 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho-DM: Ultrasound Marker Removal via Conditional Latent Diffusion and Region-Aware Fusion
Jun 08, 2026Clinical ultrasound images often contain artificial markers, such as measurement calipers and text, to assist diagnostic interpretation and comparison. However, these markers can introduce shortcut bias in downstream automated analysis, encouraging deep learning models to rely on marker-related cues rather than clinically meaningful anatomy. Existing marker removal methods are either mask-dependent and vulnerable to error propagation, or mask-free deterministic restorers that may over-smooth ultrasound texture and perturb unaffected background regions. To address these challenges, we present Echo-DM, a framework for ultrasound marker removal via conditional latent diffusion and region-aware fusion. Echo-DM follows a common encoder-diffusion-decoder pipeline, where a DiT-based conditional latent diffusion network performs global restoration and a region-aware fusion module enforces preservation-aware image-space refinement under end-to-end mask-free inference. Building on this fixed core design, we further instantiate Echo-DM-V and Echo-DM-R with VAE-based and RAE-based latent modules, respectively, which demonstrates that the Echo-DM architecture is compatible with diverse latent-module instantiations. Extensive experiments on Echo-PAIR, a large-scale paired clinical ultrasound dataset, demonstrate superior marker removal and strong anatomical fidelity compared with representative two-stage baselines, while providing favorable quality--efficiency trade-offs across deployment settings. Data, code and models will be released at https://github.com/MiliLab/Echo-DM.
Image Classification via Random Dilated Convolution with Multi-Branch Feature Extraction and Context Excitation
Apr 28, 2026Image classification remains a fundamental yet challenging task in computer vision, particularly when fine-grained feature extraction and background noise suppression are required simultaneously. Conventional convolutional neural networks, despite their remarkable success in hierarchical feature learning, often struggle with capturing multi-scale contextual information and are susceptible to overfitting when confronted with noisy or irrelevant image regions. In this paper, we propose RDCNet (Image Classification Network with Random Dilated Convolution), a novel architecture built upon ResNet-34 that integrates three synergistic innovations to address these limitations: (1) a Multi-Branch Random Dilated Convolution (MRDC) module that employs parallel branches with varying dilation rates combined with a stochastic masking mechanism to capture fine-grained features across multiple scales while enhancing robustness against noise and overfitting; (2) a Fine-Grained Feature Enhancement (FGFE) module embedded within MRDC that bridges global contextual information with local feature representations through adaptive pooling and bilinear interpolation, thereby amplifying sensitivity to subtle visual patterns; and (3) a Context Excitation (CE) module that leverages softmax-based spatial attention and channel recalibration to dynamically emphasize task-relevant features while suppressing background interference. Extensive experiments conducted on five benchmark datasets -- CIFAR-10, CIFAR-100, SVHN, Imagenette, and Imagewoof -- demonstrate that RDCNet consistently achieves state-of-the-art classification accuracy, outperforming the second-best competing methods by margins of 0.02\%, 1.12\%, 0.18\%, 4.73\%, and 3.56\%, respectively, thereby validating the effectiveness and generalizability of the proposed approach across diverse visual recognition scenarios.
SAMe: A Semantic Anatomy Mapping Engine for Robotic Ultrasound
Apr 28, 2026Robotic ultrasound has advanced local image-driven control, contact regulation, and view optimization, yet current systems lack the anatomical understanding needed to determine what to scan, where to begin, and how to adapt to individual patient anatomy. These gaps make systems still reliant on expert intervention to initiate scanning. Here we present SAMe, a semantic anatomy mapping engine that provides robotic ultrasound with an explicit anatomical prior layer. SAMe addresses scan initiation as a target-to-anatomy-to-action process: it grounds under-specified clinical complaints into structured target organs, instantiates a patient-specific anatomical representation for the grounded targets from a single external body image, and translates this representation into control-facing 6-DoF probe initialization states without any additional registration using preoperative CT or MRI. The anatomical representation maintained by SAMe is explicit, lightweight (single-organ inference in 0.08s), and compatible with downstream control by design. Across semantic grounding, anatomical instantiation, and real-robot evaluation, SAMe shows strong performance across the full initialization pipeline. In real-robot experiments, SAMe achieved overall organ-hit rates of 97.3% for liver initialization and 81.7% for kidney initialization across the evaluated target sets. Even when restricted to the centroid target, SAMe outperformed the surface-heuristic baseline for both liver and kidney initialization. These results establish an explicit anatomical prior layer that addresses scan initialization and is designed to support broader downstream autonomous scanning pipelines, providing the anatomical foundation for complaint-driven, anatomically informed robotic ultrasonography.
