 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartMimic: Evaluating LMM's Cross-Modal Reasoning Capability via Chart-to-Code Generation
Jun 14, 2024



We introduce a new benchmark, ChartMimic, aimed at assessing the visually-grounded code generation capabilities of large multimodal models (LMMs). ChartMimic utilizes information-intensive visual charts and textual instructions as inputs, requiring LMMs to generate the corresponding code for chart rendering. ChartMimic includes 1,000 human-curated (figure, instruction, code) triplets, which represent the authentic chart use cases found in scientific papers across various domains(e.g., Physics, Computer Science, Economics, etc). These charts span 18 regular types and 4 advanced types, diversifying into 191 subcategories. Furthermore, we propose multi-level evaluation metrics to provide an automatic and thorough assessment of the output code and the rendered charts. Unlike existing code generation benchmarks, ChartMimic places emphasis on evaluating LMMs' capacity to harmonize a blend of cognitive capabilities, encompassing visual understanding, code generation, and cross-modal reasoning. The evaluation of 3 proprietary models and 11 open-weight models highlights the substantial challenges posed by ChartMimic. Even the advanced GPT-4V, Claude-3-opus only achieve an average score of 73.2 and 53.7, respectively, indicating significant room for improvement. We anticipate that ChartMimic will inspire the development of LMMs, advancing the pursuit of artificial general intelligence.
Promoting Open-domain Dialogue Generation through Learning Pattern Information between Contexts and Responses
Sep 06, 2023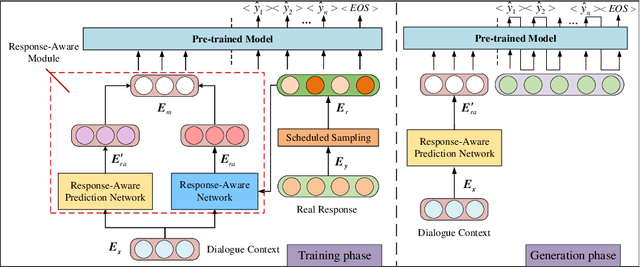
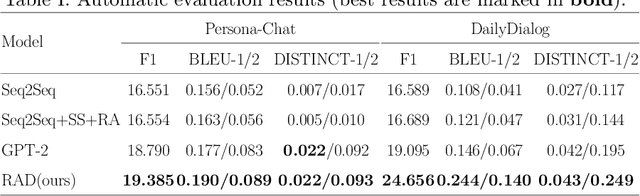
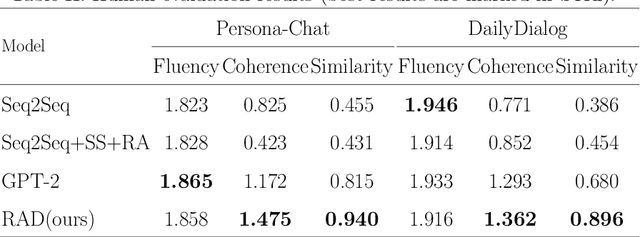
