 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
May 28, 2026Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fragmented capabilities and limited generalization across tasks, environments, and robot embodiments. In this work, we study whether heterogeneous embodied decision-making problems can be unified within a single vision-language-action model. We present Qwen-VLA, a unified embodied foundation model that extends Qwen's vision-language modeling stack from perception, understanding, and reasoning to continuous action and trajectory generation through a DiT-based action decoder. Qwen-VLA is trained with a large-scale joint pretraining recipe over diverse data sources, including robotics manipulation trajectories, human egocentric demonstrations, synthetic simulation data, vision-and-language navigation data, trajectory-centric supervision, and auxiliary vision-language data. To support multiple robot platforms, we introduce embodiment-aware prompt conditioning, where robot-specific textual descriptions specify the current embodiment and control convention. We further cast manipulation, navigation, and trajectory prediction into a unified action-and-trajectory prediction framework, enabling transferable visual grounding, spatial reasoning, and continuous action generation across robot morphologies, task families, and environments. Experiments on manipulation, navigation, and trajectory-centric benchmarks show consistent multi-task performance and out-of-distribution generalization under variations in scene layout, background, lighting, object configuration, and robot embodiment. Qwen-VLA-Instruct achieves 97.9% on LIBERO, 73.7% on Simpler-WidowX, 86.1%/87.2% on RoboTwin-Easy/Hard, 69.0% OSR on R2R, 59.6% SR on RxR, 76.9% average OOD success in real-world ALOHA experiments, and 26.6% zero-shot success on DOMINO dynamic manipulation.
Artifact-Bench: Evaluating MLLMs on Detecting and Assessing the Artifacts of AI-Generated Videos
May 18, 2026Recent video generative models have greatly improved the realism of AI-generated videos, yet their outputs still exhibit artifacts such as temporal inconsistencies, structural distortions, and semantic incoherence. While Multimodal Large Language Models (MLLMs) show strong visual understanding capabilities, their ability to perceive and reason about such artifacts remains unclear. Existing benchmarks often lack systematic evaluation of artifact-aware perception and fine-grained diagnostic reasoning, especially across diverse AI-generated video domains beyond photorealistic content. To address this gap, we introduce Artifact-Bench, a comprehensive benchmark for evaluating MLLMs on AI-generated video artifact detection and analysis. We first establish a three-level hierarchical taxonomy of realism artifacts, covering photorealistic, animated, and CG-style videos. Based on this taxonomy, Artifact-Bench defines three complementary tasks: real vs. AI-generated video classification, pairwise realism comparison, and fine-grained artifact identification. Experiments on 19 leading MLLMs reveal substantial limitations in artifact perception and reasoning, with many models approaching random or even below-random performance in challenging settings. We further observe significant misalignment between MLLM judgments and human perceptual preferences, highlighting their limited reliability as general evaluators for AI-generated video realism.
Optimsyn: Influence-Guided Rubrics Optimization for Synthetic Data Generation
Apr 01, 2026Large language models (LLMs) achieve strong downstream performance largely due to abundant supervised fine-tuning (SFT) data. However, high-quality SFT data in knowledge-intensive domains such as humanities, social sciences, medicine, law, and finance is scarce because expert curation is expensive, privacy constraints are strict, and label consistency is hard to ensure. Recent work uses synthetic data, typically by prompting a generator over domain documents and filtering outputs with handcrafted rubrics. Yet rubric design is expert-dependent, transfers poorly across domains, and is often optimized through a brittle heuristic loop of writing rubrics, synthesizing data, training, inspecting results, and manually guessing revisions. This process lacks reliable quantitative feedback about how a rubric affects downstream performance. We propose evaluating synthetic data by its training utility on the target model and using this signal to guide data generation. Inspired by influence estimation, we adopt an optimizer-aware estimator that uses gradient information to quantify each synthetic sample's contribution to a target model's objective on specific tasks. Our analysis shows that even when synthetic and real samples are close in embedding space, their influence on learning can differ substantially. Based on this insight, we propose an optimization-based framework that adapts rubrics using target-model feedback. We provide lightweight guiding text and use a rubric-specialized model to generate task-conditioned rubrics. Influence score is used as the reward to optimize the rubric generator with reinforcement learning. Experiments across domains, target models, and data generators show consistent improvements and strong generalization without task-specific tuning.
