 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Posterior Salience Attenuation in Long-Context LLMs with Positional Contrastive Decoding
Jun 11, 2025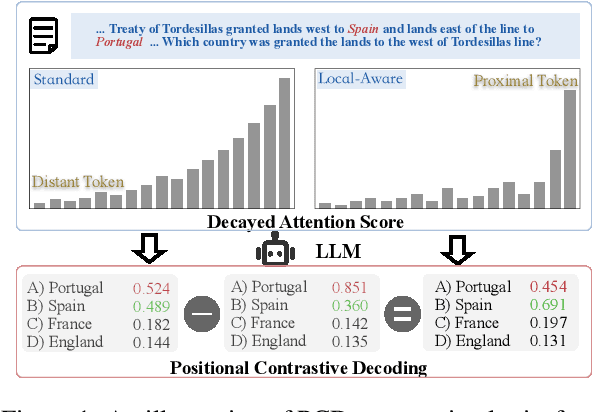
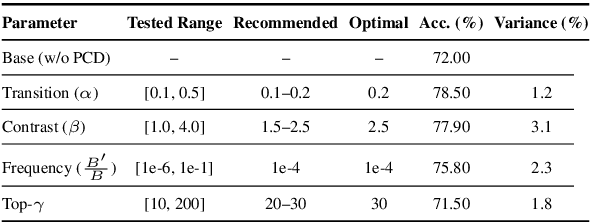
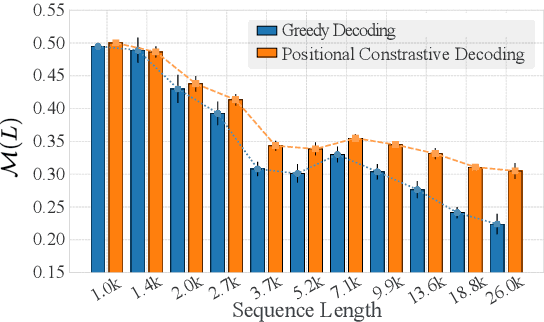
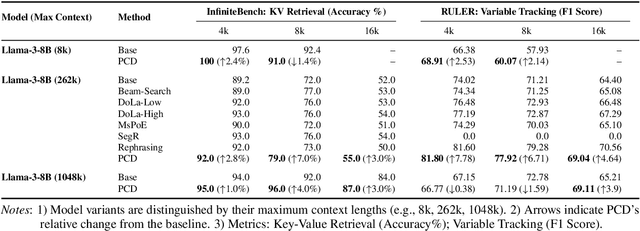
While Large Language Models (LLMs) support long contexts, they struggle with performance degradation within the context window. Current solutions incur prohibitive training costs, leaving statistical behaviors and cost-effective approaches underexplored. From the decoding perspective, we identify the Posterior Salience Attenuation (PSA) phenomenon, where the salience ratio correlates with long-text performance degradation. Notably, despite the attenuation, gold tokens still occupy high-ranking positions in the decoding space. Motivated by it, we propose the training-free Positional Contrastive Decoding (PCD) that contrasts the logits derived from long-aware attention with those from designed local-aware attention, enabling the model to focus on the gains introduced by large-scale short-to-long training. Through the analysis of long-term decay simulation, we demonstrate that PCD effectively alleviates attention score degradation. Experimental results show that PCD achieves state-of-the-art performance on long-context benchmarks.
SurgBench: A Unified Large-Scale Benchmark for Surgical Video Analysis
Jun 09, 2025Surgical video understanding is pivotal for enabling automated intraoperative decision-making, skill assessment, and postoperative quality improvement. However, progress in developing surgical video foundation models (FMs) remains hindered by the scarcity of large-scale, diverse datasets for pretraining and systematic evaluation. In this paper, we introduce \textbf{SurgBench}, a unified surgical video benchmarking framework comprising a pretraining dataset, \textbf{SurgBench-P}, and an evaluation benchmark, \textbf{SurgBench-E}. SurgBench offers extensive coverage of diverse surgical scenarios, with SurgBench-P encompassing 53 million frames across 22 surgical procedures and 11 specialties, and SurgBench-E providing robust evaluation across six categories (phase classification, camera motion, tool recognition, disease diagnosis, action classification, and organ detection) spanning 72 fine-grained tasks. Extensive experiments reveal that existing video FMs struggle to generalize across varied surgical video analysis tasks, whereas pretraining on SurgBench-P yields substantial performance improvements and superior cross-domain generalization to unseen procedures and modalities. Our dataset and code are available upon request.
PX2Tooth: Reconstructing the 3D Point Cloud Teeth from a Single Panoramic X-ray
Nov 06, 2024Reconstructing the 3D anatomical structures of the oral cavity, which originally reside in the cone-beam CT (CBCT), from a single 2D Panoramic X-ray(PX) remains a critical yet challenging task, as it can effectively reduce radiation risks and treatment costs during the diagnostic in digital dentistry. However, current methods are either error-prone or only trained/evaluated on small-scale datasets (less than 50 cases), resulting in compromised trustworthiness. In this paper, we propose PX2Tooth, a novel approach to reconstruct 3D teeth using a single PX image with a two-stage framework. First, we design the PXSegNet to segment the permanent teeth from the PX images, providing clear positional, morphological, and categorical information for each tooth. Subsequently, we design a novel tooth generation network (TGNet) that learns to transform random point clouds into 3D teeth. TGNet integrates the segmented patch information and introduces a Prior Fusion Module (PFM) to enhance the generation quality, especially in the root apex region. Moreover, we construct a dataset comprising 499 pairs of CBCT and Panoramic X-rays. Extensive experiments demonstrate that PX2Tooth can achieve an Intersection over Union (IoU) of 0.793, significantly surpassing previous methods, underscoring the great potential of artificial intelligence in digital dentistry.
