 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Relevance of Text and Speech Features in Automatic Non-native English Accent Identification
Paper and Code
Apr 16, 2018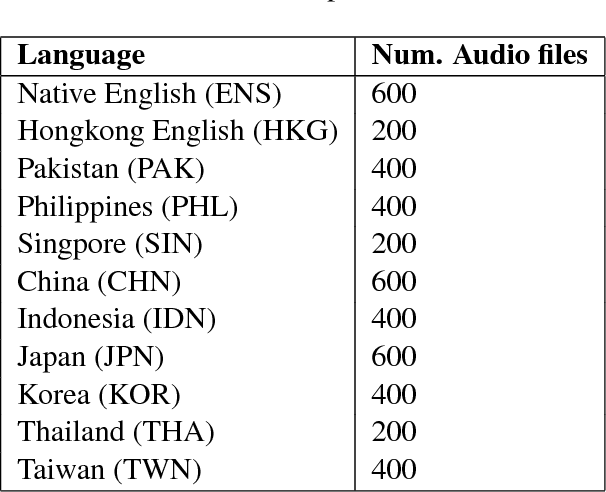
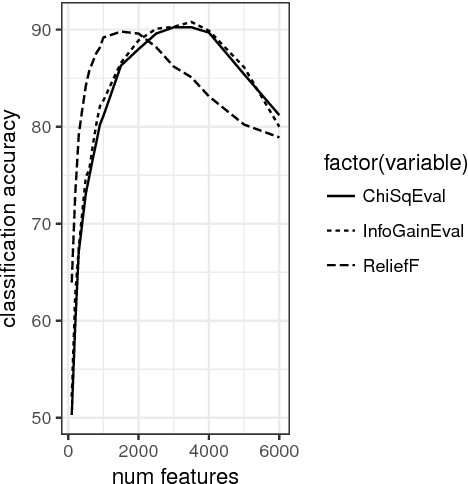
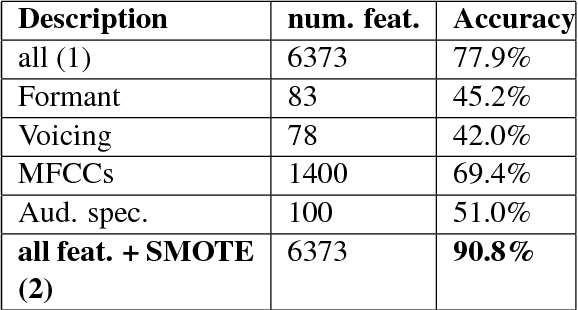
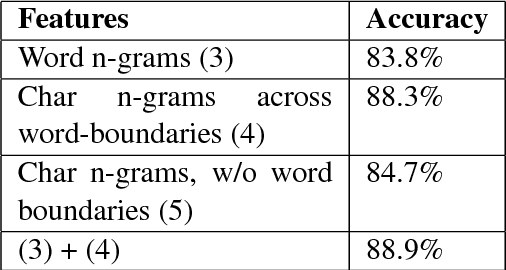
This paper describes our experiments with automatically identifying native accents from speech samples of non-native English speakers using low level audio features, and n-gram features from manual transcriptions. Using a publicly available non-native speech corpus and simple audio feature representations that do not perform word/phoneme recognition, we show that it is possible to achieve close to 90% classification accuracy for this task. While character n-grams perform similar to speech features, we show that speech features are not affected by prompt variation, whereas ngrams are. Since the approach followed can be easily adapted to any language provided we have enough training data, we believe these results will provide useful insights for the development of accent recognition systems and for the study of accents in the context of language learning.