GNN-based Path-aware multi-view Circuit Learning for Technology Mapping
Jan 14, 2026Traditional technology mapping suffers from systemic inaccuracies in delay estimation due to its reliance on abstract, technology-agnostic delay models that fail to capture the nuanced timing behavior behavior of real post-mapping circuits. To address this fundamental limitation, we introduce GPA(graph neural network (GNN)-based Path-Aware multi-view circuit learning), a novel GNN framework that learns precise, data-driven delay predictions by synergistically fusing three complementary views of circuit structure: And-Inverter Graphs (AIGs)-based functional encoding, post-mapping technology emphasizes critical timing paths. Trained exclusively on real cell delays extracted from critical paths of industrial-grade post-mapping netlists, GPA learns to classify cut delays with unprecedented accuracy, directly informing smarter mapping decisions. Evaluated on the 19 EPFL combinational benchmarks, GPA achieves 19.9%, 2.1% and 4.1% average delay reduction over the conventional heuristics methods (techmap, MCH) and the prior state-of-the-art ML-based approach SLAP, respectively-without compromising area efficiency.
SARMAE: Masked Autoencoder for SAR Representation Learning
Dec 18, 2025Synthetic Aperture Radar (SAR) imagery plays a critical role in all-weather, day-and-night remote sensing applications. However, existing SAR-oriented deep learning is constrained by data scarcity, while the physically grounded speckle noise in SAR imagery further hampers fine-grained semantic representation learning. To address these challenges, we propose SARMAE, a Noise-Aware Masked Autoencoder for self-supervised SAR representation learning. Specifically, we construct SAR-1M, the first million-scale SAR dataset, with additional paired optical images, to enable large-scale pre-training. Building upon this, we design Speckle-Aware Representation Enhancement (SARE), which injects SAR-specific speckle noise into masked autoencoders to facilitate noise-aware and robust representation learning. Furthermore, we introduce Semantic Anchor Representation Constraint (SARC), which leverages paired optical priors to align SAR features and ensure semantic consistency. Extensive experiments across multiple SAR datasets demonstrate that SARMAE achieves state-of-the-art performance on classification, detection, and segmentation tasks. Code and models will be available at https://github.com/MiliLab/SARMAE.
Uncertainty-Aware Domain Adaptation for Vitiligo Segmentation in Clinical Photographs
Dec 12, 2025Accurately quantifying vitiligo extent in routine clinical photographs is crucial for longitudinal monitoring of treatment response. We propose a trustworthy, frequency-aware segmentation framework built on three synergistic pillars: (1) a data-efficient training strategy combining domain-adaptive pre-training on the ISIC 2019 dataset with an ROI-constrained dual-task loss to suppress background noise; (2) an architectural refinement via a ConvNeXt V2-based encoder enhanced with a novel High-Frequency Spectral Gating (HFSG) module and stem-skip connections to capture subtle textures; and (3) a clinical trust mechanism employing K-fold ensemble and Test-Time Augmentation (TTA) to generate pixel-wise uncertainty maps. Extensive validation on an expert-annotated clinical cohort demonstrates superior performance, achieving a Dice score of 85.05% and significantly reducing boundary error (95% Hausdorff Distance improved from 44.79 px to 29.95 px), consistently outperforming strong CNN (ResNet-50 and UNet++) and Transformer (MiT-B5) baselines. Notably, our framework demonstrates high reliability with zero catastrophic failures and provides interpretable entropy maps to identify ambiguous regions for clinician review. Our approach suggests that the proposed framework establishes a robust and reliable standard for automated vitiligo assessment.
