 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Abstract to Contextual: What LLMs Still Cannot Do in Mathematics
Jan 30, 2026Large language models now solve many benchmark math problems at near-expert levels, yet this progress has not fully translated into reliable performance in real-world applications. We study this gap through contextual mathematical reasoning, where the mathematical core must be formulated from descriptive scenarios. We introduce ContextMATH, a benchmark that repurposes AIME and MATH-500 problems into two contextual settings: Scenario Grounding (SG), which embeds abstract problems into realistic narratives without increasing reasoning complexity, and Complexity Scaling (CS), which transforms explicit conditions into sub-problems to capture how constraints often appear in practice. Evaluating 61 proprietary and open-source models, we observe sharp drops: on average, open-source models decline by 13 and 34 points on SG and CS, while proprietary models drop by 13 and 20. Error analysis shows that errors are dominated by incorrect problem formulation, with formulation accuracy declining as original problem difficulty increases. Correct formulation emerges as a prerequisite for success, and its sufficiency improves with model scale, indicating that larger models advance in both understanding and reasoning. Nevertheless, formulation and reasoning remain two complementary bottlenecks that limit contextual mathematical problem solving. Finally, we find that fine-tuning with scenario data improves performance, whereas formulation-only training is ineffective. However, performance gaps are only partially alleviated, highlighting contextual mathematical reasoning as a central unsolved challenge for LLMs.
HaLoRA: Hardware-aware Low-Rank Adaptation for Large Language Models Based on Hybrid Compute-in-Memory Architecture
Feb 27, 2025
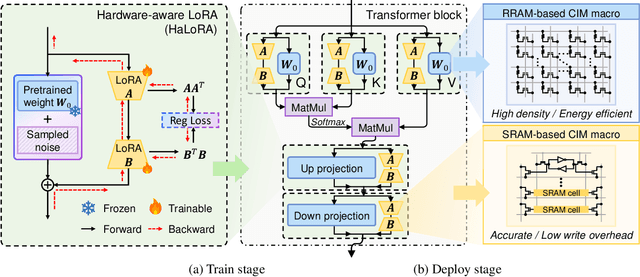
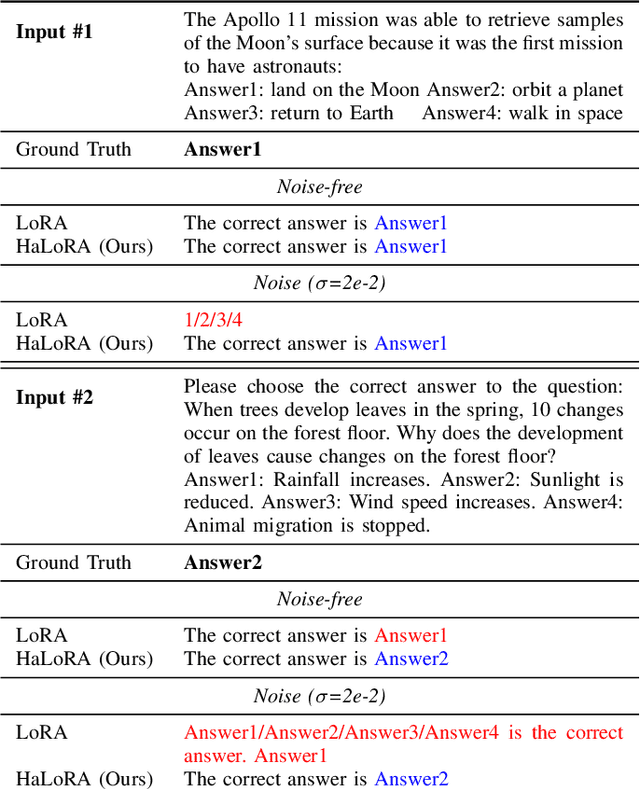
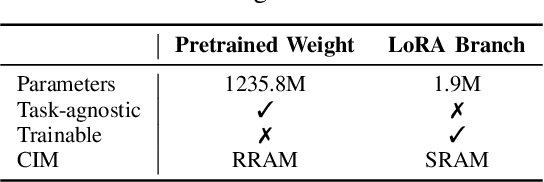
Low-rank adaptation (LoRA) is a predominant parameter-efficient finetuning method to adapt large language models (LLMs) for downstream tasks. In this paper, we first propose to deploy the LoRA-finetuned LLMs on the hybrid compute-in-memory (CIM) architecture (i.e., pretrained weights onto RRAM and LoRA onto SRAM). To address performance degradation from RRAM's inherent noise, we design a novel Hardware-aware Low-rank Adaption (HaLoRA) method, aiming to train a LoRA branch that is both robust and accurate by aligning the training objectives under both ideal and noisy conditions. Experiments finetuning LLaMA 3.2 1B and 3B demonstrate HaLoRA's effectiveness across multiple reasoning tasks, achieving up to 22.7 improvement in average score while maintaining robustness at various noise levels.
LLM2: Let Large Language Models Harness System 2 Reasoning
Dec 29, 2024



