 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Large Language Models via Adaptive Causal Prompting with Sketch-of-Thought
Jan 13, 2026Despite notable advancements in prompting methods for Large Language Models (LLMs), such as Chain-of-Thought (CoT), existing strategies still suffer from excessive token usage and limited generalisability across diverse reasoning tasks. To address these limitations, we propose an Adaptive Causal Prompting with Sketch-of-Thought (ACPS) framework, which leverages structural causal models to infer the causal effect of a query on its answer and adaptively select an appropriate intervention (i.e., standard front-door and conditional front-door adjustments). This design enables generalisable causal reasoning across heterogeneous tasks without task-specific retraining. By replacing verbose CoT with concise Sketch-of-Thought, ACPS enables efficient reasoning that significantly reduces token usage and inference cost. Extensive experiments on multiple reasoning benchmarks and LLMs demonstrate that ACPS consistently outperforms existing prompting baselines in terms of accuracy, robustness, and computational efficiency.
Effective Policy Learning for Multi-Agent Online Coordination Beyond Submodular Objectives
Sep 26, 2025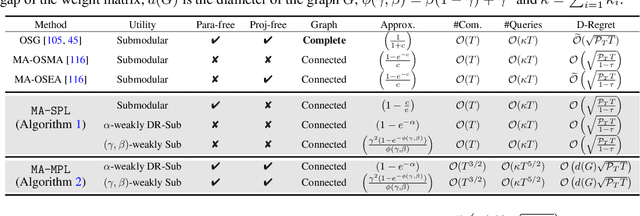

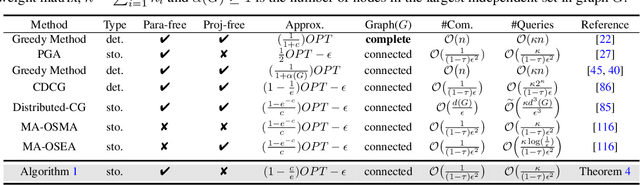
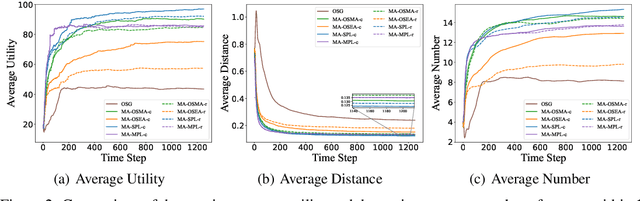
In this paper, we present two effective policy learning algorithms for multi-agent online coordination(MA-OC) problem. The first one, \texttt{MA-SPL}, not only can achieve the optimal $(1-\frac{c}{e})$-approximation guarantee for the MA-OC problem with submodular objectives but also can handle the unexplored $\alpha$-weakly DR-submodular and $(\gamma,\beta)$-weakly submodular scenarios, where $c$ is the curvature of the investigated submodular functions, $\alpha$ denotes the diminishing-return(DR) ratio and the tuple $(\gamma,\beta)$ represents the submodularity ratios. Subsequently, in order to reduce the reliance on the unknown parameters $\alpha,\gamma,\beta$ inherent in the \texttt{MA-SPL} algorithm, we further introduce the second online algorithm named \texttt{MA-MPL}. This \texttt{MA-MPL} algorithm is entirely \emph{parameter-free} and simultaneously can maintain the same approximation ratio as the first \texttt{MA-SPL} algorithm. The core of our \texttt{MA-SPL} and \texttt{MA-MPL} algorithms is a novel continuous-relaxation technique termed as \emph{policy-based continuous extension}. Compared with the well-established \emph{multi-linear extension}, a notable advantage of this new \emph{policy-based continuous extension} is its ability to provide a lossless rounding scheme for any set function, thereby enabling us to tackle the challenging weakly submodular objectives. Finally, extensive simulations are conducted to validate the effectiveness of our proposed algorithms.
MaskPro: Linear-Space Probabilistic Learning for Strict (N:M)-Sparsity on Large Language Models
Jun 15, 2025The rapid scaling of large language models (LLMs) has made inference efficiency a primary bottleneck in the practical deployment. To address this, semi-structured sparsity offers a promising solution by strategically retaining $N$ elements out of every $M$ weights, thereby enabling hardware-friendly acceleration and reduced memory. However, existing (N:M)-compatible approaches typically fall into two categories: rule-based layerwise greedy search, which suffers from considerable errors, and gradient-driven combinatorial learning, which incurs prohibitive training costs. To tackle these challenges, we propose a novel linear-space probabilistic framework named MaskPro, which aims to learn a prior categorical distribution for every $M$ consecutive weights and subsequently leverages this distribution to generate the (N:M)-sparsity throughout an $N$-way sampling without replacement. Furthermore, to mitigate the training instability induced by the high variance of policy gradients in the super large combinatorial space, we propose a novel update method by introducing a moving average tracker of loss residuals instead of vanilla loss. Finally, we conduct comprehensive theoretical analysis and extensive experiments to validate the superior performance of MaskPro, as well as its excellent scalability in memory efficiency and exceptional robustness to data samples. Our code is available at https://github.com/woodenchild95/Maskpro.git.