RISE-T2V: Rephrasing and Injecting Semantics with LLM for Expansive Text-to-Video Generation
Nov 06, 2025Most text-to-video(T2V) diffusion models depend on pre-trained text encoders for semantic alignment, yet they often fail to maintain video quality when provided with concise prompts rather than well-designed ones. The primary issue lies in their limited textual semantics understanding. Moreover, these text encoders cannot rephrase prompts online to better align with user intentions, which limits both the scalability and usability of the models, To address these challenges, we introduce RISE-T2V, which uniquely integrates the processes of prompt rephrasing and semantic feature extraction into a single and seamless step instead of two separate steps. RISE-T2V is universal and can be applied to various pre-trained LLMs and video diffusion models(VDMs), significantly enhancing their capabilities for T2V tasks. We propose an innovative module called the Rephrasing Adapter, enabling diffusion models to utilize text hidden states during the next token prediction of the LLM as a condition for video generation. By employing a Rephrasing Adapter, the video generation model can implicitly rephrase basic prompts into more comprehensive representations that better match the user's intent. Furthermore, we leverage the powerful capabilities of LLMs to enable video generation models to accomplish a broader range of T2V tasks. Extensive experiments demonstrate that RISE-T2V is a versatile framework applicable to different video diffusion model architectures, significantly enhancing the ability of T2V models to generate high-quality videos that align with user intent. Visual results are available on the webpage at https://rise-t2v.github.io.
Identity-Preserving Image-to-Video Generation via Reward-Guided Optimization
Oct 16, 2025Recent advances in image-to-video (I2V) generation have achieved remarkable progress in synthesizing high-quality, temporally coherent videos from static images. Among all the applications of I2V, human-centric video generation includes a large portion. However, existing I2V models encounter difficulties in maintaining identity consistency between the input human image and the generated video, especially when the person in the video exhibits significant expression changes and movements. This issue becomes critical when the human face occupies merely a small fraction of the image. Since humans are highly sensitive to identity variations, this poses a critical yet under-explored challenge in I2V generation. In this paper, we propose Identity-Preserving Reward-guided Optimization (IPRO), a novel video diffusion framework based on reinforcement learning to enhance identity preservation. Instead of introducing auxiliary modules or altering model architectures, our approach introduces a direct and effective tuning algorithm that optimizes diffusion models using a face identity scorer. To improve performance and accelerate convergence, our method backpropagates the reward signal through the last steps of the sampling chain, enabling richer gradient feedback. We also propose a novel facial scoring mechanism that treats faces in ground-truth videos as facial feature pools, providing multi-angle facial information to enhance generalization. A KL-divergence regularization is further incorporated to stabilize training and prevent overfitting to the reward signal. Extensive experiments on Wan 2.2 I2V model and our in-house I2V model demonstrate the effectiveness of our method. Our project and code are available at \href{https://ipro-alimama.github.io/}{https://ipro-alimama.github.io/}.
