 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Dental Landmarks from Intraoral 3D Scans: the 3DTeethLand challenge
Dec 09, 2025Teeth landmark detection is a critical task in modern clinical orthodontics. Their precise identification enables advanced diagnostics, facilitates personalized treatment strategies, and supports more effective monitoring of treatment progress in clinical dentistry. However, several significant challenges may arise due to the intricate geometry of individual teeth and the substantial variations observed across different individuals. To address these complexities, the development of advanced techniques, especially through the application of deep learning, is essential for the precise and reliable detection of 3D tooth landmarks. In this context, the 3DTeethLand challenge was held in collaboration with the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2024, calling for algorithms focused on teeth landmark detection from intraoral 3D scans. This challenge introduced the first publicly available dataset for 3D teeth landmark detection, offering a valuable resource to assess the state-of-the-art methods in this task and encourage the community to provide methodological contributions towards the resolution of their problem with significant clinical implications.
PX2Tooth: Reconstructing the 3D Point Cloud Teeth from a Single Panoramic X-ray
Nov 06, 2024Reconstructing the 3D anatomical structures of the oral cavity, which originally reside in the cone-beam CT (CBCT), from a single 2D Panoramic X-ray(PX) remains a critical yet challenging task, as it can effectively reduce radiation risks and treatment costs during the diagnostic in digital dentistry. However, current methods are either error-prone or only trained/evaluated on small-scale datasets (less than 50 cases), resulting in compromised trustworthiness. In this paper, we propose PX2Tooth, a novel approach to reconstruct 3D teeth using a single PX image with a two-stage framework. First, we design the PXSegNet to segment the permanent teeth from the PX images, providing clear positional, morphological, and categorical information for each tooth. Subsequently, we design a novel tooth generation network (TGNet) that learns to transform random point clouds into 3D teeth. TGNet integrates the segmented patch information and introduces a Prior Fusion Module (PFM) to enhance the generation quality, especially in the root apex region. Moreover, we construct a dataset comprising 499 pairs of CBCT and Panoramic X-rays. Extensive experiments demonstrate that PX2Tooth can achieve an Intersection over Union (IoU) of 0.793, significantly surpassing previous methods, underscoring the great potential of artificial intelligence in digital dentistry.
YOLOrtho -- A Unified Framework for Teeth Enumeration and Dental Disease Detection
Aug 11, 2023


Detecting dental diseases through panoramic X-rays images is a standard procedure for dentists. Normally, a dentist need to identify diseases and find the infected teeth. While numerous machine learning models adopting this two-step procedure have been developed, there has not been an end-to-end model that can identify teeth and their associated diseases at the same time. To fill the gap, we develop YOLOrtho, a unified framework for teeth enumeration and dental disease detection. We develop our model on Dentex Challenge 2023 data, which consists of three distinct types of annotated data. The first part is labeled with quadrant, and the second part is labeled with quadrant and enumeration and the third part is labeled with quadrant, enumeration and disease. To further improve detection, we make use of Tufts Dental public dataset. To fully utilize the data and learn both teeth detection and disease identification simultaneously, we formulate diseases as attributes attached to their corresponding teeth. Due to the nature of position relation in teeth enumeration, We replace convolution layer with CoordConv in our model to provide more position information for the model. We also adjust the model architecture and insert one more upsampling layer in FPN in favor of large object detection. Finally, we propose a post-process strategy for teeth layout that corrects teeth enumeration based on linear sum assignment. Results from experiments show that our model exceeds large Diffusion-based model.
AI-enabled Automatic Multimodal Fusion of Cone-Beam CT and Intraoral Scans for Intelligent 3D Tooth-Bone Reconstruction and Clinical Applications
Mar 11, 2022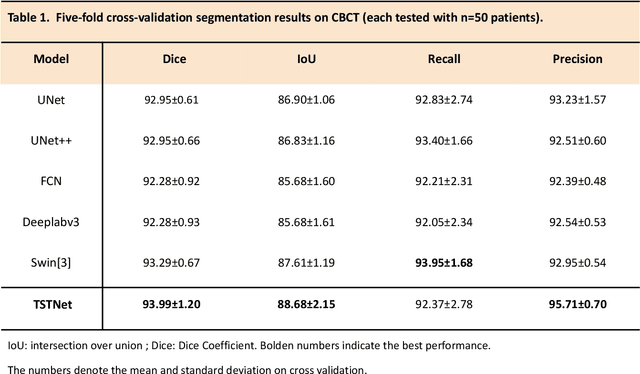
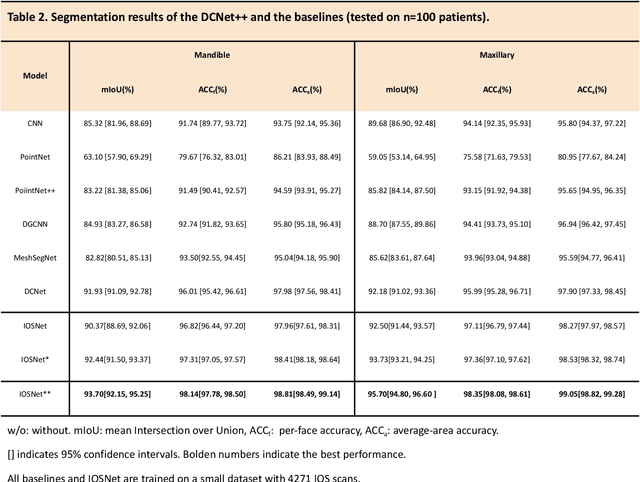

