 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Story World Simulation with Continuous Character Customization
Mar 17, 2026Story visualization has gained increasing attention in computer vision. However, current methods often fail to achieve a synergy between accurate character customization, semantic alignment, and continuous integration of new identities. To tackle this challenge, in this paper we present EverTale, a story world simulator for continuous story character customization. We first propose an All-in-One-World Character Integrator to achieve continuous character adaptation within unified LoRA module, eliminating the need for per-character optimization modules of previous methods. Then, we incorporate a Character Quality Gate via MLLM-as-Judge to ensure the fidelity of each character adaptation process through chain-of-thought reasoning, determining whether the model can proceed to the next character or require additional training on the current one. We also introduce a Character-Aware Region-Focus Sampling strategy to address the identity degradation and layout conflicts in existing multi-character visual storytelling, ensuring natural multi-character generation by harmonizing local character-specific details with global scene context with higher efficiency. Experimental results show that our EverTale achieves superior performance against a wider range of compared methods on both single- and multi-character story visualization. Codes will be available.
Ψ-Arena: Interactive Assessment and Optimization of LLM-based Psychological Counselors with Tripartite Feedback
May 06, 2025Large language models (LLMs) have shown promise in providing scalable mental health support, while evaluating their counseling capability remains crucial to ensure both efficacy and safety. Existing evaluations are limited by the static assessment that focuses on knowledge tests, the single perspective that centers on user experience, and the open-loop framework that lacks actionable feedback. To address these issues, we propose {\Psi}-Arena, an interactive framework for comprehensive assessment and optimization of LLM-based counselors, featuring three key characteristics: (1) Realistic arena interactions that simulate real-world counseling through multi-stage dialogues with psychologically profiled NPC clients, (2) Tripartite evaluation that integrates assessments from the client, counselor, and supervisor perspectives, and (3) Closed-loop optimization that iteratively improves LLM counselors using diagnostic feedback. Experiments across eight state-of-the-art LLMs show significant performance variations in different real-world scenarios and evaluation perspectives. Moreover, reflection-based optimization results in up to a 141% improvement in counseling performance. We hope PsychoArena provides a foundational resource for advancing reliable and human-aligned LLM applications in mental healthcare.
Crisp: Cognitive Restructuring of Negative Thoughts through Multi-turn Supportive Dialogues
Apr 24, 2025Cognitive Restructuring (CR) is a psychotherapeutic process aimed at identifying and restructuring an individual's negative thoughts, arising from mental health challenges, into more helpful and positive ones via multi-turn dialogues. Clinician shortage and stigma urge the development of human-LLM interactive psychotherapy for CR. Yet, existing efforts implement CR via simple text rewriting, fixed-pattern dialogues, or a one-shot CR workflow, failing to align with the psychotherapeutic process for effective CR. To address this gap, we propose CRDial, a novel framework for CR, which creates multi-turn dialogues with specifically designed identification and restructuring stages of negative thoughts, integrates sentence-level supportive conversation strategies, and adopts a multi-channel loop mechanism to enable iterative CR. With CRDial, we distill Crisp, a large-scale and high-quality bilingual dialogue dataset, from LLM. We then train Crispers, Crisp-based conversational LLMs for CR, at 7B and 14B scales. Extensive human studies show the superiority of Crispers in pointwise, pairwise, and intervention evaluations.
LANID: LLM-assisted New Intent Discovery
Mar 31, 2025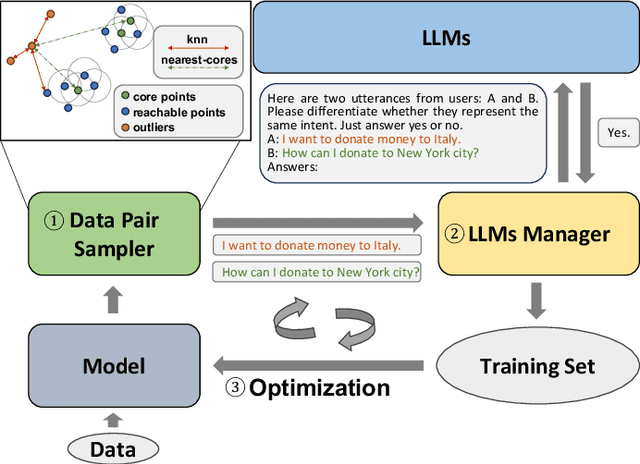

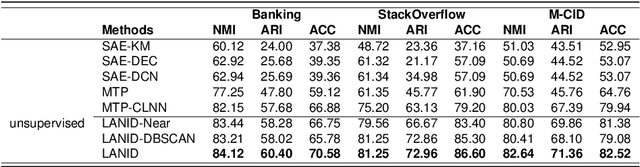
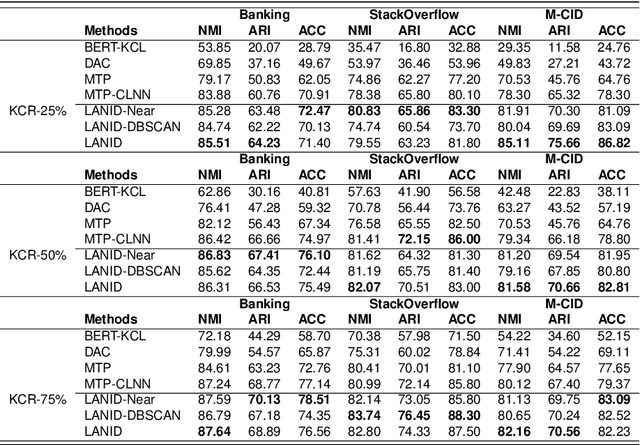
