 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Mystery of Influential Data for Mathematical Reasoning
Paper and Code
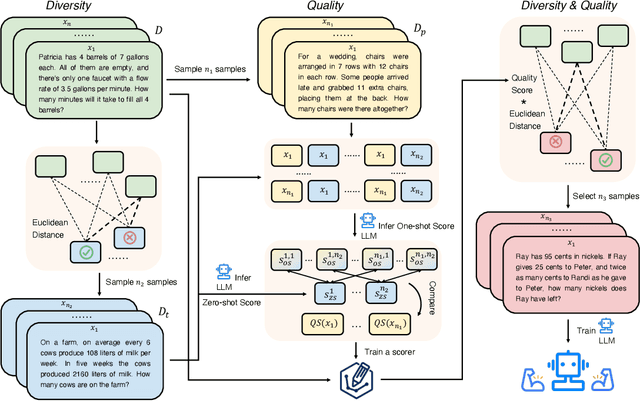
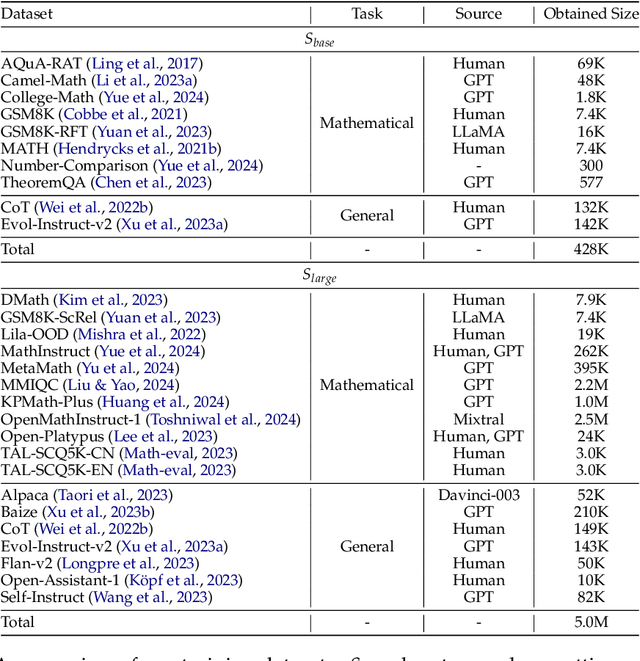

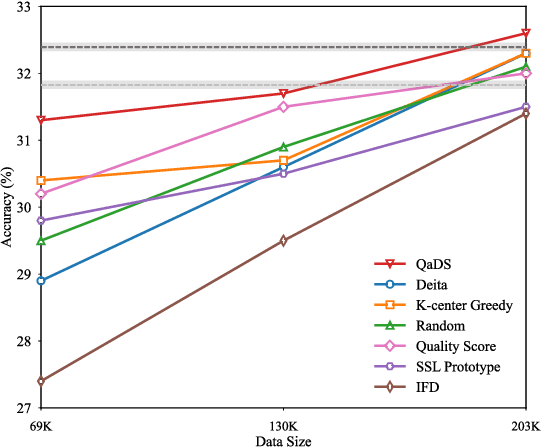
Selecting influential data for fine-tuning on downstream tasks is a key factor for both performance and computation efficiency. Recent works have shown that training with only limited data can show a superior performance on general tasks. However, the feasibility on mathematical reasoning tasks has not been validated. To go further, there exist two open questions for mathematical reasoning: how to select influential data and what is an influential data composition. For the former one, we propose a Quality-aware Diverse Selection (QaDS) strategy adaptable for mathematical reasoning. A comparison with other selection strategies validates the superiority of QaDS. For the latter one, we first enlarge our setting and explore the influential data composition. We conduct a series of experiments and highlight: scaling up reasoning data, and training with general data selected by QaDS is helpful. Then, we define our optimal mixture as OpenMathMix, an influential data mixture with open-source data selected by QaDS. With OpenMathMix, we achieve a state-of-the-art 48.8% accuracy on MATH with 7B base model. Additionally, we showcase the use of QaDS in creating efficient fine-tuning mixtures with various selection ratios, and analyze the quality of a wide range of open-source datasets, which can perform as a reference for future works on mathematical reasoning tasks.