 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToothSegNet: Image Degradation meets Tooth Segmentation in CBCT Images
Jul 05, 2023In computer-assisted orthodontics, three-dimensional tooth models are required for many medical treatments. Tooth segmentation from cone-beam computed tomography (CBCT) images is a crucial step in constructing the models. However, CBCT image quality problems such as metal artifacts and blurring caused by shooting equipment and patients' dental conditions make the segmentation difficult. In this paper, we propose ToothSegNet, a new framework which acquaints the segmentation model with generated degraded images during training. ToothSegNet merges the information of high and low quality images from the designed degradation simulation module using channel-wise cross fusion to reduce the semantic gap between encoder and decoder, and also refines the shape of tooth prediction through a structural constraint loss. Experimental results suggest that ToothSegNet produces more precise segmentation and outperforms the state-of-the-art medical image segmentation methods.
AI-enabled Automatic Multimodal Fusion of Cone-Beam CT and Intraoral Scans for Intelligent 3D Tooth-Bone Reconstruction and Clinical Applications
Mar 11, 2022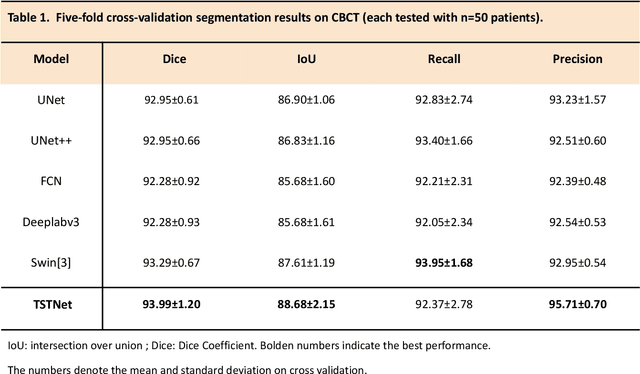
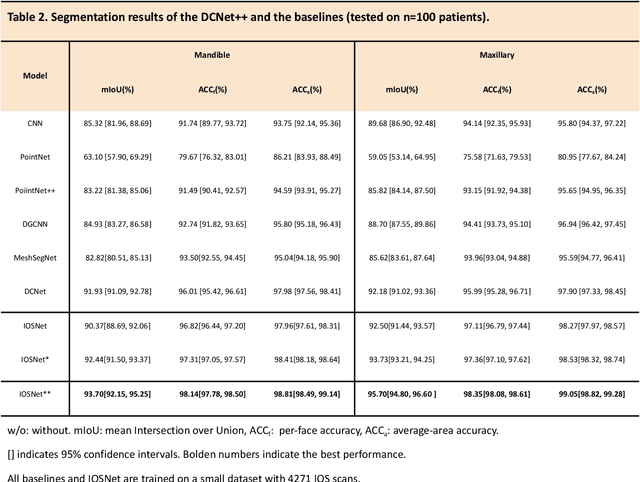

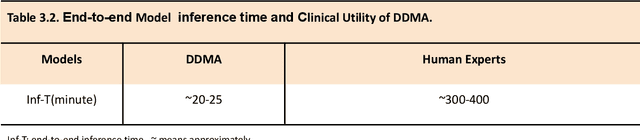
A critical step in virtual dental treatment planning is to accurately delineate all tooth-bone structures from CBCT with high fidelity and accurate anatomical information. Previous studies have established several methods for CBCT segmentation using deep learning. However, the inherent resolution discrepancy of CBCT and the loss of occlusal and dentition information largely limited its clinical applicability. Here, we present a Deep Dental Multimodal Analysis (DDMA) framework consisting of a CBCT segmentation model, an intraoral scan (IOS) segmentation model (the most accurate digital dental model), and a fusion model to generate 3D fused crown-root-bone structures with high fidelity and accurate occlusal and dentition information. Our model was trained with a large-scale dataset with 503 CBCT and 28,559 IOS meshes manually annotated by experienced human experts. For CBCT segmentation, we use a five-fold cross validation test, each with 50 CBCT, and our model achieves an average Dice coefficient and IoU of 93.99% and 88.68%, respectively, significantly outperforming the baselines. For IOS segmentations, our model achieves an mIoU of 93.07% and 95.70% on the maxillary and mandible on a test set of 200 IOS meshes, which are 1.77% and 3.52% higher than the state-of-art method. Our DDMA framework takes about 20 to 25 minutes to generate the fused 3D mesh model following the sequential processing order, compared to over 5 hours by human experts. Notably, our framework has been incorporated into a software by a clear aligner manufacturer, and real-world clinical cases demonstrate that our model can visualize crown-root-bone structures during the entire orthodontic treatment and can predict risks like dehiscence and fenestration. These findings demonstrate the potential of multi-modal deep learning to improve the quality of digital dental models and help dentists make better clinical decisions.