Learning Transferable Temporal Primitives for Video Reasoning via Synthetic Videos
Mar 18, 2026The transition from image to video understanding requires vision-language models (VLMs) to shift from recognizing static patterns to reasoning over temporal dynamics such as motion trajectories, speed changes, and state transitions. Yet current post-training methods fall short due to two critical limitations: (1) existing datasets often lack temporal-centricity, where answers can be inferred from isolated keyframes rather than requiring holistic temporal integration; and (2) training data generated by proprietary models contains systematic errors in fundamental temporal perception, such as confusing motion directions or misjudging speeds. We introduce SynRL, a post-training framework that teaches models temporal primitives, the fundamental building blocks of temporal understanding including direction, speed, and state tracking. Our key insight is that these abstract primitives, learned from programmatically generated synthetic videos, transfer effectively to real-world scenarios. We decompose temporal understanding into short-term perceptual primitives (speed, direction) and long-term cognitive primitives, constructing 7.7K CoT and 7K RL samples with ground-truth frame-level annotations through code-based video generation. Despite training on simple geometric shapes, SynRL achieves substantial improvements across 15 benchmarks spanning temporal grounding, complex reasoning, and general video understanding. Remarkably, our 7.7K synthetic CoT samples outperform Video-R1 with 165K real-world samples. We attribute this to fundamental temporal skills, such as tracking frame by frame changes and comparing velocity, that transfer effectively from abstract synthetic patterns to complex real-world scenarios. This establishes a new paradigm for video post-training: video temporal learning through carefully designed synthetic data provides a more cost efficient scaling path.
From Narrow to Panoramic Vision: Attention-Guided Cold-Start Reshapes Multimodal Reasoning
Mar 04, 2026The cold-start initialization stage plays a pivotal role in training Multimodal Large Reasoning Models (MLRMs), yet its mechanisms remain insufficiently understood. To analyze this stage, we introduce the Visual Attention Score (VAS), an attention-based metric that quantifies how much a model attends to visual tokens. We find that reasoning performance is strongly correlated with VAS (r=0.9616): models with higher VAS achieve substantially stronger multimodal reasoning. Surprisingly, multimodal cold-start fails to elevate VAS, resulting in attention distributions close to the base model, whereas text-only cold-start leads to a clear increase. We term this counter-intuitive phenomenon Lazy Attention Localization. To validate its causal role, we design training-free interventions that directly modulate attention allocation during inference, performance gains of 1$-$2% without any retraining. Building on these insights, we further propose Attention-Guided Visual Anchoring and Reflection (AVAR), a comprehensive cold-start framework that integrates visual-anchored data synthesis, attention-guided objectives, and visual-anchored reward shaping. Applied to Qwen2.5-VL-7B, AVAR achieves an average gain of 7.0% across 7 multimodal reasoning benchmarks. Ablation studies further confirm that each component of AVAR contributes step-wise to the overall gains. The code, data, and models are available at https://github.com/lrlbbzl/Qwen-AVAR.
Towards Proactive Personalization through Profile Customization for Individual Users in Dialogues
Dec 17, 2025The deployment of Large Language Models (LLMs) in interactive systems necessitates a deep alignment with the nuanced and dynamic preferences of individual users. Current alignment techniques predominantly address universal human values or static, single-turn preferences, thereby failing to address the critical needs of long-term personalization and the initial user cold-start problem. To bridge this gap, we propose PersonalAgent, a novel user-centric lifelong agent designed to continuously infer and adapt to user preferences. PersonalAgent constructs and dynamically refines a unified user profile by decomposing dialogues into single-turn interactions, framing preference inference as a sequential decision-making task. Experiments show that PersonalAgent achieves superior performance over strong prompt-based and policy optimization baselines, not only in idealized but also in noisy conversational contexts, while preserving cross-session preference consistency. Furthermore, human evaluation confirms that PersonalAgent excels at capturing user preferences naturally and coherently. Our findings underscore the importance of lifelong personalization for developing more inclusive and adaptive conversational agents. Our code is available here.
Datasets and Recipes for Video Temporal Grounding via Reinforcement Learning
Jul 24, 2025Video Temporal Grounding (VTG) aims to localize relevant temporal segments in videos given natural language queries. Despite recent progress with large vision-language models (LVLMs) and instruction-tuning, existing approaches often suffer from limited temporal awareness and poor generalization. In this work, we introduce a two-stage training framework that integrates supervised fine-tuning with reinforcement learning (RL) to improve both the accuracy and robustness of VTG models. Our approach first leverages high-quality curated cold start data for SFT initialization, followed by difficulty-controlled RL to further enhance temporal localization and reasoning abilities. Comprehensive experiments on multiple VTG benchmarks demonstrate that our method consistently outperforms existing models, particularly in challenging and open-domain scenarios. We conduct an in-depth analysis of training strategies and dataset curation, highlighting the importance of both high-quality cold start data and difficulty-controlled RL. To facilitate further research and industrial adoption, we release all intermediate datasets, models, and code to the community.