Task-oriented Dialogue Systems (TODS) often face the challenge of encountering new intents. New Intent Discovery (NID) is a crucial task that aims to identify these novel intents while maintaining the capability to recognize existing ones. Previous efforts to adapt TODS to new intents have struggled with inadequate semantic representation or have depended on external knowledge, which is often not scalable or flexible. Recently, Large Language Models (LLMs) have demonstrated strong zero-shot capabilities; however, their scale can be impractical for real-world applications that involve extensive queries. To address the limitations of existing NID methods by leveraging LLMs, we propose LANID, a framework that enhances the semantic representation of lightweight NID encoders with the guidance of LLMs. Specifically, LANID employs the $K$-nearest neighbors and Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithms to sample selective utterance pairs from the training set. It then queries an LLM to ascertain the relationships between these pairs. The data produced from this process is utilized to design a contrastive fine-tuning task, which is then used to train a small encoder with a contrastive triplet loss. Our experimental results demonstrate the efficacy of the proposed method across three distinct NID datasets, surpassing strong baselines in both unsupervised and semi-supervised settings. Our code is available at https://github.com/floatSDSDS/LANID.
EasyCraft: A Robust and Efficient Framework for Automatic Avatar Crafting
Mar 03, 2025Character customization, or 'face crafting,' is a vital feature in role-playing games (RPGs), enhancing player engagement by enabling the creation of personalized avatars. Existing automated methods often struggle with generalizability across diverse game engines due to their reliance on the intermediate constraints of specific image domain and typically support only one type of input, either text or image. To overcome these challenges, we introduce EasyCraft, an innovative end-to-end feedforward framework that automates character crafting by uniquely supporting both text and image inputs. Our approach employs a translator capable of converting facial images of any style into crafting parameters. We first establish a unified feature distribution in the translator's image encoder through self-supervised learning on a large-scale dataset, enabling photos of any style to be embedded into a unified feature representation. Subsequently, we map this unified feature distribution to crafting parameters specific to a game engine, a process that can be easily adapted to most game engines and thus enhances EasyCraft's generalizability. By integrating text-to-image techniques with our translator, EasyCraft also facilitates precise, text-based character crafting. EasyCraft's ability to integrate diverse inputs significantly enhances the versatility and accuracy of avatar creation. Extensive experiments on two RPG games demonstrate the effectiveness of our method, achieving state-of-the-art results and facilitating adaptability across various avatar engines.
CharacterBench: Benchmarking Character Customization of Large Language Models
Dec 16, 2024



Character-based dialogue (aka role-playing) enables users to freely customize characters for interaction, which often relies on LLMs, raising the need to evaluate LLMs' character customization capability. However, existing benchmarks fail to ensure a robust evaluation as they often only involve a single character category or evaluate limited dimensions. Moreover, the sparsity of character features in responses makes feature-focused generative evaluation both ineffective and inefficient. To address these issues, we propose CharacterBench, the largest bilingual generative benchmark, with 22,859 human-annotated samples covering 3,956 characters from 25 detailed character categories. We define 11 dimensions of 6 aspects, classified as sparse and dense dimensions based on whether character features evaluated by specific dimensions manifest in each response. We enable effective and efficient evaluation by crafting tailored queries for each dimension to induce characters' responses related to specific dimensions. Further, we develop CharacterJudge model for cost-effective and stable evaluations. Experiments show its superiority over SOTA automatic judges (e.g., GPT-4) and our benchmark's potential to optimize LLMs' character customization. Our repository is at https://github.com/thu-coai/CharacterBench.