Improving large language models with concept-aware fine-tuning
Jun 09, 2025Large language models (LLMs) have become the cornerstone of modern AI. However, the existing paradigm of next-token prediction fundamentally limits their ability to form coherent, high-level concepts, making it a critical barrier to human-like understanding and reasoning. Take the phrase "ribonucleic acid" as an example: an LLM will first decompose it into tokens, i.e., artificial text fragments ("rib", "on", ...), then learn each token sequentially, rather than grasping the phrase as a unified, coherent semantic entity. This fragmented representation hinders deeper conceptual understanding and, ultimately, the development of truly intelligent systems. In response, we introduce Concept-Aware Fine-Tuning (CAFT), a novel multi-token training method that redefines how LLMs are fine-tuned. By enabling the learning of sequences that span multiple tokens, this method fosters stronger concept-aware learning. Our experiments demonstrate significant improvements compared to conventional next-token finetuning methods across diverse tasks, including traditional applications like text summarization and domain-specific ones like de novo protein design. Multi-token prediction was previously only possible in the prohibitively expensive pretraining phase; CAFT, to our knowledge, is the first to bring the multi-token setting to the post-training phase, thus effectively democratizing its benefits for the broader community of practitioners and researchers. Finally, the unexpected effectiveness of our proposed method suggests wider implications for the machine learning research community. All code and data are available at https://github.com/michaelchen-lab/caft-llm
Towards Heterogeneous Continual Graph Learning via Meta-knowledge Distillation
May 23, 2025Machine learning on heterogeneous graphs has experienced rapid advancement in recent years, driven by the inherently heterogeneous nature of real-world data. However, existing studies typically assume the graphs to be static, while real-world graphs are continuously expanding. This dynamic nature requires models to adapt to new data while preserving existing knowledge. To this end, this work addresses the challenge of continual learning on heterogeneous graphs by introducing the Meta-learning based Knowledge Distillation framework (MKD), designed to mitigate catastrophic forgetting in evolving heterogeneous graph structures. MKD combines rapid task adaptation through meta-learning on limited samples with knowledge distillation to achieve an optimal balance between incorporating new information and maintaining existing knowledge. To improve the efficiency and effectiveness of sample selection, MKD incorporates a novel sampling strategy that selects a small number of target-type nodes based on node diversity and maintains fixed-size buffers for other types. The strategy retrieves first-order neighbors along metapaths and selects important neighbors based on their structural relevance, enabling the sampled subgraphs to retain key topological and semantic information. In addition, MKD introduces a semantic-level distillation module that aligns the attention distributions over different metapaths between teacher and student models, encouraging semantic consistency beyond the logit level. Comprehensive evaluations across three benchmark datasets validate MKD's effectiveness in handling continual learning scenarios on expanding heterogeneous graphs.
Fairness in Graph Learning Augmented with Machine Learning: A Survey
Apr 30, 2025Augmenting specialised machine learning techniques into traditional graph learning models has achieved notable success across various domains, including federated graph learning, dynamic graph learning, and graph transformers. However, the intricate mechanisms of these specialised techniques introduce significant challenges in maintaining model fairness, potentially resulting in discriminatory outcomes in high-stakes applications such as recommendation systems, disaster response, criminal justice, and loan approval. This paper systematically examines the unique fairness challenges posed by Graph Learning augmented with Machine Learning (GL-ML). It highlights the complex interplay between graph learning mechanisms and machine learning techniques, emphasising how the augmentation of machine learning both enhances and complicates fairness. Additionally, we explore four critical techniques frequently employed to improve fairness in GL-ML methods. By thoroughly investigating the root causes and broader implications of fairness challenges in this rapidly evolving field, this work establishes a robust foundation for future research and innovation in GL-ML fairness.
