 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIOSVLM: A 3D Vision-Language Model for Unified Dental Diagnosis from Intraoral Scans
Mar 17, 20263D intraoral scans (IOS) are increasingly adopted in routine dentistry due to abundant geometric evidence, and unified multi-disease diagnosis is desirable for clinical documentation and communication. While recent works introduce dental vision-language models (VLMs) to enable unified diagnosis and report generation on 2D images or multi-view images rendered from IOS, they do not fully leverage native 3D geometry. Such work is necessary and also challenging, due to: (i) heterogeneous scan forms and the complex IOS topology, (ii) multi-disease co-occurrence with class imbalance and fine-grained morphological ambiguity, (iii) limited paired 3D IOS-text data. Thus, we present IOSVLM, an end-to-end 3D VLM that represents scans as point clouds and follows a 3D encoder-projector-LLM design for unified diagnosis and generative visual question-answering (VQA), together with IOSVQA, a large-scale multi-source IOS diagnosis VQA dataset comprising 19,002 cases and 249,055 VQA pairs over 23 oral diseases and heterogeneous scan types. To address the distribution gap between color-free IOS data and color-dependent 3D pre-training, we propose a geometry-to-chromatic proxy that stabilizes fine-grained geometric perception and cross-modal alignment. A two-stage curriculum training strategy further enhances robustness. IOSVLM consistently outperforms strong baselines, achieving gains of at least +9.58% macro accuracy and +1.46% macro F1, indicating the effectiveness of direct 3D geometry modeling for IOS-based diagnosis.
TSegFormer: 3D Tooth Segmentation in Intraoral Scans with Geometry Guided Transformer
Nov 22, 2023Optical Intraoral Scanners (IOS) are widely used in digital dentistry to provide detailed 3D information of dental crowns and the gingiva. Accurate 3D tooth segmentation in IOSs is critical for various dental applications, while previous methods are error-prone at complicated boundaries and exhibit unsatisfactory results across patients. In this paper, we propose TSegFormer which captures both local and global dependencies among different teeth and the gingiva in the IOS point clouds with a multi-task 3D transformer architecture. Moreover, we design a geometry-guided loss based on a novel point curvature to refine boundaries in an end-to-end manner, avoiding time-consuming post-processing to reach clinically applicable segmentation. In addition, we create a dataset with 16,000 IOSs, the largest ever IOS dataset to the best of our knowledge. The experimental results demonstrate that our TSegFormer consistently surpasses existing state-of-the-art baselines. The superiority of TSegFormer is corroborated by extensive analysis, visualizations and real-world clinical applicability tests. Our code is available at https://github.com/huiminxiong/TSegFormer.
Fast Model Debias with Machine Unlearning
Nov 03, 2023Recent discoveries have revealed that deep neural networks might behave in a biased manner in many real-world scenarios. For instance, deep networks trained on a large-scale face recognition dataset CelebA tend to predict blonde hair for females and black hair for males. Such biases not only jeopardize the robustness of models but also perpetuate and amplify social biases, which is especially concerning for automated decision-making processes in healthcare, recruitment, etc., as they could exacerbate unfair economic and social inequalities among different groups. Existing debiasing methods suffer from high costs in bias labeling or model re-training, while also exhibiting a deficiency in terms of elucidating the origins of biases within the model. To this respect, we propose a fast model debiasing framework (FMD) which offers an efficient approach to identify, evaluate and remove biases inherent in trained models. The FMD identifies biased attributes through an explicit counterfactual concept and quantifies the influence of data samples with influence functions. Moreover, we design a machine unlearning-based strategy to efficiently and effectively remove the bias in a trained model with a small counterfactual dataset. Experiments on the Colored MNIST, CelebA, and Adult Income datasets along with experiments with large language models demonstrate that our method achieves superior or competing accuracies compared with state-of-the-art methods while attaining significantly fewer biases and requiring much less debiasing cost. Notably, our method requires only a small external dataset and updating a minimal amount of model parameters, without the requirement of access to training data that may be too large or unavailable in practice.
