 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURSA: Understanding and Verifying Chain-of-thought Reasoning in Multimodal Mathematics
Jan 08, 2025



Chain-of-thought (CoT) reasoning has been widely applied in the mathematical reasoning of Large Language Models (LLMs). Recently, the introduction of derivative process supervision on CoT trajectories has sparked discussions on enhancing scaling capabilities during test time, thereby boosting the potential of these models. However, in multimodal mathematical reasoning, the scarcity of high-quality CoT training data has hindered existing models from achieving high-precision CoT reasoning and has limited the realization of reasoning potential during test time. In this work, we propose a three-module synthesis strategy that integrates CoT distillation, trajectory-format rewriting, and format unification. It results in a high-quality CoT reasoning instruction fine-tuning dataset in multimodal mathematics, MMathCoT-1M. We comprehensively validate the state-of-the-art (SOTA) performance of the trained URSA-7B model on multiple multimodal mathematical benchmarks. For test-time scaling, we introduce a data synthesis strategy that automatically generates process annotation datasets, known as DualMath-1.1M, focusing on both interpretation and logic. By further training URSA-7B on DualMath-1.1M, we transition from CoT reasoning capabilities to robust supervision abilities. The trained URSA-RM-7B acts as a verifier, effectively enhancing the performance of URSA-7B at test time. URSA-RM-7B also demonstrates excellent out-of-distribution (OOD) verifying capabilities, showcasing its generalization. Model weights, training data and code will be open-sourced.
Incremental Residual Concept Bottleneck Models
Apr 13, 2024



Concept Bottleneck Models (CBMs) map the black-box visual representations extracted by deep neural networks onto a set of interpretable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. Multimodal pre-trained models can match visual representations with textual concept embeddings, allowing for obtaining the interpretable concept bottleneck without the expertise concept annotations. Recent research has focused on the concept bank establishment and the high-quality concept selection. However, it is challenging to construct a comprehensive concept bank through humans or large language models, which severely limits the performance of CBMs. In this work, we propose the Incremental Residual Concept Bottleneck Model (Res-CBM) to address the challenge of concept completeness. Specifically, the residual concept bottleneck model employs a set of optimizable vectors to complete missing concepts, then the incremental concept discovery module converts the complemented vectors with unclear meanings into potential concepts in the candidate concept bank. Our approach can be applied to any user-defined concept bank, as a post-hoc processing method to enhance the performance of any CBMs. Furthermore, to measure the descriptive efficiency of CBMs, the Concept Utilization Efficiency (CUE) metric is proposed. Experiments show that the Res-CBM outperforms the current state-of-the-art methods in terms of both accuracy and efficiency and achieves comparable performance to black-box models across multiple datasets.
Exploring the Mystery of Influential Data for Mathematical Reasoning
Apr 01, 2024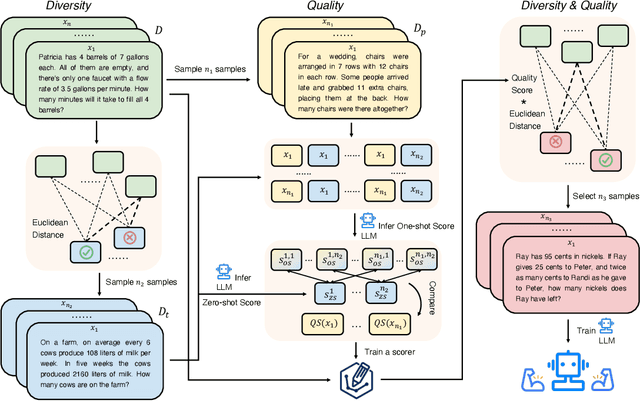
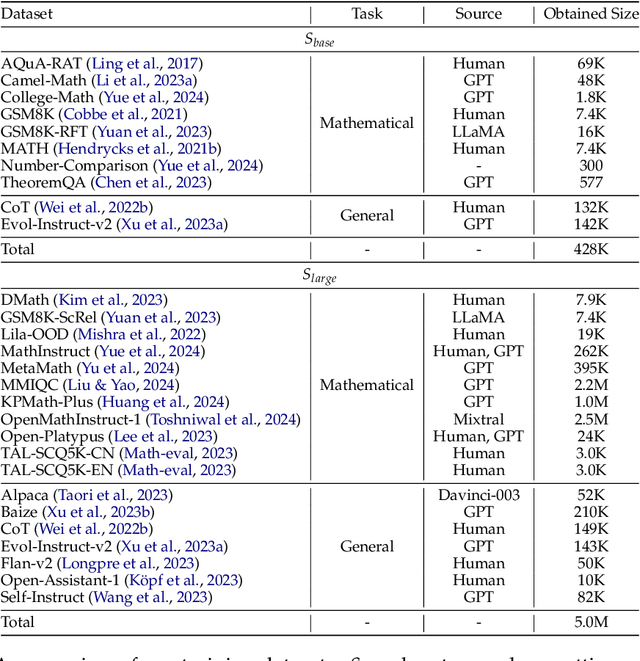