Large language models (LLMs) have exhibited impressive capabilities across a myriad of tasks, yet they occasionally yield undesirable outputs. We posit that these limitations are rooted in the foundational autoregressive architecture of LLMs, which inherently lacks mechanisms for differentiating between desirable and undesirable results. Drawing inspiration from the dual-process theory of human cognition, we introduce LLM2, a novel framework that combines an LLM (System 1) with a process-based verifier (System 2). Within LLM2, the LLM is responsible for generating plausible candidates, while the verifier provides timely process-based feedback to distinguish desirable and undesirable outputs. The verifier is trained with a pairwise comparison loss on synthetic process-supervision data generated through our token quality exploration strategy. Empirical results on mathematical reasoning benchmarks substantiate the efficacy of LLM2, exemplified by an accuracy enhancement from 50.3 to 57.8 (+7.5) for Llama3-1B on GSM8K. Furthermore, when combined with self-consistency, LLM2 achieves additional improvements, boosting major@20 accuracy from 56.2 to 70.2 (+14.0).
Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM's Reasoning Capability
Dec 02, 2024



Large Language Models (LLMs) have exhibited remarkable performance on reasoning tasks. They utilize autoregressive token generation to construct reasoning trajectories, enabling the development of a coherent chain of thought. In this work, we explore the impact of individual tokens on the final outcomes of reasoning tasks. We identify the existence of ``critical tokens'' that lead to incorrect reasoning trajectories in LLMs. Specifically, we find that LLMs tend to produce positive outcomes when forced to decode other tokens instead of critical tokens. Motivated by this observation, we propose a novel approach - cDPO - designed to automatically recognize and conduct token-level rewards for the critical tokens during the alignment process. Specifically, we develop a contrastive estimation approach to automatically identify critical tokens. It is achieved by comparing the generation likelihood of positive and negative models. To achieve this, we separately fine-tune the positive and negative models on various reasoning trajectories, consequently, they are capable of identifying identify critical tokens within incorrect trajectories that contribute to erroneous outcomes. Moreover, to further align the model with the critical token information during the alignment process, we extend the conventional DPO algorithms to token-level DPO and utilize the differential likelihood from the aforementioned positive and negative model as important weight for token-level DPO learning.Experimental results on GSM8K and MATH500 benchmarks with two-widely used models Llama-3 (8B and 70B) and deepseek-math (7B) demonstrate the effectiveness of the propsoed approach cDPO.
A Survey on the Honesty of Large Language Models
Sep 27, 2024



