 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Temporal Primitives for Video Reasoning via Synthetic Videos
Mar 18, 2026The transition from image to video understanding requires vision-language models (VLMs) to shift from recognizing static patterns to reasoning over temporal dynamics such as motion trajectories, speed changes, and state transitions. Yet current post-training methods fall short due to two critical limitations: (1) existing datasets often lack temporal-centricity, where answers can be inferred from isolated keyframes rather than requiring holistic temporal integration; and (2) training data generated by proprietary models contains systematic errors in fundamental temporal perception, such as confusing motion directions or misjudging speeds. We introduce SynRL, a post-training framework that teaches models temporal primitives, the fundamental building blocks of temporal understanding including direction, speed, and state tracking. Our key insight is that these abstract primitives, learned from programmatically generated synthetic videos, transfer effectively to real-world scenarios. We decompose temporal understanding into short-term perceptual primitives (speed, direction) and long-term cognitive primitives, constructing 7.7K CoT and 7K RL samples with ground-truth frame-level annotations through code-based video generation. Despite training on simple geometric shapes, SynRL achieves substantial improvements across 15 benchmarks spanning temporal grounding, complex reasoning, and general video understanding. Remarkably, our 7.7K synthetic CoT samples outperform Video-R1 with 165K real-world samples. We attribute this to fundamental temporal skills, such as tracking frame by frame changes and comparing velocity, that transfer effectively from abstract synthetic patterns to complex real-world scenarios. This establishes a new paradigm for video post-training: video temporal learning through carefully designed synthetic data provides a more cost efficient scaling path.
CodePercept: Code-Grounded Visual STEM Perception for MLLMs
Mar 11, 2026When MLLMs fail at Science, Technology, Engineering, and Mathematics (STEM) visual reasoning, a fundamental question arises: is it due to perceptual deficiencies or reasoning limitations? Through systematic scaling analysis that independently scales perception and reasoning components, we uncover a critical insight: scaling perception consistently outperforms scaling reasoning. This reveals perception as the true lever limiting current STEM visual reasoning. Motivated by this insight, our work focuses on systematically enhancing the perception capabilities of MLLMs by establishing code as a powerful perceptual medium--executable code provides precise semantics that naturally align with the structured nature of STEM visuals. Specifically, we construct ICC-1M, a large-scale dataset comprising 1M Image-Caption-Code triplets that materializes this code-as-perception paradigm through two complementary approaches: (1) Code-Grounded Caption Generation treats executable code as ground truth for image captions, eliminating the hallucinations inherent in existing knowledge distillation methods; (2) STEM Image-to-Code Translation prompts models to generate reconstruction code, mitigating the ambiguity of natural language for perception enhancement. To validate this paradigm, we further introduce STEM2Code-Eval, a novel benchmark that directly evaluates visual perception in STEM domains. Unlike existing work relying on problem-solving accuracy as a proxy that only measures problem-relevant understanding, our benchmark requires comprehensive visual comprehension through executable code generation for image reconstruction, providing deterministic and verifiable assessment. Code is available at https://github.com/TongkunGuan/Qwen-CodePercept.
From Narrow to Panoramic Vision: Attention-Guided Cold-Start Reshapes Multimodal Reasoning
Mar 04, 2026The cold-start initialization stage plays a pivotal role in training Multimodal Large Reasoning Models (MLRMs), yet its mechanisms remain insufficiently understood. To analyze this stage, we introduce the Visual Attention Score (VAS), an attention-based metric that quantifies how much a model attends to visual tokens. We find that reasoning performance is strongly correlated with VAS (r=0.9616): models with higher VAS achieve substantially stronger multimodal reasoning. Surprisingly, multimodal cold-start fails to elevate VAS, resulting in attention distributions close to the base model, whereas text-only cold-start leads to a clear increase. We term this counter-intuitive phenomenon Lazy Attention Localization. To validate its causal role, we design training-free interventions that directly modulate attention allocation during inference, performance gains of 1$-$2% without any retraining. Building on these insights, we further propose Attention-Guided Visual Anchoring and Reflection (AVAR), a comprehensive cold-start framework that integrates visual-anchored data synthesis, attention-guided objectives, and visual-anchored reward shaping. Applied to Qwen2.5-VL-7B, AVAR achieves an average gain of 7.0% across 7 multimodal reasoning benchmarks. Ablation studies further confirm that each component of AVAR contributes step-wise to the overall gains. The code, data, and models are available at https://github.com/lrlbbzl/Qwen-AVAR.