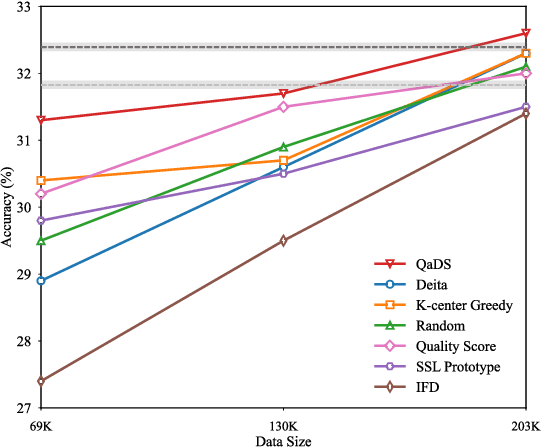
Selecting influential data for fine-tuning on downstream tasks is a key factor for both performance and computation efficiency. Recent works have shown that training with only limited data can show a superior performance on general tasks. However, the feasibility on mathematical reasoning tasks has not been validated. To go further, there exist two open questions for mathematical reasoning: how to select influential data and what is an influential data composition. For the former one, we propose a Quality-aware Diverse Selection (QaDS) strategy adaptable for mathematical reasoning. A comparison with other selection strategies validates the superiority of QaDS. For the latter one, we first enlarge our setting and explore the influential data composition. We conduct a series of experiments and highlight: scaling up reasoning data, and training with general data selected by QaDS is helpful. Then, we define our optimal mixture as OpenMathMix, an influential data mixture with open-source data selected by QaDS. With OpenMathMix, we achieve a state-of-the-art 48.8% accuracy on MATH with 7B base model. Additionally, we showcase the use of QaDS in creating efficient fine-tuning mixtures with various selection ratios, and analyze the quality of a wide range of open-source datasets, which can perform as a reference for future works on mathematical reasoning tasks.
What Large Language Models Bring to Text-rich VQA?
Nov 13, 2023Text-rich VQA, namely Visual Question Answering based on text recognition in the images, is a cross-modal task that requires both image comprehension and text recognition. In this work, we focus on investigating the advantages and bottlenecks of LLM-based approaches in addressing this problem. To address the above concern, we separate the vision and language modules, where we leverage external OCR models to recognize texts in the image and Large Language Models (LLMs) to answer the question given texts. The whole framework is training-free benefiting from the in-context ability of LLMs. This pipeline achieved superior performance compared to the majority of existing Multimodal Large Language Models (MLLM) on four text-rich VQA datasets. Besides, based on the ablation study, we find that LLM brings stronger comprehension ability and may introduce helpful knowledge for the VQA problem. The bottleneck for LLM to address text-rich VQA problems may primarily lie in visual part. We also combine the OCR module with MLLMs and pleasantly find that the combination of OCR module with MLLM also works. It's worth noting that not all MLLMs can comprehend the OCR information, which provides insights into how to train an MLLM that preserves the abilities of LLM.
Hint-enhanced In-Context Learning wakes Large Language Models up for knowledge-intensive tasks
Nov 03, 2023In-context learning (ICL) ability has emerged with the increasing scale of large language models (LLMs), enabling them to learn input-label mappings from demonstrations and perform well on downstream tasks. However, under the standard ICL setting, LLMs may sometimes neglect query-related information in demonstrations, leading to incorrect predictions. To address this limitation, we propose a new paradigm called Hint-enhanced In-Context Learning (HICL) to explore the power of ICL in open-domain question answering, an important form in knowledge-intensive tasks. HICL leverages LLMs' reasoning ability to extract query-related knowledge from demonstrations, then concatenates the knowledge to prompt LLMs in a more explicit way. Furthermore, we track the source of this knowledge to identify specific examples, and introduce a Hint-related Example Retriever (HER) to select informative examples for enhanced demonstrations. We evaluate HICL with HER on 3 open-domain QA benchmarks, and observe average performance gains of 2.89 EM score and 2.52 F1 score on gpt-3.5-turbo, 7.62 EM score and 7.27 F1 score on LLaMA-2-Chat-7B compared with standard setting.
Multimodal Prototype-Enhanced Network for Few-Shot Action Recognition
Dec 09, 2022Current methods for few-shot action recognition mainly fall into the metric learning framework following ProtoNet. However, they either ignore the effect of representative prototypes or fail to enhance the prototypes with multimodal information adequately. In this work, we propose a novel Multimodal Prototype-Enhanced Network (MORN) to use the semantic information of label texts as multimodal information to enhance prototypes, including two modality flows. A CLIP visual encoder is introduced in the visual flow, and visual prototypes are computed by the Temporal-Relational CrossTransformer (TRX) module. A frozen CLIP text encoder is introduced in the text flow, and a semantic-enhanced module is used to enhance text features. After inflating, text prototypes are obtained. The final multimodal prototypes are then computed by a multimodal prototype-enhanced module. Besides, there exist no evaluation metrics to evaluate the quality of prototypes. To the best of our knowledge, we are the first to propose a prototype evaluation metric called Prototype Similarity Difference (PRIDE), which is used to evaluate the performance of prototypes in discriminating different categories. We conduct extensive experiments on four popular datasets. MORN achieves state-of-the-art results on HMDB51, UCF101, Kinetics and SSv2. MORN also performs well on PRIDE, and we explore the correlation between PRIDE and accuracy.