. We introduce AVGen-Bench, a task-driven benchmark for T2AV generation featuring high-quality prompts across 11 real-world categories. To support comprehensive assessment, we propose a multi-granular evaluation framework that combines lightweight specialist models with Multimodal Large Language Models (MLLMs), enabling evaluation from perceptual quality to fine-grained semantic controllability. Our evaluation reveals a pronounced gap between strong audio-visual aesthetics and weak semantic reliability, including persistent failures in text rendering, speech coherence, physical reasoning, and a universal breakdown in musical pitch control. Code and benchmark resources are available at http://aka.ms/avgenbench.
BizGenEval: A Systematic Benchmark for Commercial Visual Content Generation
Mar 26, 2026Recent advances in image generation models have expanded their applications beyond aesthetic imagery toward practical visual content creation. However, existing benchmarks mainly focus on natural image synthesis and fail to systematically evaluate models under the structured and multi-constraint requirements of real-world commercial design tasks. In this work, we introduce BizGenEval, a systematic benchmark for commercial visual content generation. The benchmark spans five representative document types: slides, charts, webpages, posters, and scientific figures, and evaluates four key capability dimensions: text rendering, layout control, attribute binding, and knowledge-based reasoning, forming 20 diverse evaluation tasks. BizGenEval contains 400 carefully curated prompts and 8000 human-verified checklist questions to rigorously assess whether generated images satisfy complex visual and semantic constraints. We conduct large-scale benchmarking on 26 popular image generation systems, including state-of-the-art commercial APIs and leading open-source models. The results reveal substantial capability gaps between current generative models and the requirements of professional visual content creation. We hope BizGenEval serves as a standardized benchmark for real-world commercial visual content generation.
Daily-Omni: Towards Audio-Visual Reasoning with Temporal Alignment across Modalities
May 23, 2025Recent Multimodal Large Language Models (MLLMs) achieve promising performance on visual and audio benchmarks independently. However, the ability of these models to process cross-modal information synchronously remains largely unexplored. In this paper, we introduce: 1) Daily-Omni, an Audio-Visual Questioning and Answering benchmark comprising 684 videos of daily life scenarios from diverse sources, rich in both audio and visual information, and featuring 1197 multiple-choice QA pairs across 6 major tasks; 2) Daily-Omni QA Generation Pipeline, which includes automatic annotation, QA generation and QA optimization, significantly improves efficiency for human evaluation and scalability of the benchmark; 3) Daily-Omni-Agent, a training-free agent utilizing open-source Visual Language Model (VLM), Audio Language Model (ALM) and Automatic Speech Recognition (ASR) model to establish a baseline for this benchmark. The results show that current MLLMs still struggle significantly with tasks requiring audio-visual integration, but combining VLMs and ALMs with simple temporal alignment techniques can achieve substantially better performance. Codes and benchmark are available at \href{https://github.com/Lliar-liar/Daily-Omni}{https://github.com/Lliar-liar/Daily-Omni}.
OccRob: Efficient SMT-Based Occlusion Robustness Verification of Deep Neural Networks
Jan 27, 2023



Occlusion is a prevalent and easily realizable semantic perturbation to deep neural networks (DNNs). It can fool a DNN into misclassifying an input image by occluding some segments, possibly resulting in severe errors. Therefore, DNNs planted in safety-critical systems should be verified to be robust against occlusions prior to deployment. However, most existing robustness verification approaches for DNNs are focused on non-semantic perturbations and are not suited to the occlusion case. In this paper, we propose the first efficient, SMT-based approach for formally verifying the occlusion robustness of DNNs. We formulate the occlusion robustness verification problem and prove it is NP-complete. Then, we devise a novel approach for encoding occlusions as a part of neural networks and introduce two acceleration techniques so that the extended neural networks can be efficiently verified using off-the-shelf, SMT-based neural network verification tools. We implement our approach in a prototype called OccRob and extensively evaluate its performance on benchmark datasets with various occlusion variants. The experimental results demonstrate our approach's effectiveness and efficiency in verifying DNNs' robustness against various occlusions, and its ability to generate counterexamples when these DNNs are not robust.
The Relevance of Text and Speech Features in Automatic Non-native English Accent Identification
Apr 16, 2018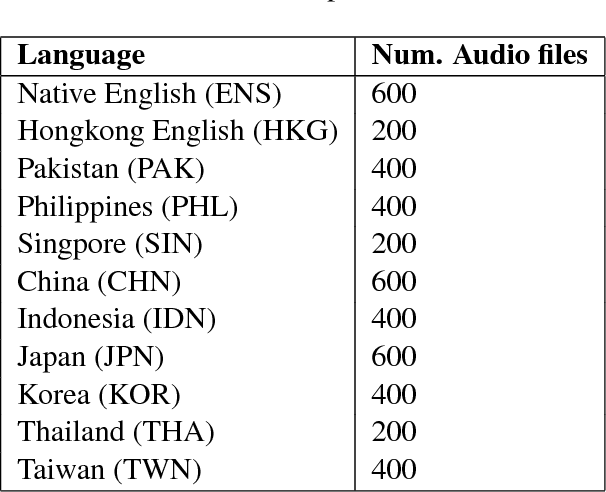
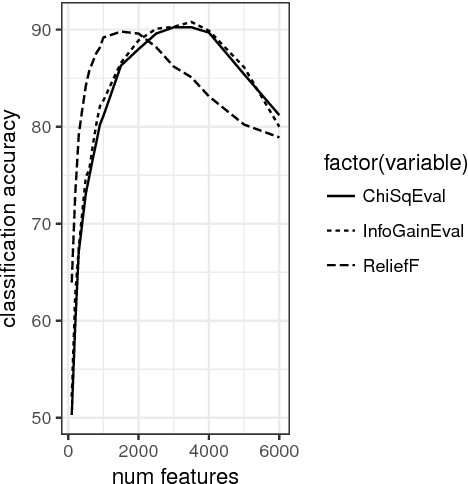
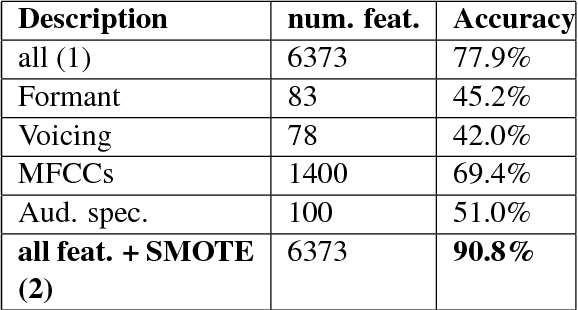
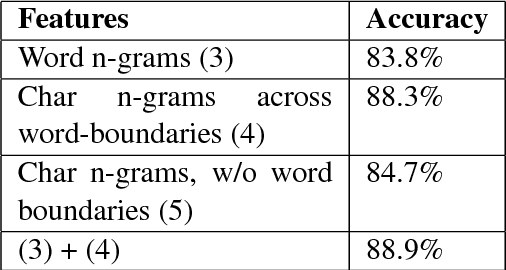
This paper describes our experiments with automatically identifying native accents from speech samples of non-native English speakers using low level audio features, and n-gram features from manual transcriptions. Using a publicly available non-native speech corpus and simple audio feature representations that do not perform word/phoneme recognition, we show that it is possible to achieve close to 90% classification accuracy for this task. While character n-grams perform similar to speech features, we show that speech features are not affected by prompt variation, whereas ngrams are. Since the approach followed can be easily adapted to any language provided we have enough training data, we believe these results will provide useful insights for the development of accent recognition systems and for the study of accents in the context of language learning.