CAPO: Reinforcing Consistent Reasoning in Medical Decision-Making
Jun 15, 2025
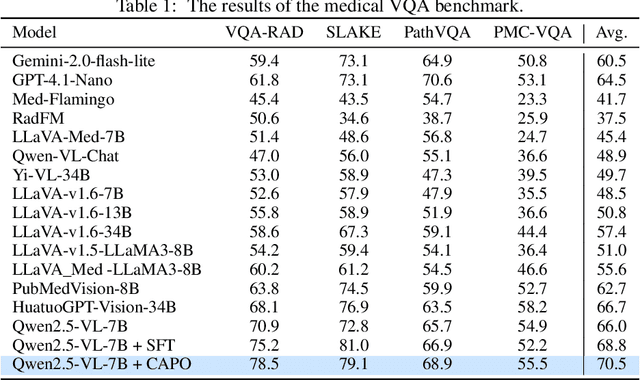
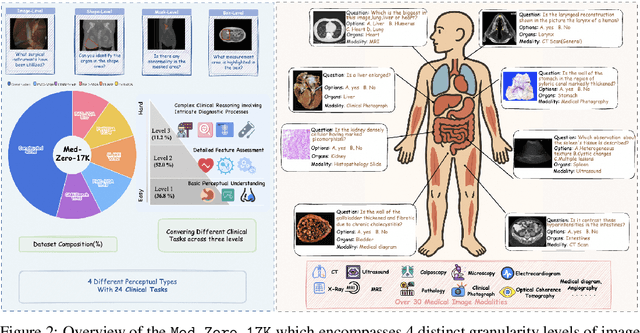
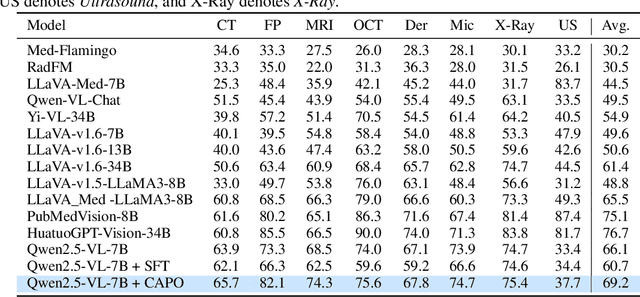
In medical visual question answering (Med-VQA), achieving accurate responses relies on three critical steps: precise perception of medical imaging data, logical reasoning grounded in visual input and textual questions, and coherent answer derivation from the reasoning process. Recent advances in general vision-language models (VLMs) show that large-scale reinforcement learning (RL) could significantly enhance both reasoning capabilities and overall model performance. However, their application in medical domains is hindered by two fundamental challenges: 1) misalignment between perceptual understanding and reasoning stages, and 2) inconsistency between reasoning pathways and answer generation, both compounded by the scarcity of high-quality medical datasets for effective large-scale RL. In this paper, we first introduce Med-Zero-17K, a curated dataset for pure RL-based training, encompassing over 30 medical image modalities and 24 clinical tasks. Moreover, we propose a novel large-scale RL framework for Med-VLMs, Consistency-Aware Preference Optimization (CAPO), which integrates rewards to ensure fidelity between perception and reasoning, consistency in reasoning-to-answer derivation, and rule-based accuracy for final responses. Extensive experiments on both in-domain and out-of-domain scenarios demonstrate the superiority of our method over strong VLM baselines, showcasing strong generalization capability to 3D Med-VQA benchmarks and R1-like training paradigms.
