 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongR: Unleashing Long-Context Reasoning via Reinforcement Learning with Dense Utility Rewards
Feb 05, 2026Reinforcement Learning has emerged as a key driver for LLM reasoning. This capability is equally pivotal in long-context scenarios--such as long-dialogue understanding and structured data analysis, where the challenge extends beyond consuming tokens to performing rigorous deduction. While existing efforts focus on data synthesis or architectural changes, recent work points out that relying solely on sparse, outcome-only rewards yields limited gains, as such coarse signals are often insufficient to effectively guide the complex long-context reasoning. To address this, we propose LongR, a unified framework that enhances long-context performance by integrating a dynamic "Think-and-Read" mechanism, which interleaves reasoning with document consultation, with a contextual density reward based on relative information gain to quantify the utility of the relevant documents. Empirically, LongR achieves a 9% gain on LongBench v2 and consistent improvements on RULER and InfiniteBench, demonstrating robust efficiency in navigating extensive contexts. Furthermore, LongR consistently enhances performance across diverse RL algorithms (e.g., DAPO, GSPO). Finally, we conduct in-depth analyses to investigate the impact of reasoning chain length on efficiency and the model's robustness against distractors.
Reward Modeling from Natural Language Human Feedback
Jan 12, 2026Reinforcement Learning with Verifiable reward (RLVR) on preference data has become the mainstream approach for training Generative Reward Models (GRMs). Typically in pairwise rewarding tasks, GRMs generate reasoning chains ending with critiques and preference labels, and RLVR then relies on the correctness of the preference labels as the training reward. However, in this paper, we demonstrate that such binary classification tasks make GRMs susceptible to guessing correct outcomes without sound critiques. Consequently, these spurious successes introduce substantial noise into the reward signal, thereby impairing the effectiveness of reinforcement learning. To address this issue, we propose Reward Modeling from Natural Language Human Feedback (RM-NLHF), which leverages natural language feedback to obtain process reward signals, thereby mitigating the problem of limited solution space inherent in binary tasks. Specifically, we compute the similarity between GRM-generated and human critiques as the training reward, which provides more accurate reward signals than outcome-only supervision. Additionally, considering that human critiques are difficult to scale up, we introduce Meta Reward Model (MetaRM) which learns to predict process reward from datasets with human critiques and then generalizes to data without human critiques. Experiments on multiple benchmarks demonstrate that our method consistently outperforms state-of-the-art GRMs trained with outcome-only reward, confirming the superiority of integrating natural language over binary human feedback as supervision.
MIRA: Medical Time Series Foundation Model for Real-World Health Data
Jun 09, 2025


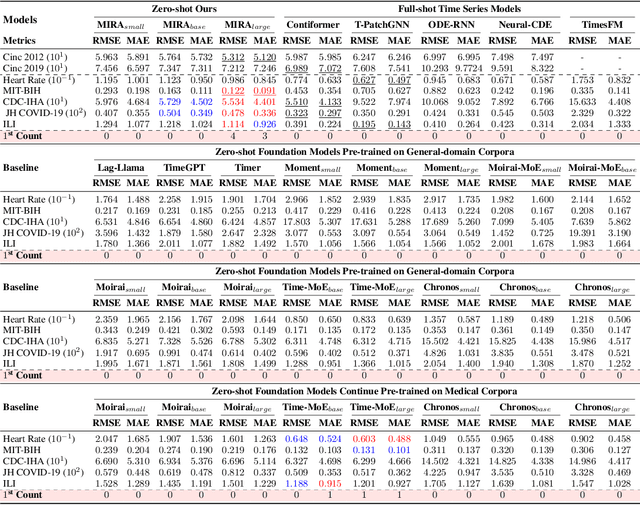
A unified foundation model for medical time series -- pretrained on open access and ethics board-approved medical corpora -- offers the potential to reduce annotation burdens, minimize model customization, and enable robust transfer across clinical institutions, modalities, and tasks, particularly in data-scarce or privacy-constrained environments. However, existing generalist time series foundation models struggle to handle medical time series data due to their inherent challenges, including irregular intervals, heterogeneous sampling rates, and frequent missing values. To address these challenges, we introduce MIRA, a unified foundation model specifically designed for medical time series forecasting. MIRA incorporates a Continuous-Time Rotary Positional Encoding that enables fine-grained modeling of variable time intervals, a frequency-specific mixture-of-experts layer that routes computation across latent frequency regimes to further promote temporal specialization, and a Continuous Dynamics Extrapolation Block based on Neural ODE that models the continuous trajectory of latent states, enabling accurate forecasting at arbitrary target timestamps. Pretrained on a large-scale and diverse medical corpus comprising over 454 billion time points collect from publicly available datasets, MIRA achieves reductions in forecasting errors by an average of 10% and 7% in out-of-distribution and in-distribution scenarios, respectively, when compared to other zero-shot and fine-tuned baselines. We also introduce a comprehensive benchmark spanning multiple downstream clinical tasks, establishing a foundation for future research in medical time series modeling.
Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective
Jan 19, 2025Large Language Models (LLMs) have made notable progress in mathematical reasoning, yet they often rely on single-paradigm reasoning that limits their effectiveness across diverse tasks. In this paper, we introduce Chain-of-Reasoning (CoR), a novel unified framework that integrates multiple reasoning paradigms--Natural Language Reasoning (NLR), Algorithmic Reasoning (AR), and Symbolic Reasoning (SR)--to enable synergistic collaboration. CoR generates multiple potential answers using different reasoning paradigms and synthesizes them into a coherent final solution. We propose a Progressive Paradigm Training (PPT) strategy that allows models to progressively master these paradigms, culminating in the development of CoR-Math-7B. Experimental results demonstrate that CoR-Math-7B significantly outperforms current SOTA models, achieving up to a 41.0% absolute improvement over GPT-4 in theorem proving tasks and a 7.9% improvement over RL-based methods in arithmetic tasks. These results showcase the enhanced mathematical comprehensive ability of our model, achieving significant performance gains on specific tasks and enabling zero-shot generalization across tasks.
URSA: Understanding and Verifying Chain-of-thought Reasoning in Multimodal Mathematics
Jan 08, 2025



Chain-of-thought (CoT) reasoning has been widely applied in the mathematical reasoning of Large Language Models (LLMs). Recently, the introduction of derivative process supervision on CoT trajectories has sparked discussions on enhancing scaling capabilities during test time, thereby boosting the potential of these models. However, in multimodal mathematical reasoning, the scarcity of high-quality CoT training data has hindered existing models from achieving high-precision CoT reasoning and has limited the realization of reasoning potential during test time. In this work, we propose a three-module synthesis strategy that integrates CoT distillation, trajectory-format rewriting, and format unification. It results in a high-quality CoT reasoning instruction fine-tuning dataset in multimodal mathematics, MMathCoT-1M. We comprehensively validate the state-of-the-art (SOTA) performance of the trained URSA-7B model on multiple multimodal mathematical benchmarks. For test-time scaling, we introduce a data synthesis strategy that automatically generates process annotation datasets, known as DualMath-1.1M, focusing on both interpretation and logic. By further training URSA-7B on DualMath-1.1M, we transition from CoT reasoning capabilities to robust supervision abilities. The trained URSA-RM-7B acts as a verifier, effectively enhancing the performance of URSA-7B at test time. URSA-RM-7B also demonstrates excellent out-of-distribution (OOD) verifying capabilities, showcasing its generalization. Model weights, training data and code will be open-sourced.
