 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeΨ-Arena: Interactive Assessment and Optimization of LLM-based Psychological Counselors with Tripartite Feedback
May 06, 2025Large language models (LLMs) have shown promise in providing scalable mental health support, while evaluating their counseling capability remains crucial to ensure both efficacy and safety. Existing evaluations are limited by the static assessment that focuses on knowledge tests, the single perspective that centers on user experience, and the open-loop framework that lacks actionable feedback. To address these issues, we propose {\Psi}-Arena, an interactive framework for comprehensive assessment and optimization of LLM-based counselors, featuring three key characteristics: (1) Realistic arena interactions that simulate real-world counseling through multi-stage dialogues with psychologically profiled NPC clients, (2) Tripartite evaluation that integrates assessments from the client, counselor, and supervisor perspectives, and (3) Closed-loop optimization that iteratively improves LLM counselors using diagnostic feedback. Experiments across eight state-of-the-art LLMs show significant performance variations in different real-world scenarios and evaluation perspectives. Moreover, reflection-based optimization results in up to a 141% improvement in counseling performance. We hope PsychoArena provides a foundational resource for advancing reliable and human-aligned LLM applications in mental healthcare.
MAGI: Multi-Agent Guided Interview for Psychiatric Assessment
Apr 25, 2025Automating structured clinical interviews could revolutionize mental healthcare accessibility, yet existing large language models (LLMs) approaches fail to align with psychiatric diagnostic protocols. We present MAGI, the first framework that transforms the gold-standard Mini International Neuropsychiatric Interview (MINI) into automatic computational workflows through coordinated multi-agent collaboration. MAGI dynamically navigates clinical logic via four specialized agents: 1) an interview tree guided navigation agent adhering to the MINI's branching structure, 2) an adaptive question agent blending diagnostic probing, explaining, and empathy, 3) a judgment agent validating whether the response from participants meet the node, and 4) a diagnosis Agent generating Psychometric Chain-of- Thought (PsyCoT) traces that explicitly map symptoms to clinical criteria. Experimental results on 1,002 real-world participants covering depression, generalized anxiety, social anxiety and suicide shows that MAGI advances LLM- assisted mental health assessment by combining clinical rigor, conversational adaptability, and explainable reasoning.
Crisp: Cognitive Restructuring of Negative Thoughts through Multi-turn Supportive Dialogues
Apr 24, 2025Cognitive Restructuring (CR) is a psychotherapeutic process aimed at identifying and restructuring an individual's negative thoughts, arising from mental health challenges, into more helpful and positive ones via multi-turn dialogues. Clinician shortage and stigma urge the development of human-LLM interactive psychotherapy for CR. Yet, existing efforts implement CR via simple text rewriting, fixed-pattern dialogues, or a one-shot CR workflow, failing to align with the psychotherapeutic process for effective CR. To address this gap, we propose CRDial, a novel framework for CR, which creates multi-turn dialogues with specifically designed identification and restructuring stages of negative thoughts, integrates sentence-level supportive conversation strategies, and adopts a multi-channel loop mechanism to enable iterative CR. With CRDial, we distill Crisp, a large-scale and high-quality bilingual dialogue dataset, from LLM. We then train Crispers, Crisp-based conversational LLMs for CR, at 7B and 14B scales. Extensive human studies show the superiority of Crispers in pointwise, pairwise, and intervention evaluations.
CharacterBench: Benchmarking Character Customization of Large Language Models
Dec 16, 2024



Character-based dialogue (aka role-playing) enables users to freely customize characters for interaction, which often relies on LLMs, raising the need to evaluate LLMs' character customization capability. However, existing benchmarks fail to ensure a robust evaluation as they often only involve a single character category or evaluate limited dimensions. Moreover, the sparsity of character features in responses makes feature-focused generative evaluation both ineffective and inefficient. To address these issues, we propose CharacterBench, the largest bilingual generative benchmark, with 22,859 human-annotated samples covering 3,956 characters from 25 detailed character categories. We define 11 dimensions of 6 aspects, classified as sparse and dense dimensions based on whether character features evaluated by specific dimensions manifest in each response. We enable effective and efficient evaluation by crafting tailored queries for each dimension to induce characters' responses related to specific dimensions. Further, we develop CharacterJudge model for cost-effective and stable evaluations. Experiments show its superiority over SOTA automatic judges (e.g., GPT-4) and our benchmark's potential to optimize LLMs' character customization. Our repository is at https://github.com/thu-coai/CharacterBench.
CharacterGLM: Customizing Chinese Conversational AI Characters with Large Language Models
Nov 28, 2023



In this paper, we present CharacterGLM, a series of models built upon ChatGLM, with model sizes ranging from 6B to 66B parameters. Our CharacterGLM is designed for generating Character-based Dialogues (CharacterDial), which aims to equip a conversational AI system with character customization for satisfying people's inherent social desires and emotional needs. On top of CharacterGLM, we can customize various AI characters or social agents by configuring their attributes (identities, interests, viewpoints, experiences, achievements, social relationships, etc.) and behaviors (linguistic features, emotional expressions, interaction patterns, etc.). Our model outperforms most mainstream close-source large langauge models, including the GPT series, especially in terms of consistency, human-likeness, and engagement according to manual evaluations. We will release our 6B version of CharacterGLM and a subset of training data to facilitate further research development in the direction of character-based dialogue generation.
CDConv: A Benchmark for Contradiction Detection in Chinese Conversations
Oct 16, 2022
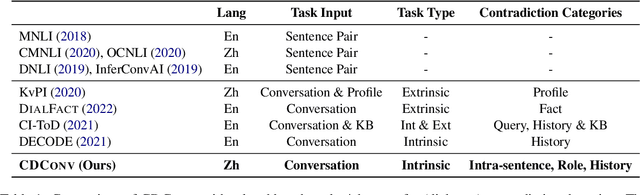

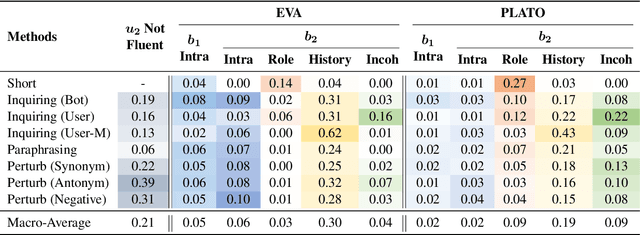
Dialogue contradiction is a critical issue in open-domain dialogue systems. The contextualization nature of conversations makes dialogue contradiction detection rather challenging. In this work, we propose a benchmark for Contradiction Detection in Chinese Conversations, namely CDConv. It contains 12K multi-turn conversations annotated with three typical contradiction categories: Intra-sentence Contradiction, Role Confusion, and History Contradiction. To efficiently construct the CDConv conversations, we devise a series of methods for automatic conversation generation, which simulate common user behaviors that trigger chatbots to make contradictions. We conduct careful manual quality screening of the constructed conversations and show that state-of-the-art Chinese chatbots can be easily goaded into making contradictions. Experiments on CDConv show that properly modeling contextual information is critical for dialogue contradiction detection, but there are still unresolved challenges that require future research.