 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenTe: Generative Real-world Terrains for General Legged Robot Locomotion Control
Apr 14, 2025Developing bipedal robots capable of traversing diverse real-world terrains presents a fundamental robotics challenge, as existing methods using predefined height maps and static environments fail to address the complexity of unstructured landscapes. To bridge this gap, we propose GenTe, a framework for generating physically realistic and adaptable terrains to train generalizable locomotion policies. GenTe constructs an atomic terrain library that includes both geometric and physical terrains, enabling curriculum training for reinforcement learning-based locomotion policies. By leveraging function-calling techniques and reasoning capabilities of Vision-Language Models (VLMs), GenTe generates complex, contextually relevant terrains from textual and graphical inputs. The framework introduces realistic force modeling for terrain interactions, capturing effects such as soil sinkage and hydrodynamic resistance. To the best of our knowledge, GenTe is the first framework that systemically generates simulation environments for legged robot locomotion control. Additionally, we introduce a benchmark of 100 generated terrains. Experiments demonstrate improved generalization and robustness in bipedal robot locomotion.
EmbodiedAgent: A Scalable Hierarchical Approach to Overcome Practical Challenge in Multi-Robot Control
Apr 14, 2025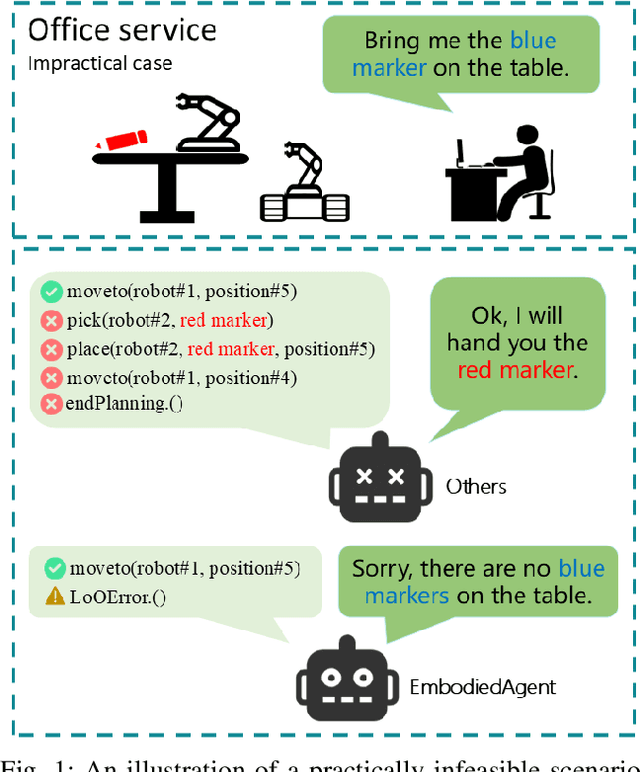



This paper introduces EmbodiedAgent, a hierarchical framework for heterogeneous multi-robot control. EmbodiedAgent addresses critical limitations of hallucination in impractical tasks. Our approach integrates a next-action prediction paradigm with a structured memory system to decompose tasks into executable robot skills while dynamically validating actions against environmental constraints. We present MultiPlan+, a dataset of more than 18,000 annotated planning instances spanning 100 scenarios, including a subset of impractical cases to mitigate hallucination. To evaluate performance, we propose the Robot Planning Assessment Schema (RPAS), combining automated metrics with LLM-aided expert grading. Experiments demonstrate EmbodiedAgent's superiority over state-of-the-art models, achieving 71.85% RPAS score. Real-world validation in an office service task highlights its ability to coordinate heterogeneous robots for long-horizon objectives.