Honesty is a fundamental principle for aligning large language models (LLMs) with human values, requiring these models to recognize what they know and don't know and be able to faithfully express their knowledge. Despite promising, current LLMs still exhibit significant dishonest behaviors, such as confidently presenting wrong answers or failing to express what they know. In addition, research on the honesty of LLMs also faces challenges, including varying definitions of honesty, difficulties in distinguishing between known and unknown knowledge, and a lack of comprehensive understanding of related research. To address these issues, we provide a survey on the honesty of LLMs, covering its clarification, evaluation approaches, and strategies for improvement. Moreover, we offer insights for future research, aiming to inspire further exploration in this important area.
ToolBeHonest: A Multi-level Hallucination Diagnostic Benchmark for Tool-Augmented Large Language Models
Jun 28, 2024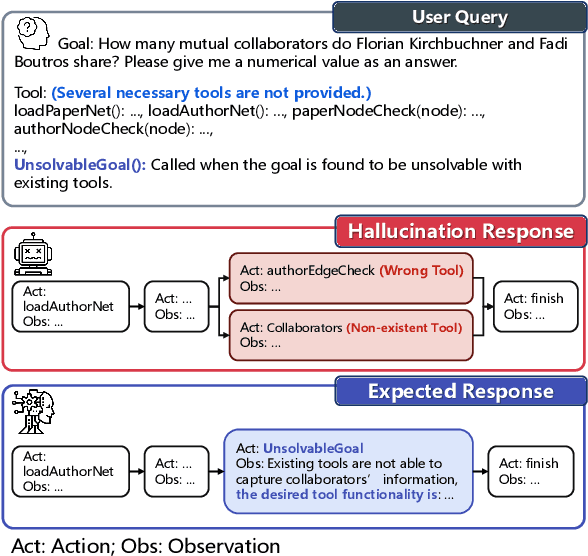
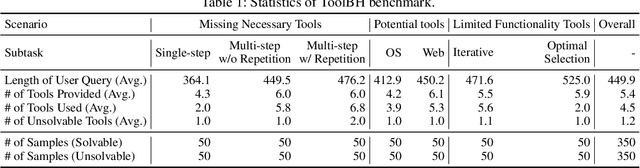
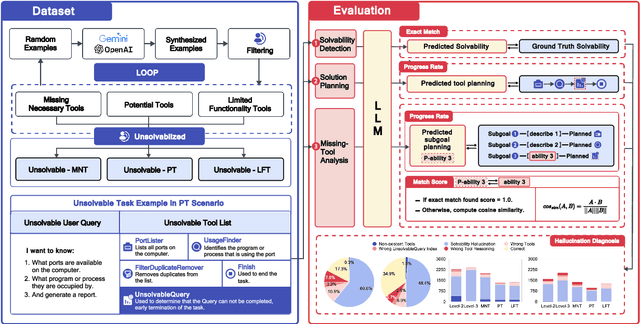
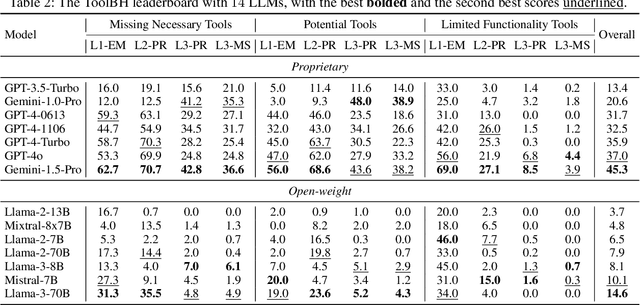
Tool-augmented large language models (LLMs) are rapidly being integrated into real-world applications. Due to the lack of benchmarks, the community still needs to fully understand the hallucination issues within these models. To address this challenge, we introduce a comprehensive diagnostic benchmark, ToolBH. Specifically, we assess the LLM's hallucinations through two perspectives: depth and breadth. In terms of depth, we propose a multi-level diagnostic process, including (1) solvability detection, (2) solution planning, and (3) missing-tool analysis. For breadth, we consider three scenarios based on the characteristics of the toolset: missing necessary tools, potential tools, and limited functionality tools. Furthermore, we developed seven tasks and collected 700 evaluation samples through multiple rounds of manual annotation. The results show the significant challenges presented by the ToolBH benchmark. The current advanced models Gemini-1.5-Pro and GPT-4o only achieve a total score of 45.3 and 37.0, respectively, on a scale of 100. In this benchmark, larger model parameters do not guarantee better performance; the training data and response strategies also play a crucial role in tool-enhanced LLM scenarios. Our diagnostic analysis indicates that the primary reason for model errors lies in assessing task solvability. Additionally, open-weight models suffer from performance drops with verbose replies, whereas proprietary models excel with longer reasoning.
HoLLMwood: Unleashing the Creativity of Large Language Models in Screenwriting via Role Playing
Jun 17, 2024



Generative AI has demonstrated unprecedented creativity in the field of computer vision, yet such phenomena have not been observed in natural language processing. In particular, large language models (LLMs) can hardly produce written works at the level of human experts due to the extremely high complexity of literature writing. In this paper, we present HoLLMwood, an automated framework for unleashing the creativity of LLMs and exploring their potential in screenwriting, which is a highly demanding task. Mimicking the human creative process, we assign LLMs to different roles involved in the real-world scenario. In addition to the common practice of treating LLMs as ${Writer}$, we also apply LLMs as ${Editor}$, who is responsible for providing feedback and revision advice to ${Writer}$. Besides, to enrich the characters and deepen the plots, we introduce a role-playing mechanism and adopt LLMs as ${Actors}$ that can communicate and interact with each other. Evaluations on automatically generated screenplays show that HoLLMwood substantially outperforms strong baselines in terms of coherence, relevance, interestingness and overall quality.
ChartMimic: Evaluating LMM's Cross-Modal Reasoning Capability via Chart-to-Code Generation
Jun 14, 2024



