 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedLoGe: Joint Local and Generic Federated Learning under Long-tailed Data
Jan 17, 2024



Federated Long-Tailed Learning (Fed-LT), a paradigm wherein data collected from decentralized local clients manifests a globally prevalent long-tailed distribution, has garnered considerable attention in recent times. In the context of Fed-LT, existing works have predominantly centered on addressing the data imbalance issue to enhance the efficacy of the generic global model while neglecting the performance at the local level. In contrast, conventional Personalized Federated Learning (pFL) techniques are primarily devised to optimize personalized local models under the presumption of a balanced global data distribution. This paper introduces an approach termed Federated Local and Generic Model Training in Fed-LT (FedLoGe), which enhances both local and generic model performance through the integration of representation learning and classifier alignment within a neural collapse framework. Our investigation reveals the feasibility of employing a shared backbone as a foundational framework for capturing overarching global trends, while concurrently employing individualized classifiers to encapsulate distinct refinements stemming from each client's local features. Building upon this discovery, we establish the Static Sparse Equiangular Tight Frame Classifier (SSE-C), inspired by neural collapse principles that naturally prune extraneous noisy features and foster the acquisition of potent data representations. Furthermore, leveraging insights from imbalance neural collapse's classifier norm patterns, we develop Global and Local Adaptive Feature Realignment (GLA-FR) via an auxiliary global classifier and personalized Euclidean norm transfer to align global features with client preferences. Extensive experimental results on CIFAR-10/100-LT, ImageNet, and iNaturalist demonstrate the advantage of our method over state-of-the-art pFL and Fed-LT approaches.
AI-enabled Automatic Multimodal Fusion of Cone-Beam CT and Intraoral Scans for Intelligent 3D Tooth-Bone Reconstruction and Clinical Applications
Mar 11, 2022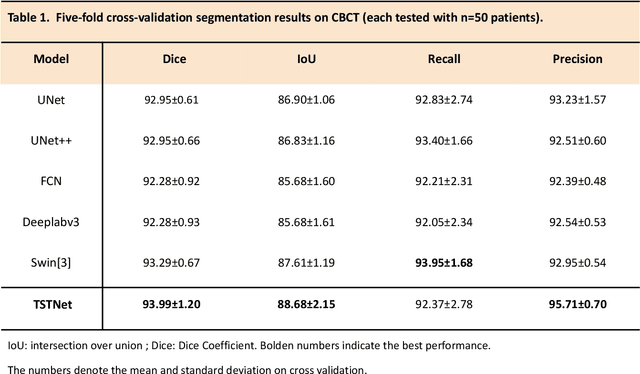
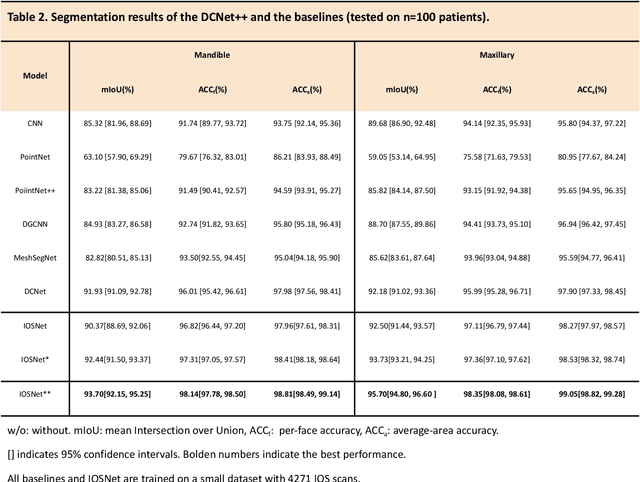

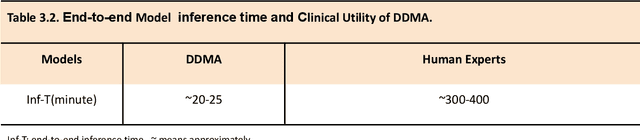
A critical step in virtual dental treatment planning is to accurately delineate all tooth-bone structures from CBCT with high fidelity and accurate anatomical information. Previous studies have established several methods for CBCT segmentation using deep learning. However, the inherent resolution discrepancy of CBCT and the loss of occlusal and dentition information largely limited its clinical applicability. Here, we present a Deep Dental Multimodal Analysis (DDMA) framework consisting of a CBCT segmentation model, an intraoral scan (IOS) segmentation model (the most accurate digital dental model), and a fusion model to generate 3D fused crown-root-bone structures with high fidelity and accurate occlusal and dentition information. Our model was trained with a large-scale dataset with 503 CBCT and 28,559 IOS meshes manually annotated by experienced human experts. For CBCT segmentation, we use a five-fold cross validation test, each with 50 CBCT, and our model achieves an average Dice coefficient and IoU of 93.99% and 88.68%, respectively, significantly outperforming the baselines. For IOS segmentations, our model achieves an mIoU of 93.07% and 95.70% on the maxillary and mandible on a test set of 200 IOS meshes, which are 1.77% and 3.52% higher than the state-of-art method. Our DDMA framework takes about 20 to 25 minutes to generate the fused 3D mesh model following the sequential processing order, compared to over 5 hours by human experts. Notably, our framework has been incorporated into a software by a clear aligner manufacturer, and real-world clinical cases demonstrate that our model can visualize crown-root-bone structures during the entire orthodontic treatment and can predict risks like dehiscence and fenestration. These findings demonstrate the potential of multi-modal deep learning to improve the quality of digital dental models and help dentists make better clinical decisions.