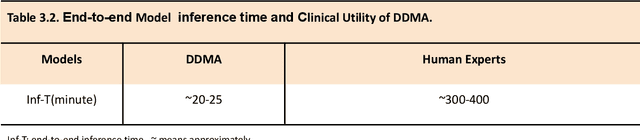
A critical step in virtual dental treatment planning is to accurately delineate all tooth-bone structures from CBCT with high fidelity and accurate anatomical information. Previous studies have established several methods for CBCT segmentation using deep learning. However, the inherent resolution discrepancy of CBCT and the loss of occlusal and dentition information largely limited its clinical applicability. Here, we present a Deep Dental Multimodal Analysis (DDMA) framework consisting of a CBCT segmentation model, an intraoral scan (IOS) segmentation model (the most accurate digital dental model), and a fusion model to generate 3D fused crown-root-bone structures with high fidelity and accurate occlusal and dentition information. Our model was trained with a large-scale dataset with 503 CBCT and 28,559 IOS meshes manually annotated by experienced human experts. For CBCT segmentation, we use a five-fold cross validation test, each with 50 CBCT, and our model achieves an average Dice coefficient and IoU of 93.99% and 88.68%, respectively, significantly outperforming the baselines. For IOS segmentations, our model achieves an mIoU of 93.07% and 95.70% on the maxillary and mandible on a test set of 200 IOS meshes, which are 1.77% and 3.52% higher than the state-of-art method. Our DDMA framework takes about 20 to 25 minutes to generate the fused 3D mesh model following the sequential processing order, compared to over 5 hours by human experts. Notably, our framework has been incorporated into a software by a clear aligner manufacturer, and real-world clinical cases demonstrate that our model can visualize crown-root-bone structures during the entire orthodontic treatment and can predict risks like dehiscence and fenestration. These findings demonstrate the potential of multi-modal deep learning to improve the quality of digital dental models and help dentists make better clinical decisions.
SparseMask: Differentiable Connectivity Learning for Dense Image Prediction
Apr 16, 2019

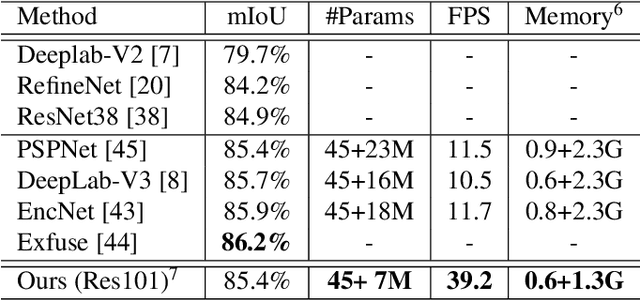
In this paper, we aim at automatically searching an efficient network architecture for dense image prediction. Particularly, we follow the encoder-decoder style and focus on automatically designing a connectivity structure for the decoder. To achieve that, we first design a densely connected network with learnable connections named Fully Dense Network, which contains a large set of possible final connectivity structures. We then employ gradient descent to search the optimal connectivity from the dense connections. The search process is guided by a novel loss function, which pushes the weight of each connection to be binary and the connections to be sparse. The discovered connectivity achieves competitive results on two segmentation datasets, while runs more than three times faster and requires less than half parameters compared to state-of-the-art methods. An extensive experiment shows that the discovered connectivity is compatible with various backbones and generalizes well to other dense image prediction tasks.
FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation
Mar 28, 2019



Modern approaches for semantic segmentation usually employ dilated convolutions in the backbone to extract high-resolution feature maps, which brings heavy computation complexity and memory footprint. To replace the time and memory consuming dilated convolutions, we propose a novel joint upsampling module named Joint Pyramid Upsampling (JPU) by formulating the task of extracting high-resolution feature maps into a joint upsampling problem. With the proposed JPU, our method reduces the computation complexity by more than three times without performance loss. Experiments show that JPU is superior to other upsampling modules, which can be plugged into many existing approaches to reduce computation complexity and improve performance. By replacing dilated convolutions with the proposed JPU module, our method achieves the state-of-the-art performance in Pascal Context dataset (mIoU of 53.13%) and ADE20K dataset (final score of 0.5584) while running 3 times faster.
Fast End-to-End Trainable Guided Filter
Mar 15, 2018
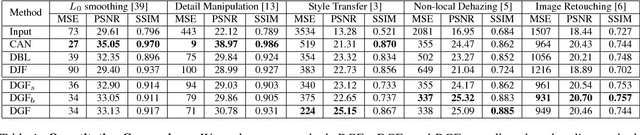