Large Language Model Bias Mitigation from the Perspective of Knowledge Editing
May 15, 2024Existing debiasing methods inevitably make unreasonable or undesired predictions as they are designated and evaluated to achieve parity across different social groups but leave aside individual facts, resulting in modified existing knowledge. In this paper, we first establish a new bias mitigation benchmark BiasKE leveraging existing and additional constructed datasets, which systematically assesses debiasing performance by complementary metrics on fairness, specificity, and generalization. Meanwhile, we propose a novel debiasing method, Fairness Stamp (FAST), which enables editable fairness through fine-grained calibration on individual biased knowledge. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with remarkable debiasing performance while not hampering overall model capability for knowledge preservation, highlighting the prospect of fine-grained debiasing strategies for editable fairness in LLMs.
Theoretically Achieving Continuous Representation of Oriented Bounding Boxes
Feb 29, 2024Considerable efforts have been devoted to Oriented Object Detection (OOD). However, one lasting issue regarding the discontinuity in Oriented Bounding Box (OBB) representation remains unresolved, which is an inherent bottleneck for extant OOD methods. This paper endeavors to completely solve this issue in a theoretically guaranteed manner and puts an end to the ad-hoc efforts in this direction. Prior studies typically can only address one of the two cases of discontinuity: rotation and aspect ratio, and often inadvertently introduce decoding discontinuity, e.g. Decoding Incompleteness (DI) and Decoding Ambiguity (DA) as discussed in literature. Specifically, we propose a novel representation method called Continuous OBB (COBB), which can be readily integrated into existing detectors e.g. Faster-RCNN as a plugin. It can theoretically ensure continuity in bounding box regression which to our best knowledge, has not been achieved in literature for rectangle-based object representation. For fairness and transparency of experiments, we have developed a modularized benchmark based on the open-source deep learning framework Jittor's detection toolbox JDet for OOD evaluation. On the popular DOTA dataset, by integrating Faster-RCNN as the same baseline model, our new method outperforms the peer method Gliding Vertex by 1.13% mAP50 (relative improvement 1.54%), and 2.46% mAP75 (relative improvement 5.91%), without any tricks.
FedLoGe: Joint Local and Generic Federated Learning under Long-tailed Data
Jan 17, 2024



Federated Long-Tailed Learning (Fed-LT), a paradigm wherein data collected from decentralized local clients manifests a globally prevalent long-tailed distribution, has garnered considerable attention in recent times. In the context of Fed-LT, existing works have predominantly centered on addressing the data imbalance issue to enhance the efficacy of the generic global model while neglecting the performance at the local level. In contrast, conventional Personalized Federated Learning (pFL) techniques are primarily devised to optimize personalized local models under the presumption of a balanced global data distribution. This paper introduces an approach termed Federated Local and Generic Model Training in Fed-LT (FedLoGe), which enhances both local and generic model performance through the integration of representation learning and classifier alignment within a neural collapse framework. Our investigation reveals the feasibility of employing a shared backbone as a foundational framework for capturing overarching global trends, while concurrently employing individualized classifiers to encapsulate distinct refinements stemming from each client's local features. Building upon this discovery, we establish the Static Sparse Equiangular Tight Frame Classifier (SSE-C), inspired by neural collapse principles that naturally prune extraneous noisy features and foster the acquisition of potent data representations. Furthermore, leveraging insights from imbalance neural collapse's classifier norm patterns, we develop Global and Local Adaptive Feature Realignment (GLA-FR) via an auxiliary global classifier and personalized Euclidean norm transfer to align global features with client preferences. Extensive experimental results on CIFAR-10/100-LT, ImageNet, and iNaturalist demonstrate the advantage of our method over state-of-the-art pFL and Fed-LT approaches.
Fed-GraB: Federated Long-tailed Learning with Self-Adjusting Gradient Balancer
Oct 23, 2023



Data privacy and long-tailed distribution are the norms rather than the exception in many real-world tasks. This paper investigates a federated long-tailed learning (Fed-LT) task in which each client holds a locally heterogeneous dataset; if the datasets can be globally aggregated, they jointly exhibit a long-tailed distribution. Under such a setting, existing federated optimization and/or centralized long-tailed learning methods hardly apply due to challenges in (a) characterizing the global long-tailed distribution under privacy constraints and (b) adjusting the local learning strategy to cope with the head-tail imbalance. In response, we propose a method termed $\texttt{Fed-GraB}$, comprised of a Self-adjusting Gradient Balancer (SGB) module that re-weights clients' gradients in a closed-loop manner, based on the feedback of global long-tailed distribution evaluated by a Direct Prior Analyzer (DPA) module. Using $\texttt{Fed-GraB}$, clients can effectively alleviate the distribution drift caused by data heterogeneity during the model training process and obtain a global model with better performance on the minority classes while maintaining the performance of the majority classes. Extensive experiments demonstrate that $\texttt{Fed-GraB}$ achieves state-of-the-art performance on representative datasets such as CIFAR-10-LT, CIFAR-100-LT, ImageNet-LT, and iNaturalist.