Crisp: Cognitive Restructuring of Negative Thoughts through Multi-turn Supportive Dialogues
Apr 24, 2025Cognitive Restructuring (CR) is a psychotherapeutic process aimed at identifying and restructuring an individual's negative thoughts, arising from mental health challenges, into more helpful and positive ones via multi-turn dialogues. Clinician shortage and stigma urge the development of human-LLM interactive psychotherapy for CR. Yet, existing efforts implement CR via simple text rewriting, fixed-pattern dialogues, or a one-shot CR workflow, failing to align with the psychotherapeutic process for effective CR. To address this gap, we propose CRDial, a novel framework for CR, which creates multi-turn dialogues with specifically designed identification and restructuring stages of negative thoughts, integrates sentence-level supportive conversation strategies, and adopts a multi-channel loop mechanism to enable iterative CR. With CRDial, we distill Crisp, a large-scale and high-quality bilingual dialogue dataset, from LLM. We then train Crispers, Crisp-based conversational LLMs for CR, at 7B and 14B scales. Extensive human studies show the superiority of Crispers in pointwise, pairwise, and intervention evaluations.
R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization
Mar 17, 2025Recent studies generally enhance MLLMs' reasoning capabilities via supervised fine-tuning on high-quality chain-of-thought reasoning data, which often leads models to merely imitate successful reasoning paths without understanding what the wrong reasoning paths are. In this work, we aim to enhance the MLLMs' reasoning ability beyond passively imitating positive reasoning paths. To this end, we design Step-wise Group Relative Policy Optimization (StepGRPO), a new online reinforcement learning framework that enables MLLMs to self-improve reasoning ability via simple, effective and dense step-wise rewarding. Specifically, StepGRPO introduces two novel rule-based reasoning rewards: Step-wise Reasoning Accuracy Reward (StepRAR) and Step-wise Reasoning Validity Reward (StepRVR). StepRAR rewards the reasoning paths that contain necessary intermediate reasoning steps via a soft key-step matching technique, while StepRAR rewards reasoning paths that follow a well-structured and logically consistent reasoning process through a reasoning completeness and logic evaluation strategy. With the proposed StepGRPO, we introduce R1-VL, a series of MLLMs with outstanding capabilities in step-by-step reasoning. Extensive experiments over 8 benchmarks demonstrate the superiority of our methods.
Benchmarking Reasoning Robustness in Large Language Models
Mar 06, 2025Despite the recent success of large language models (LLMs) in reasoning such as DeepSeek, we for the first time identify a key dilemma in reasoning robustness and generalization: significant performance degradation on novel or incomplete data, suggesting a reliance on memorized patterns rather than systematic reasoning. Our closer examination reveals four key unique limitations underlying this issue:(1) Positional bias--models favor earlier queries in multi-query inputs but answering the wrong one in the latter (e.g., GPT-4o's accuracy drops from 75.8 percent to 72.8 percent); (2) Instruction sensitivity--performance declines by 5.0 to 7.5 percent in the Qwen2.5 Series and by 5.0 percent in DeepSeek-V3 with auxiliary guidance; (3) Numerical fragility--value substitution sharply reduces accuracy (e.g., GPT-4o drops from 97.5 percent to 82.5 percent, GPT-o1-mini drops from 97.5 percent to 92.5 percent); and (4) Memory dependence--models resort to guesswork when missing critical data. These findings further highlight the reliance on heuristic recall over rigorous logical inference, demonstrating challenges in reasoning robustness. To comprehensively investigate these robustness challenges, this paper introduces a novel benchmark, termed as Math-RoB, that exploits hallucinations triggered by missing information to expose reasoning gaps. This is achieved by an instruction-based approach to generate diverse datasets that closely resemble training distributions, facilitating a holistic robustness assessment and advancing the development of more robust reasoning frameworks. Bad character(s) in field Abstract.
JustLogic: A Comprehensive Benchmark for Evaluating Deductive Reasoning in Large Language Models
Jan 24, 2025Logical reasoning is a critical component of Large Language Models (LLMs), and substantial research efforts in recent years have aimed to enhance their deductive reasoning capabilities. However, existing deductive reasoning benchmarks, which are crucial for evaluating and advancing LLMs, are inadequate due to their lack of task complexity, presence of prior knowledge as a confounder, and superficial error analysis. To address these deficiencies, we introduce JustLogic, a synthetically generated deductive reasoning benchmark designed for rigorous evaluation of LLMs. JustLogic is (i) highly complex, capable of generating a diverse range of linguistic patterns, vocabulary, and argument structures; (ii) prior knowledge independent, eliminating the advantage of models possessing prior knowledge and ensuring that only deductive reasoning is used to answer questions; and (iii) capable of in-depth error analysis on the heterogeneous effects of reasoning depth and argument form on model accuracy. Our experimental results on JustLogic reveal that most state-of-the-art (SOTA) LLMs perform significantly worse than the human average, demonstrating substantial room for model improvement. All code and data are available at https://github.com/michaelchen-lab/JustLogic