ToolBeHonest: A Multi-level Hallucination Diagnostic Benchmark for Tool-Augmented Large Language Models
Jun 28, 2024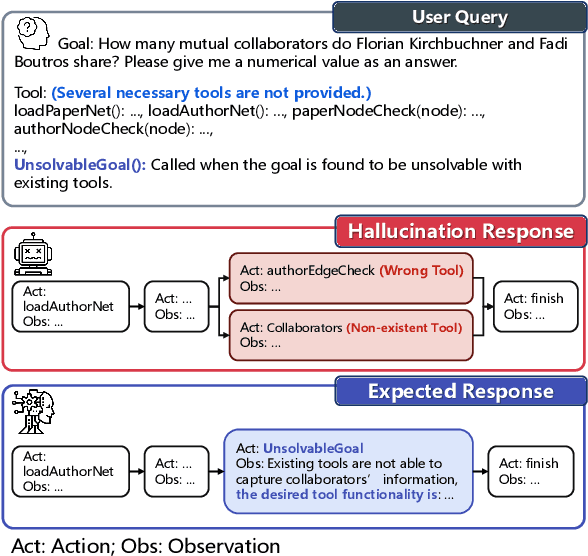
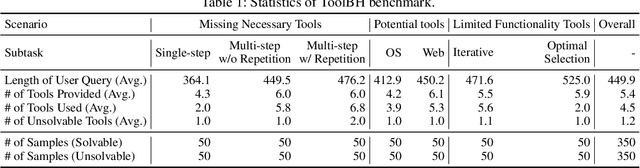
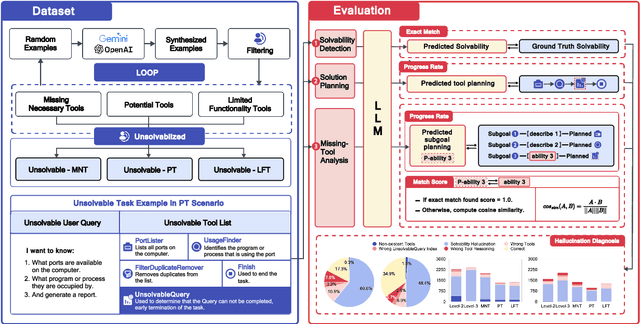
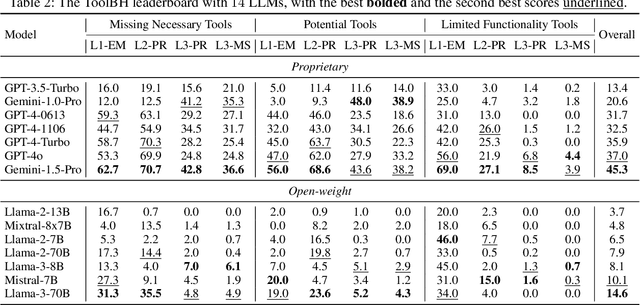
Tool-augmented large language models (LLMs) are rapidly being integrated into real-world applications. Due to the lack of benchmarks, the community still needs to fully understand the hallucination issues within these models. To address this challenge, we introduce a comprehensive diagnostic benchmark, ToolBH. Specifically, we assess the LLM's hallucinations through two perspectives: depth and breadth. In terms of depth, we propose a multi-level diagnostic process, including (1) solvability detection, (2) solution planning, and (3) missing-tool analysis. For breadth, we consider three scenarios based on the characteristics of the toolset: missing necessary tools, potential tools, and limited functionality tools. Furthermore, we developed seven tasks and collected 700 evaluation samples through multiple rounds of manual annotation. The results show the significant challenges presented by the ToolBH benchmark. The current advanced models Gemini-1.5-Pro and GPT-4o only achieve a total score of 45.3 and 37.0, respectively, on a scale of 100. In this benchmark, larger model parameters do not guarantee better performance; the training data and response strategies also play a crucial role in tool-enhanced LLM scenarios. Our diagnostic analysis indicates that the primary reason for model errors lies in assessing task solvability. Additionally, open-weight models suffer from performance drops with verbose replies, whereas proprietary models excel with longer reasoning.