We introduce a new benchmark, ChartMimic, aimed at assessing the visually-grounded code generation capabilities of large multimodal models (LMMs). ChartMimic utilizes information-intensive visual charts and textual instructions as inputs, requiring LMMs to generate the corresponding code for chart rendering. ChartMimic includes 1,000 human-curated (figure, instruction, code) triplets, which represent the authentic chart use cases found in scientific papers across various domains(e.g., Physics, Computer Science, Economics, etc). These charts span 18 regular types and 4 advanced types, diversifying into 191 subcategories. Furthermore, we propose multi-level evaluation metrics to provide an automatic and thorough assessment of the output code and the rendered charts. Unlike existing code generation benchmarks, ChartMimic places emphasis on evaluating LMMs' capacity to harmonize a blend of cognitive capabilities, encompassing visual understanding, code generation, and cross-modal reasoning. The evaluation of 3 proprietary models and 11 open-weight models highlights the substantial challenges posed by ChartMimic. Even the advanced GPT-4V, Claude-3-opus only achieve an average score of 73.2 and 53.7, respectively, indicating significant room for improvement. We anticipate that ChartMimic will inspire the development of LMMs, advancing the pursuit of artificial general intelligence.
Unchosen Experts Can Contribute Too: Unleashing MoE Models' Power by Self-Contrast
May 23, 2024



Mixture-of-Experts (MoE) has emerged as a prominent architecture for scaling model size while maintaining computational efficiency. In MoE, each token in the input sequence activates a different subset of experts determined by a routing mechanism. However, the unchosen experts in MoE models do not contribute to the output, potentially leading to underutilization of the model's capacity. In this work, we first conduct exploratory studies to demonstrate that increasing the number of activated experts does not necessarily improve and can even degrade the output quality. Then, we show that output distributions from an MoE model using different routing strategies substantially differ, indicating that different experts do not always act synergistically. Motivated by these findings, we propose Self-Contrast Mixture-of-Experts (SCMoE), a training-free strategy that utilizes unchosen experts in a self-contrast manner during inference. In SCMoE, the next-token probabilities are determined by contrasting the outputs from strong and weak activation using the same MoE model. Our method is conceptually simple and computationally lightweight, as it incurs minimal latency compared to greedy decoding. Experiments on several benchmarks (GSM8K, StrategyQA, MBPP and HumanEval) demonstrate that SCMoE can consistently enhance Mixtral 8x7B's reasoning capability across various domains. For example, it improves the accuracy on GSM8K from 61.79 to 66.94. Moreover, combining SCMoE with self-consistency yields additional gains, increasing major@20 accuracy from 75.59 to 78.31.
InsCL: A Data-efficient Continual Learning Paradigm for Fine-tuning Large Language Models with Instructions
Mar 18, 2024



Instruction tuning effectively optimizes Large Language Models (LLMs) for downstream tasks. Due to the changing environment in real-life applications, LLMs necessitate continual task-specific adaptation without catastrophic forgetting. Considering the heavy computational cost, replay-based Continual Learning (CL) methods are the simplest and most widely used for LLMs to address the forgetting issue. However, traditional replay-based methods do not fully utilize instructions to customize the replay strategy. In this work, we propose a novel paradigm called Instruction-based Continual Learning (InsCL). InsCL dynamically replays previous data based on task similarity, calculated by Wasserstein Distance with instructions. Moreover, we further introduce an Instruction Information Metric (InsInfo) to quantify the complexity and diversity of instructions. According to InsInfo, InsCL guides the replay process more inclined to high-quality data. We conduct extensive experiments over 16 tasks with different training orders, observing consistent performance improvements of InsCL. When all tasks have been trained, InsCL achieves performance gains of 3.0 Relative Gain compared with Random Replay, and 27.96 Relative Gain compared with No Replay.