TFormer: 3D Tooth Segmentation in Mesh Scans with Geometry Guided Transformer
Oct 29, 2022



Optical Intra-oral Scanners (IOS) are widely used in digital dentistry, providing 3-Dimensional (3D) and high-resolution geometrical information of dental crowns and the gingiva. Accurate 3D tooth segmentation, which aims to precisely delineate the tooth and gingiva instances in IOS, plays a critical role in a variety of dental applications. However, segmentation performance of previous methods are error-prone in complicated tooth-tooth or tooth-gingiva boundaries, and usually exhibit unsatisfactory results across various patients, yet the clinically applicability is not verified with large-scale dataset. In this paper, we propose a novel method based on 3D transformer architectures that is evaluated with large-scale and high-resolution 3D IOS datasets. Our method, termed TFormer, captures both local and global dependencies among different teeth to distinguish various types of teeth with divergent anatomical structures and confusing boundaries. Moreover, we design a geometry guided loss based on a novel point curvature to exploit boundary geometric features, which helps refine the boundary predictions for more accurate and smooth segmentation. We further employ a multi-task learning scheme, where an additional teeth-gingiva segmentation head is introduced to improve the performance. Extensive experimental results in a large-scale dataset with 16,000 IOS, the largest IOS dataset to our best knowledge, demonstrate that our TFormer can surpass existing state-of-the-art baselines with a large margin, with its utility in real-world scenarios verified by a clinical applicability test.
AI-enabled Automatic Multimodal Fusion of Cone-Beam CT and Intraoral Scans for Intelligent 3D Tooth-Bone Reconstruction and Clinical Applications
Mar 11, 2022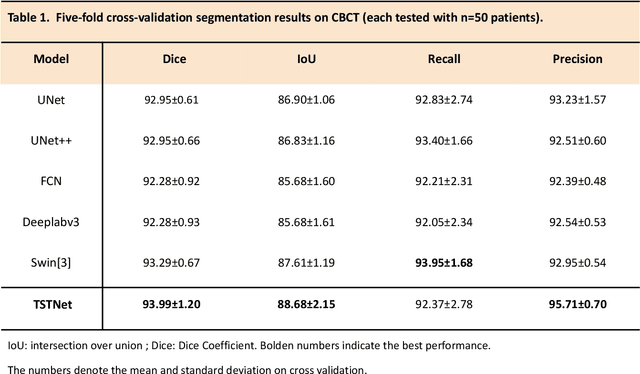
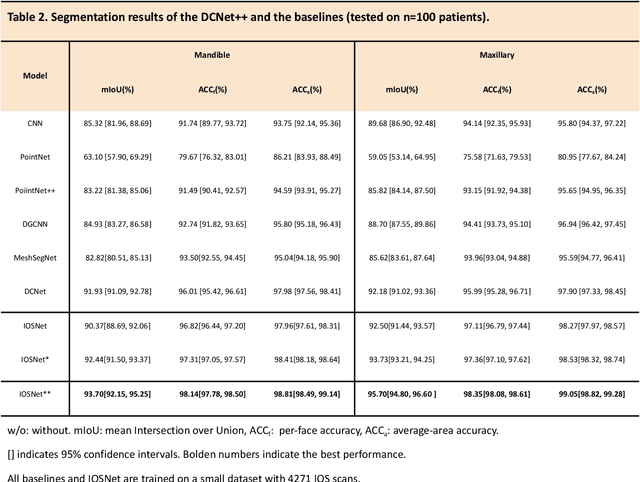

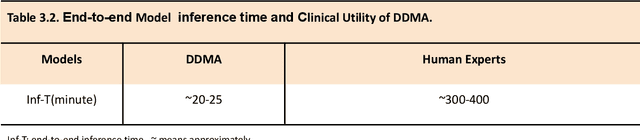
A critical step in virtual dental treatment planning is to accurately delineate all tooth-bone structures from CBCT with high fidelity and accurate anatomical information. Previous studies have established several methods for CBCT segmentation using deep learning. However, the inherent resolution discrepancy of CBCT and the loss of occlusal and dentition information largely limited its clinical applicability. Here, we present a Deep Dental Multimodal Analysis (DDMA) framework consisting of a CBCT segmentation model, an intraoral scan (IOS) segmentation model (the most accurate digital dental model), and a fusion model to generate 3D fused crown-root-bone structures with high fidelity and accurate occlusal and dentition information. Our model was trained with a large-scale dataset with 503 CBCT and 28,559 IOS meshes manually annotated by experienced human experts. For CBCT segmentation, we use a five-fold cross validation test, each with 50 CBCT, and our model achieves an average Dice coefficient and IoU of 93.99% and 88.68%, respectively, significantly outperforming the baselines. For IOS segmentations, our model achieves an mIoU of 93.07% and 95.70% on the maxillary and mandible on a test set of 200 IOS meshes, which are 1.77% and 3.52% higher than the state-of-art method. Our DDMA framework takes about 20 to 25 minutes to generate the fused 3D mesh model following the sequential processing order, compared to over 5 hours by human experts. Notably, our framework has been incorporated into a software by a clear aligner manufacturer, and real-world clinical cases demonstrate that our model can visualize crown-root-bone structures during the entire orthodontic treatment and can predict risks like dehiscence and fenestration. These findings demonstrate the potential of multi-modal deep learning to improve the quality of digital dental models and help dentists make better clinical decisions.