Image processing and pixel-wise dense prediction have been advanced by harnessing the capabilities of deep learning. One central issue of deep learning is the limited capacity to handle joint upsampling. We present a deep learning building block for joint upsampling, namely guided filtering layer. This layer aims at efficiently generating the high-resolution output given the corresponding low-resolution one and a high-resolution guidance map. The proposed layer is composed of a guided filter, which is reformulated as a fully differentiable block. To this end, we show that a guided filter can be expressed as a group of spatial varying linear transformation matrices. This layer could be integrated with the convolutional neural networks (CNNs) and jointly optimized through end-to-end training. To further take advantage of end-to-end training, we plug in a trainable transformation function that generates task-specific guidance maps. By integrating the CNNs and the proposed layer, we form deep guided filtering networks. The proposed networks are evaluated on five advanced image processing tasks. Experiments on MIT-Adobe FiveK Dataset demonstrate that the proposed approach runs 10-100 times faster and achieves the state-of-the-art performance. We also show that the proposed guided filtering layer helps to improve the performance of multiple pixel-wise dense prediction tasks. The code is available at https://github.com/wuhuikai/DeepGuidedFilter.
A2-RL: Aesthetics Aware Reinforcement Learning for Image Cropping
Mar 12, 2018



Image cropping aims at improving the aesthetic quality of images by adjusting their composition. Most weakly supervised cropping methods (without bounding box supervision) rely on the sliding window mechanism. The sliding window mechanism requires fixed aspect ratios and limits the cropping region with arbitrary size. Moreover, the sliding window method usually produces tens of thousands of windows on the input image which is very time-consuming. Motivated by these challenges, we firstly formulate the aesthetic image cropping as a sequential decision-making process and propose a weakly supervised Aesthetics Aware Reinforcement Learning (A2-RL) framework to address this problem. Particularly, the proposed method develops an aesthetics aware reward function which especially benefits image cropping. Similar to human's decision making, we use a comprehensive state representation including both the current observation and the historical experience. We train the agent using the actor-critic architecture in an end-to-end manner. The agent is evaluated on several popular unseen cropping datasets. Experiment results show that our method achieves the state-of-the-art performance with much fewer candidate windows and much less time compared with previous weakly supervised methods.
MSC: A Dataset for Macro-Management in StarCraft II
Oct 09, 2017


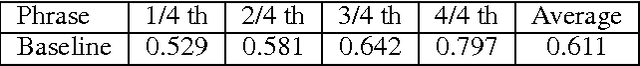
Macro-management is an important problem in StarCraft, which has been studied for a long time. Various datasets together with assorted methods have been proposed in the last few years. But these datasets have some defects for boosting the academic and industrial research: 1) There're neither standard preprocessing, parsing and feature extraction procedures nor predefined training, validation and test set in some datasets. 2) Some datasets are only specified for certain tasks in macro-management. 3) Some datasets are either too small or don't have enough labeled data for modern machine learning algorithms such as deep neural networks. So most previous methods are trained with various features, evaluated on different test sets from the same or different datasets, making it difficult to be compared directly. To boost the research of macro-management in StarCraft, we release a new dataset MSC based on the platform SC2LE. MSC consists of well-designed feature vectors, pre-defined high-level actions and final result of each match. We also split MSC into training, validation and test set for the convenience of evaluation and comparison. Besides the dataset, we propose a baseline model and present initial baseline results for global state evaluation and build order prediction, which are two of the key tasks in macro-management. Various downstream tasks and analyses of the dataset are also described for the sake of research on macro-management in StarCraft II. Homepage: https://github.com/wuhuikai/MSC.
GP-GAN: Towards Realistic High-Resolution Image Blending
Mar 25, 2017



Recent advances in generative adversarial networks (GANs) have shown promising potentials in conditional image generation. However, how to generate high-resolution images remains an open problem. In this paper, we aim at generating high-resolution well-blended images given composited copy-and-paste ones, i.e. realistic high-resolution image blending. To achieve this goal, we propose Gaussian-Poisson GAN (GP-GAN), a framework that combines the strengths of classical gradient-based approaches and GANs, which is the first work that explores the capability of GANs in high-resolution image blending task to the best of our knowledge. Particularly, we propose Gaussian-Poisson Equation to formulate the high-resolution image blending problem, which is a joint optimisation constrained by the gradient and colour information. Gradient filters can obtain gradient information. For generating the colour information, we propose Blending GAN to learn the mapping between the composited image and the well-blended one. Compared to the alternative methods, our approach can deliver high-resolution, realistic images with fewer bleedings and unpleasant artefacts. Experiments confirm that our approach achieves the state-of-the-art performance on Transient Attributes dataset. A user study on Amazon Mechanical Turk finds that majority of workers are in favour of the proposed approach.