From Sparse Decisions to Dense Reasoning: A Multi-attribute Trajectory Paradigm for Multimodal Moderation
Jan 28, 2026Safety moderation is pivotal for identifying harmful content. Despite the success of textual safety moderation, its multimodal counterparts remain hindered by a dual sparsity of data and supervision. Conventional reliance on binary labels lead to shortcut learning, which obscures the intrinsic classification boundaries necessary for effective multimodal discrimination. Hence, we propose a novel learning paradigm (UniMod) that transitions from sparse decision-making to dense reasoning traces. By constructing structured trajectories encompassing evidence grounding, modality assessment, risk mapping, policy decision, and response generation, we reformulate monolithic decision tasks into a multi-dimensional boundary learning process. This approach forces the model to ground its decision in explicit safety semantics, preventing the model from converging on superficial shortcuts. To facilitate this paradigm, we develop a multi-head scalar reward model (UniRM). UniRM provides multi-dimensional supervision by assigning attribute-level scores to the response generation stage. Furthermore, we introduce specialized optimization strategies to decouple task-specific parameters and rebalance training dynamics, effectively resolving interference between diverse objectives in multi-task learning. Empirical results show UniMod achieves competitive textual moderation performance and sets a new multimodal benchmark using less than 40\% of the training data used by leading baselines. Ablations further validate our multi-attribute trajectory reasoning, offering an effective and efficient framework for multimodal moderation. Supplementary materials are available at \href{https://trustworthylab.github.io/UniMod/}{project website}.
CAPO: Reinforcing Consistent Reasoning in Medical Decision-Making
Jun 15, 2025
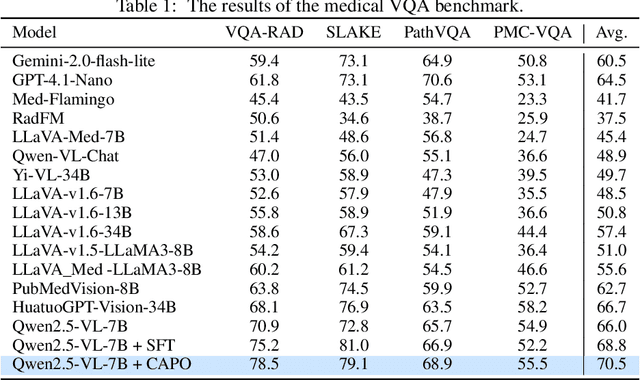
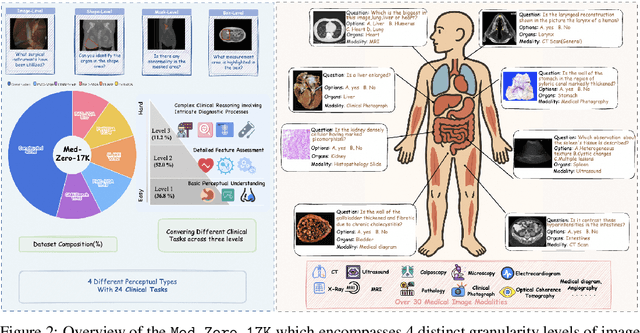
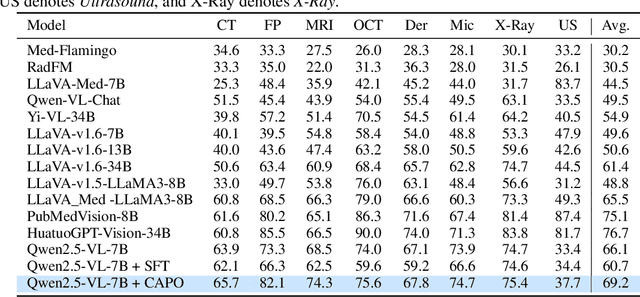
In medical visual question answering (Med-VQA), achieving accurate responses relies on three critical steps: precise perception of medical imaging data, logical reasoning grounded in visual input and textual questions, and coherent answer derivation from the reasoning process. Recent advances in general vision-language models (VLMs) show that large-scale reinforcement learning (RL) could significantly enhance both reasoning capabilities and overall model performance. However, their application in medical domains is hindered by two fundamental challenges: 1) misalignment between perceptual understanding and reasoning stages, and 2) inconsistency between reasoning pathways and answer generation, both compounded by the scarcity of high-quality medical datasets for effective large-scale RL. In this paper, we first introduce Med-Zero-17K, a curated dataset for pure RL-based training, encompassing over 30 medical image modalities and 24 clinical tasks. Moreover, we propose a novel large-scale RL framework for Med-VLMs, Consistency-Aware Preference Optimization (CAPO), which integrates rewards to ensure fidelity between perception and reasoning, consistency in reasoning-to-answer derivation, and rule-based accuracy for final responses. Extensive experiments on both in-domain and out-of-domain scenarios demonstrate the superiority of our method over strong VLM baselines, showcasing strong generalization capability to 3D Med-VQA benchmarks and R1-like training paradigms.