StoryWeaver: A Unified World Model for Knowledge-Enhanced Story Character Customization
Dec 10, 2024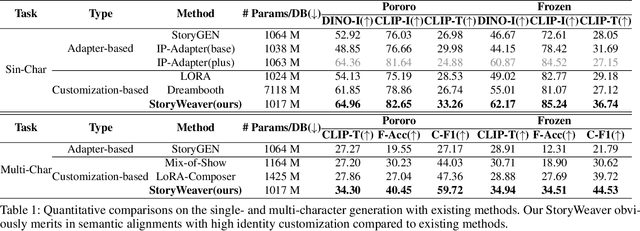
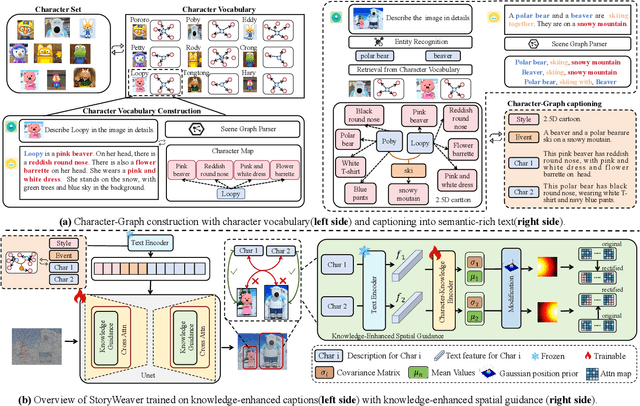
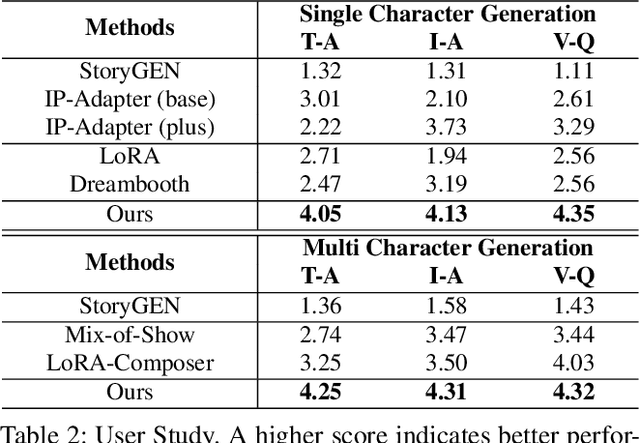

Story visualization has gained increasing attention in artificial intelligence. However, existing methods still struggle with maintaining a balance between character identity preservation and text-semantics alignment, largely due to a lack of detailed semantic modeling of the story scene. To tackle this challenge, we propose a novel knowledge graph, namely Character Graph (\textbf{CG}), which comprehensively represents various story-related knowledge, including the characters, the attributes related to characters, and the relationship between characters. We then introduce StoryWeaver, an image generator that achieve Customization via Character Graph (\textbf{C-CG}), capable of consistent story visualization with rich text semantics. To further improve the multi-character generation performance, we incorporate knowledge-enhanced spatial guidance (\textbf{KE-SG}) into StoryWeaver to precisely inject character semantics into generation. To validate the effectiveness of our proposed method, extensive experiments are conducted using a new benchmark called TBC-Bench. The experiments confirm that our StoryWeaver excels not only in creating vivid visual story plots but also in accurately conveying character identities across various scenarios with considerable storage efficiency, \emph{e.g.}, achieving an average increase of +9.03\% DINO-I and +13.44\% CLIP-T. Furthermore, ablation experiments are conducted to verify the superiority of the proposed module. Codes and datasets are released at https://github.com/Aria-Zhangjl/StoryWeaver.