ShifCon: Enhancing Non-Dominant Language Capabilities with a Shift-based Contrastive Framework
Oct 25, 2024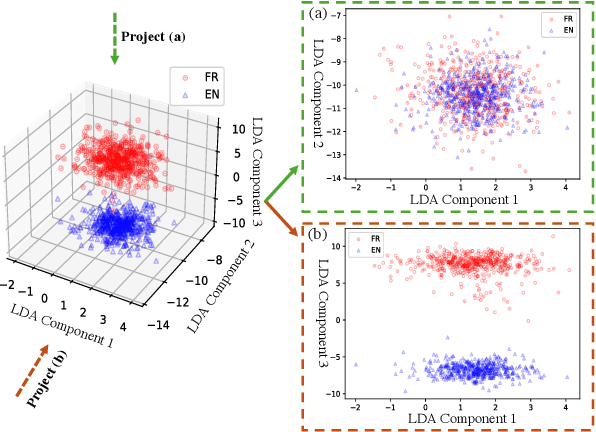
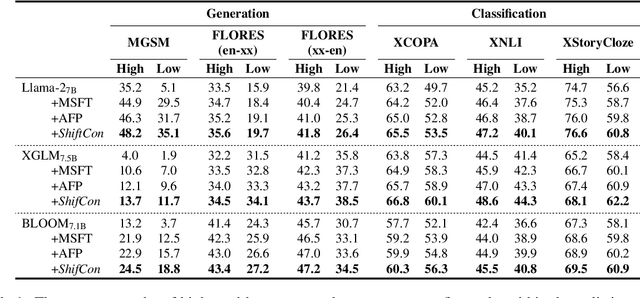
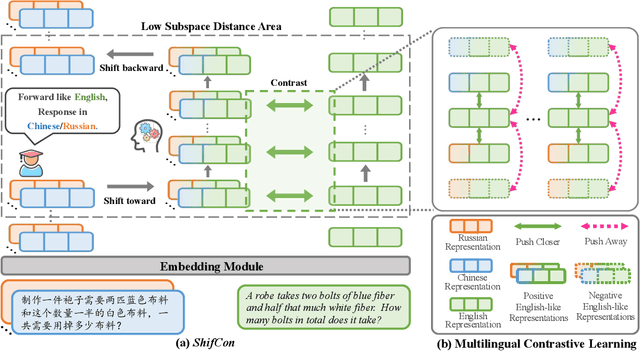
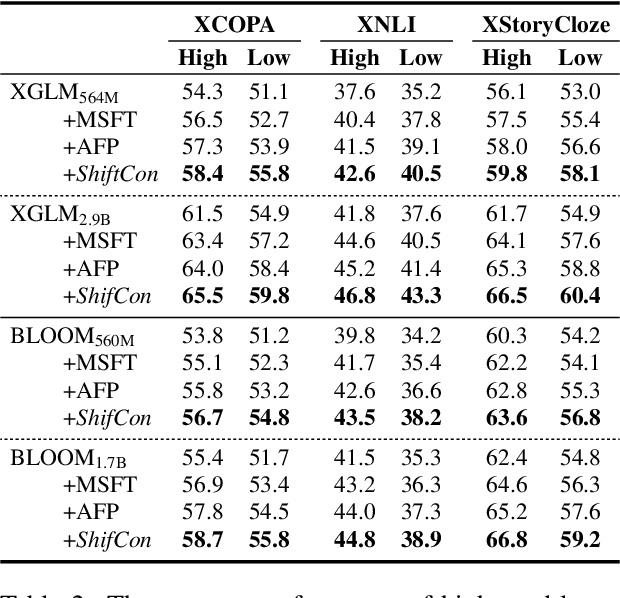
Although fine-tuning Large Language Models (LLMs) with multilingual data can rapidly enhance the multilingual capabilities of LLMs, they still exhibit a performance gap between the dominant language (e.g., English) and non-dominant ones due to the imbalance of training data across languages. To further enhance the performance of non-dominant languages, we propose ShifCon, a Shift-based Contrastive framework that aligns the internal forward process of other languages toward that of the dominant one. Specifically, it shifts the representations of non-dominant languages into the dominant language subspace, allowing them to access relatively rich information encoded in the model parameters. The enriched representations are then shifted back into their original language subspace before generation. Moreover, we introduce a subspace distance metric to pinpoint the optimal layer area for shifting representations and employ multilingual contrastive learning to further enhance the alignment of representations within this area. Experiments demonstrate that our ShifCon framework significantly enhances the performance of non-dominant languages, particularly for low-resource ones. Further analysis offers extra insights to verify the effectiveness of ShifCon and propel future research
EALM: Introducing Multidimensional Ethical Alignment in Conversational Information Retrieval
Oct 02, 2023Artificial intelligence (AI) technologies should adhere to human norms to better serve our society and avoid disseminating harmful or misleading information, particularly in Conversational Information Retrieval (CIR). Previous work, including approaches and datasets, has not always been successful or sufficiently robust in taking human norms into consideration. To this end, we introduce a workflow that integrates ethical alignment, with an initial ethical judgment stage for efficient data screening. To address the need for ethical judgment in CIR, we present the QA-ETHICS dataset, adapted from the ETHICS benchmark, which serves as an evaluation tool by unifying scenarios and label meanings. However, each scenario only considers one ethical concept. Therefore, we introduce the MP-ETHICS dataset to evaluate a scenario under multiple ethical concepts, such as justice and Deontology. In addition, we suggest a new approach that achieves top performance in both binary and multi-label ethical judgment tasks. Our research provides a practical method for introducing ethical alignment into the CIR workflow. The data and code are available at https://github.com/wanng-ide/ealm .