URSA: Understanding and Verifying Chain-of-thought Reasoning in Multimodal Mathematics
Jan 08, 2025



Chain-of-thought (CoT) reasoning has been widely applied in the mathematical reasoning of Large Language Models (LLMs). Recently, the introduction of derivative process supervision on CoT trajectories has sparked discussions on enhancing scaling capabilities during test time, thereby boosting the potential of these models. However, in multimodal mathematical reasoning, the scarcity of high-quality CoT training data has hindered existing models from achieving high-precision CoT reasoning and has limited the realization of reasoning potential during test time. In this work, we propose a three-module synthesis strategy that integrates CoT distillation, trajectory-format rewriting, and format unification. It results in a high-quality CoT reasoning instruction fine-tuning dataset in multimodal mathematics, MMathCoT-1M. We comprehensively validate the state-of-the-art (SOTA) performance of the trained URSA-7B model on multiple multimodal mathematical benchmarks. For test-time scaling, we introduce a data synthesis strategy that automatically generates process annotation datasets, known as DualMath-1.1M, focusing on both interpretation and logic. By further training URSA-7B on DualMath-1.1M, we transition from CoT reasoning capabilities to robust supervision abilities. The trained URSA-RM-7B acts as a verifier, effectively enhancing the performance of URSA-7B at test time. URSA-RM-7B also demonstrates excellent out-of-distribution (OOD) verifying capabilities, showcasing its generalization. Model weights, training data and code will be open-sourced.
Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM's Reasoning Capability
Dec 02, 2024



Large Language Models (LLMs) have exhibited remarkable performance on reasoning tasks. They utilize autoregressive token generation to construct reasoning trajectories, enabling the development of a coherent chain of thought. In this work, we explore the impact of individual tokens on the final outcomes of reasoning tasks. We identify the existence of ``critical tokens'' that lead to incorrect reasoning trajectories in LLMs. Specifically, we find that LLMs tend to produce positive outcomes when forced to decode other tokens instead of critical tokens. Motivated by this observation, we propose a novel approach - cDPO - designed to automatically recognize and conduct token-level rewards for the critical tokens during the alignment process. Specifically, we develop a contrastive estimation approach to automatically identify critical tokens. It is achieved by comparing the generation likelihood of positive and negative models. To achieve this, we separately fine-tune the positive and negative models on various reasoning trajectories, consequently, they are capable of identifying identify critical tokens within incorrect trajectories that contribute to erroneous outcomes. Moreover, to further align the model with the critical token information during the alignment process, we extend the conventional DPO algorithms to token-level DPO and utilize the differential likelihood from the aforementioned positive and negative model as important weight for token-level DPO learning.Experimental results on GSM8K and MATH500 benchmarks with two-widely used models Llama-3 (8B and 70B) and deepseek-math (7B) demonstrate the effectiveness of the propsoed approach cDPO.
PTD-SQL: Partitioning and Targeted Drilling with LLMs in Text-to-SQL
Sep 21, 2024

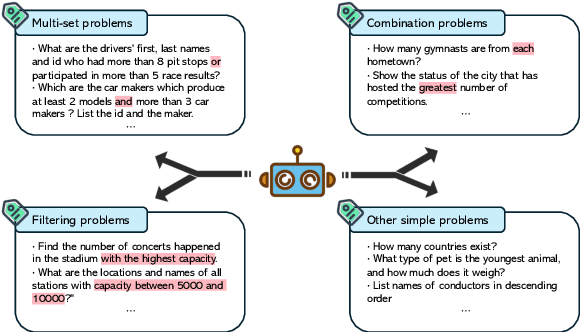
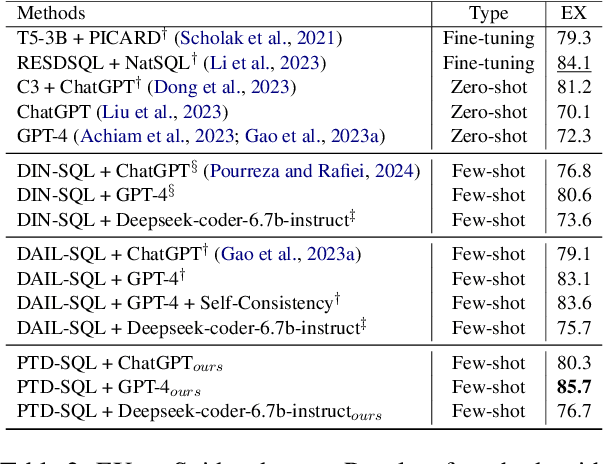
Large Language Models (LLMs) have emerged as powerful tools for Text-to-SQL tasks, exhibiting remarkable reasoning capabilities. Different from tasks such as math word problems and commonsense reasoning, SQL solutions have a relatively fixed pattern. This facilitates the investigation of whether LLMs can benefit from categorical thinking, mirroring how humans acquire knowledge through inductive reasoning based on comparable examples. In this study, we propose that employing query group partitioning allows LLMs to focus on learning the thought processes specific to a single problem type, consequently enhancing their reasoning abilities across diverse difficulty levels and problem categories. Our experiments reveal that multiple advanced LLMs, when equipped with PTD-SQL, can either surpass or match previous state-of-the-art (SOTA) methods on the Spider and BIRD datasets. Intriguingly, models with varying initial performances have exhibited significant improvements, mainly at the boundary of their capabilities after targeted drilling, suggesting a parallel with human progress. Code is available at https://github.com/lrlbbzl/PTD-SQL.