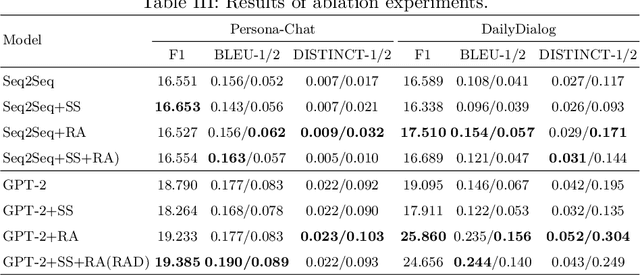
Recently, utilizing deep neural networks to build the opendomain dialogue models has become a hot topic. However, the responses generated by these models suffer from many problems such as responses not being contextualized and tend to generate generic responses that lack information content, damaging the user's experience seriously. Therefore, many studies try introducing more information into the dialogue models to make the generated responses more vivid and informative. Unlike them, this paper improves the quality of generated responses by learning the implicit pattern information between contexts and responses in the training samples. In this paper, we first build an open-domain dialogue model based on the pre-trained language model (i.e., GPT-2). And then, an improved scheduled sampling method is proposed for pre-trained models, by which the responses can be used to guide the response generation in the training phase while avoiding the exposure bias problem. More importantly, we design a response-aware mechanism for mining the implicit pattern information between contexts and responses so that the generated replies are more diverse and approximate to human replies. Finally, we evaluate the proposed model (RAD) on the Persona-Chat and DailyDialog datasets; and the experimental results show that our model outperforms the baselines on most automatic and manual metrics.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
The Second Monocular Depth Estimation Challenge
Apr 26, 2023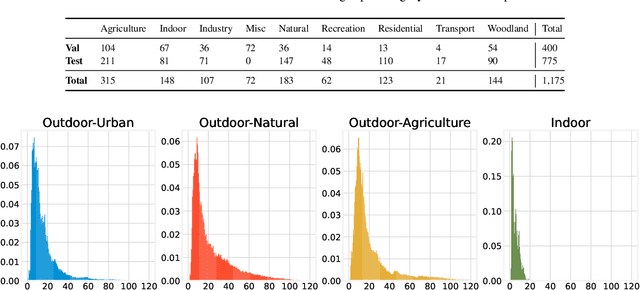
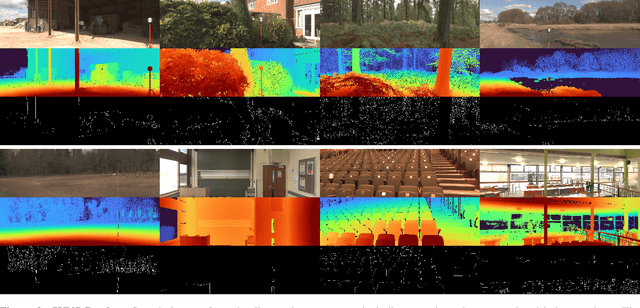
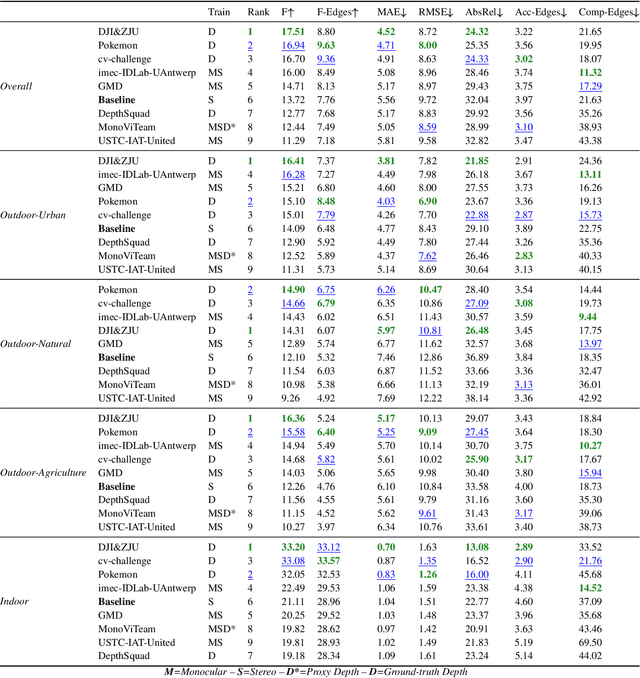
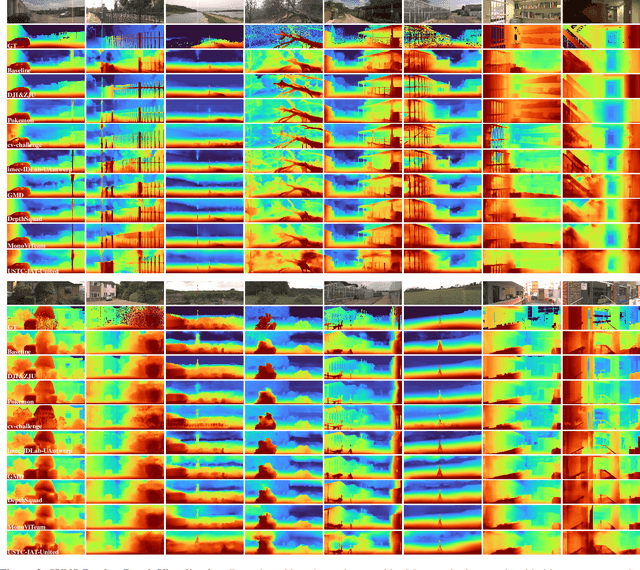
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.