REX-RAG: Reasoning Exploration with Policy Correction in Retrieval-Augmented Generation
Aug 12, 2025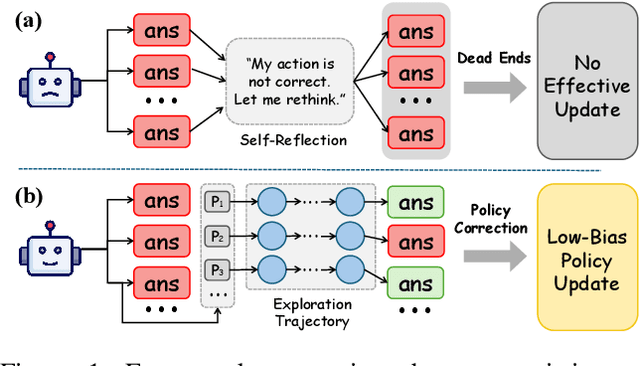
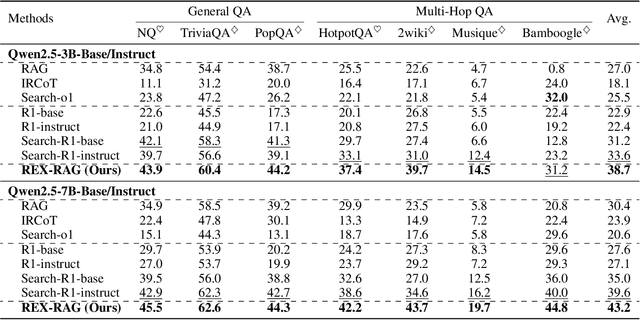
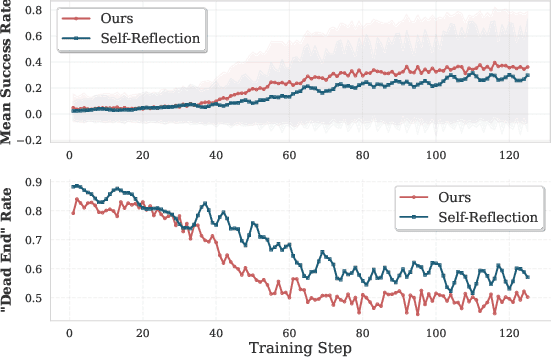
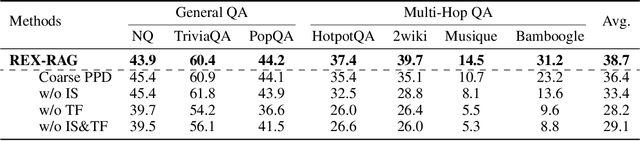
Reinforcement learning (RL) is emerging as a powerful paradigm for enabling large language models (LLMs) to perform complex reasoning tasks. Recent advances indicate that integrating RL with retrieval-augmented generation (RAG) allows LLMs to dynamically incorporate external knowledge, leading to more informed and robust decision making. However, we identify a critical challenge during policy-driven trajectory sampling: LLMs are frequently trapped in unproductive reasoning paths, which we refer to as "dead ends", committing to overconfident yet incorrect conclusions. This severely hampers exploration and undermines effective policy optimization. To address this challenge, we propose REX-RAG (Reasoning Exploration with Policy Correction in Retrieval-Augmented Generation), a novel framework that explores alternative reasoning paths while maintaining rigorous policy learning through principled distributional corrections. Our approach introduces two key innovations: (1) Mixed Sampling Strategy, which combines a novel probe sampling method with exploratory prompts to escape dead ends; and (2) Policy Correction Mechanism, which employs importance sampling to correct distribution shifts induced by mixed sampling, thereby mitigating gradient estimation bias. We evaluate it on seven question-answering benchmarks, and the experimental results show that REX-RAG achieves average performance gains of 5.1% on Qwen2.5-3B and 3.6% on Qwen2.5-7B over strong baselines, demonstrating competitive results across multiple datasets. The code is publicly available at https://github.com/MiliLab/REX-RAG.
AnesBench: Multi-Dimensional Evaluation of LLM Reasoning in Anesthesiology
Apr 03, 2025The application of large language models (LLMs) in the medical field has gained significant attention, yet their reasoning capabilities in more specialized domains like anesthesiology remain underexplored. In this paper, we systematically evaluate the reasoning capabilities of LLMs in anesthesiology and analyze key factors influencing their performance. To this end, we introduce AnesBench, a cross-lingual benchmark designed to assess anesthesiology-related reasoning across three levels: factual retrieval (System 1), hybrid reasoning (System 1.x), and complex decision-making (System 2). Through extensive experiments, we first explore how model characteristics, including model scale, Chain of Thought (CoT) length, and language transferability, affect reasoning performance. Then, we further evaluate the effectiveness of different training strategies, leveraging our curated anesthesiology-related dataset, including continuous pre-training (CPT) and supervised fine-tuning (SFT). Additionally, we also investigate how the test-time reasoning techniques, such as Best-of-N sampling and beam search, influence reasoning performance, and assess the impact of reasoning-enhanced model distillation, specifically DeepSeek-R1. We will publicly release AnesBench, along with our CPT and SFT training datasets and evaluation code at https://github.com/MiliLab/AnesBench.