MEOW: MEMOry Supervised LLM Unlearning Via Inverted Facts
Sep 18, 2024Large Language Models (LLMs) can memorize sensitive information, raising concerns about potential misuse. LLM Unlearning, a post-hoc approach to remove this information from trained LLMs, offers a promising solution to mitigate these risks. However, previous practices face three key challenges: 1. Utility: successful unlearning often causes catastrophic collapse on unrelated tasks. 2. Efficiency: many methods either involve adding similarly sized models, which slows down unlearning or inference, or require retain data that are difficult to obtain. 3. Robustness: even effective methods may still leak data via extraction techniques. To address these challenges, we propose MEOW, a simple yet effective gradient descent-based unlearning method. Specifically, we use an offline LLM to generate a set of inverted facts. Then, we design a new metric, MEMO, to quantify memorization in LLMs. Finally, based on the signals provided by MEMO, we select the most appropriate set of inverted facts and finetune the model based on them. We evaluate MEOW on the commonly used unlearn benchmark, ToFU, with Llama2-7B-Chat and Phi-1.5B, and test it on both NLU and NLG tasks. Results demonstrate significant improvement of MEOW in forget quality without substantial loss in model utility. Meanwhile, MEOW does not exhibit significant degradation in NLU or NLG capabilities, and there is even a slight improvement in NLU performance.
Progressive Knowledge Graph Completion
Apr 15, 2024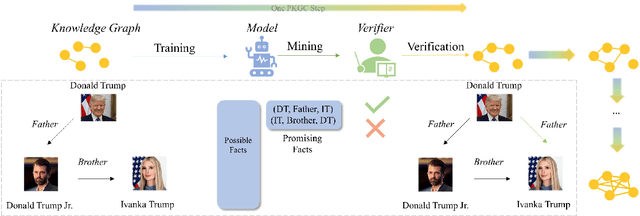

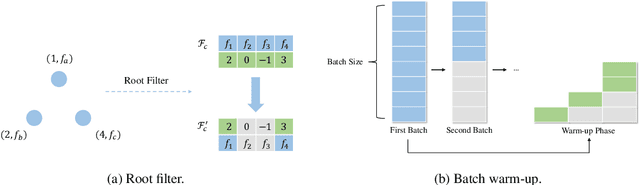

Knowledge Graph Completion (KGC) has emerged as a promising solution to address the issue of incompleteness within Knowledge Graphs (KGs). Traditional KGC research primarily centers on triple classification and link prediction. Nevertheless, we contend that these tasks do not align well with real-world scenarios and merely serve as surrogate benchmarks. In this paper, we investigate three crucial processes relevant to real-world construction scenarios: (a) the verification process, which arises from the necessity and limitations of human verifiers; (b) the mining process, which identifies the most promising candidates for verification; and (c) the training process, which harnesses verified data for subsequent utilization; in order to achieve a transition toward more realistic challenges. By integrating these three processes, we introduce the Progressive Knowledge Graph Completion (PKGC) task, which simulates the gradual completion of KGs in real-world scenarios. Furthermore, to expedite PKGC processing, we propose two acceleration modules: Optimized Top-$k$ algorithm and Semantic Validity Filter. These modules significantly enhance the efficiency of the mining procedure. Our experiments demonstrate that performance in link prediction does not accurately reflect performance in PKGC. A more in-depth analysis reveals the key factors influencing the results and provides potential directions for future research.