Model-Based GNN Enabled Energy-Efficient Beamforming for Ultra-Dense Wireless Networks
Oct 03, 2024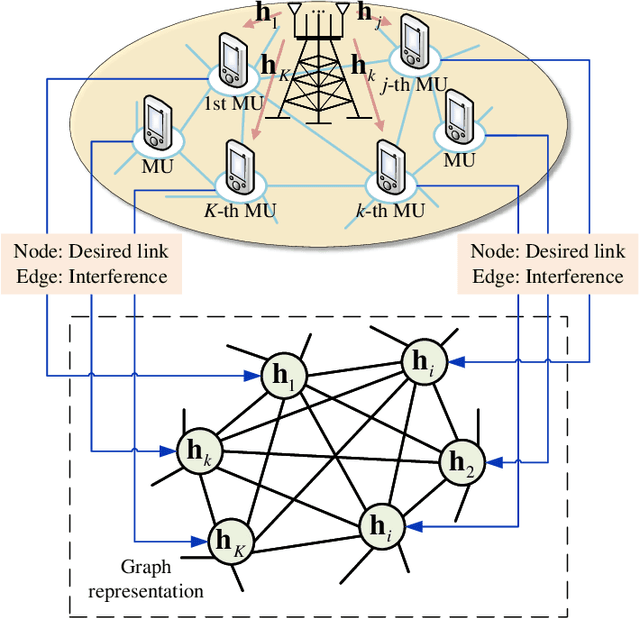
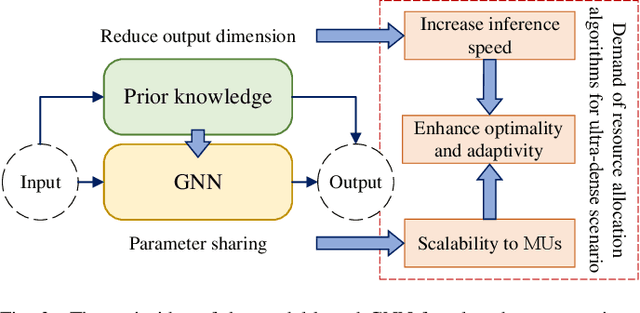
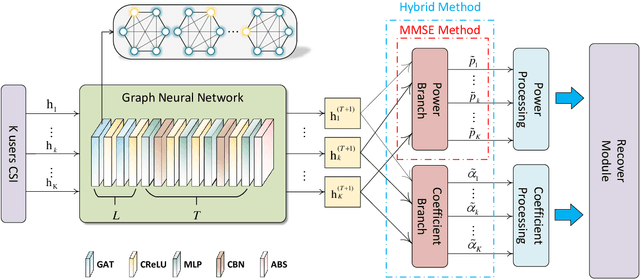
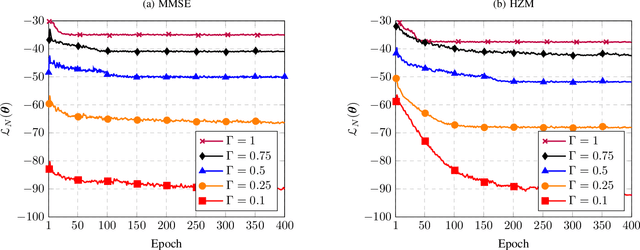
This paper investigates deep learning enabled beamforming design for ultra-dense wireless networks by integrating prior knowledge and graph neural network (GNN), named model-based GNN. A energy efficiency (EE) maximization problem is formulated subject to power budget and quality of service (QoS) requirements, which is reformulated based on the minimum mean square error scheme and the hybrid zero-forcing and maximum ratio transmission schemes. Based on the reformulated problem, the model-based GNN to realize the mapping from channel state information to beamforming vectors. Particular, the multi-head attention mechanism and residual connection are adopted to enhance the feature extracting, and a scheme selection module is designed to improve the adaptability of GNN. The unsupervised learning is adopted, and a various-input training strategy is proposed to enhance the stability of GNN. Numerical results demonstrate the millisecond-level response with limited performance loss, the scalability to different users and the adaptability to various channel conditions and QoS requirements of the model-based GNN in ultra-dense wireless networks.
Character-Adapter: Prompt-Guided Region Control for High-Fidelity Character Customization
Jun 24, 2024



Customized image generation, which seeks to synthesize images with consistent characters, holds significant relevance for applications such as storytelling, portrait generation, and character design. However, previous approaches have encountered challenges in preserving characters with high-fidelity consistency due to inadequate feature extraction and concept confusion of reference characters. Therefore, we propose Character-Adapter, a plug-and-play framework designed to generate images that preserve the details of reference characters, ensuring high-fidelity consistency. Character-Adapter employs prompt-guided segmentation to ensure fine-grained regional features of reference characters and dynamic region-level adapters to mitigate concept confusion. Extensive experiments are conducted to validate the effectiveness of Character-Adapter. Both quantitative and qualitative results demonstrate that Character-Adapter achieves the state-of-the-art performance of consistent character generation, with an improvement of 24.8% compared with other methods
HoLLMwood: Unleashing the Creativity of Large Language Models in Screenwriting via Role Playing
Jun 17, 2024



Generative AI has demonstrated unprecedented creativity in the field of computer vision, yet such phenomena have not been observed in natural language processing. In particular, large language models (LLMs) can hardly produce written works at the level of human experts due to the extremely high complexity of literature writing. In this paper, we present HoLLMwood, an automated framework for unleashing the creativity of LLMs and exploring their potential in screenwriting, which is a highly demanding task. Mimicking the human creative process, we assign LLMs to different roles involved in the real-world scenario. In addition to the common practice of treating LLMs as ${Writer}$, we also apply LLMs as ${Editor}$, who is responsible for providing feedback and revision advice to ${Writer}$. Besides, to enrich the characters and deepen the plots, we introduce a role-playing mechanism and adopt LLMs as ${Actors}$ that can communicate and interact with each other. Evaluations on automatically generated screenplays show that HoLLMwood substantially outperforms strong baselines in terms of coherence, relevance, interestingness and overall quality.