Med-U1: Incentivizing Unified Medical Reasoning in LLMs via Large-scale Reinforcement Learning
Jun 14, 2025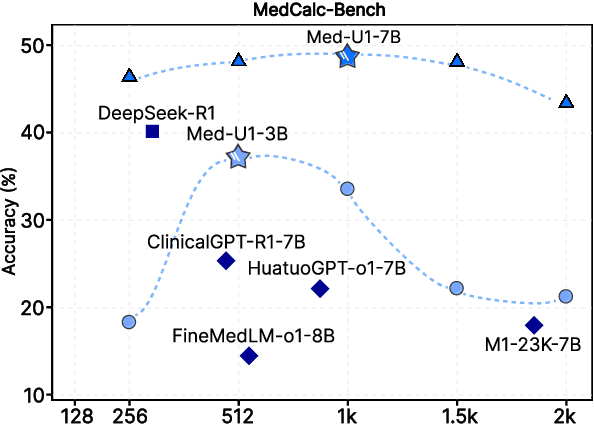
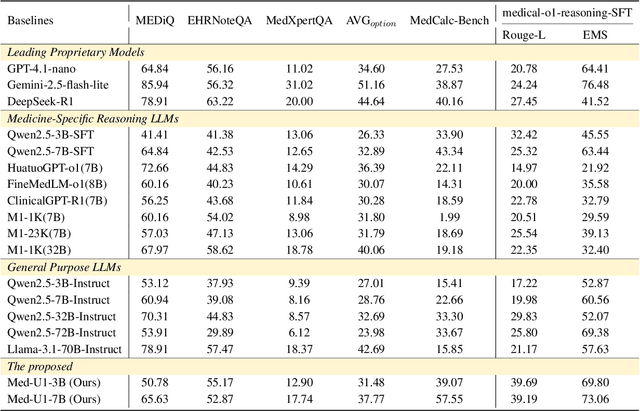
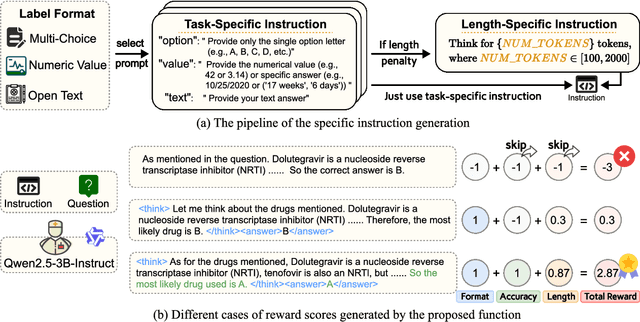
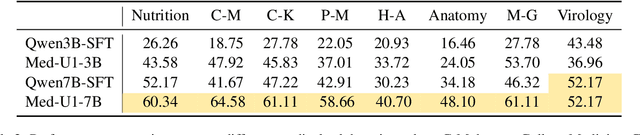
Medical Question-Answering (QA) encompasses a broad spectrum of tasks, including multiple choice questions (MCQ), open-ended text generation, and complex computational reasoning. Despite this variety, a unified framework for delivering high-quality medical QA has yet to emerge. Although recent progress in reasoning-augmented large language models (LLMs) has shown promise, their ability to achieve comprehensive medical understanding is still largely unexplored. In this paper, we present Med-U1, a unified framework for robust reasoning across medical QA tasks with diverse output formats, ranging from MCQs to complex generation and computation tasks. Med-U1 employs pure large-scale reinforcement learning with mixed rule-based binary reward functions, incorporating a length penalty to manage output verbosity. With multi-objective reward optimization, Med-U1 directs LLMs to produce concise and verifiable reasoning chains. Empirical results reveal that Med-U1 significantly improves performance across multiple challenging Med-QA benchmarks, surpassing even larger specialized and proprietary models. Furthermore, Med-U1 demonstrates robust generalization to out-of-distribution (OOD) tasks. Extensive analysis presents insights into training strategies, reasoning chain length control, and reward design for medical LLMs. The code will be released.
BiasFilter: An Inference-Time Debiasing Framework for Large Language Models
May 28, 2025Mitigating social bias in large language models (LLMs) has become an increasingly important research objective. However, existing debiasing methods often incur high human and computational costs, exhibit limited effectiveness, and struggle to scale to larger models and open-ended generation tasks. To address these limitations, this paper proposes BiasFilter, a model-agnostic, inference-time debiasing framework that integrates seamlessly with both open-source and API-based LLMs. Instead of relying on retraining with balanced data or modifying model parameters, BiasFilter enforces fairness by filtering generation outputs in real time. Specifically, it periodically evaluates intermediate outputs every few tokens, maintains an active set of candidate continuations, and incrementally completes generation by discarding low-reward segments based on a fairness reward signal. To support this process, we construct a fairness preference dataset and train an implicit reward model to assess token-level fairness in generated responses. Extensive experiments demonstrate that BiasFilter effectively mitigates social bias across a range of LLMs while preserving overall generation quality.