 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaLoRA: Hardware-aware Low-Rank Adaptation for Large Language Models Based on Hybrid Compute-in-Memory Architecture
Feb 27, 2025
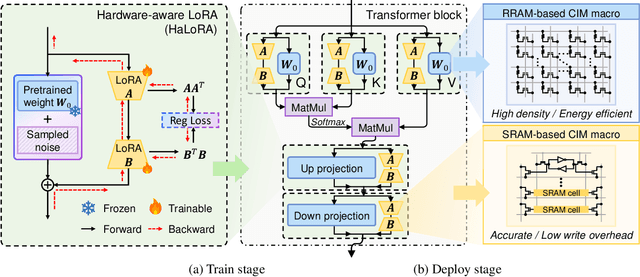
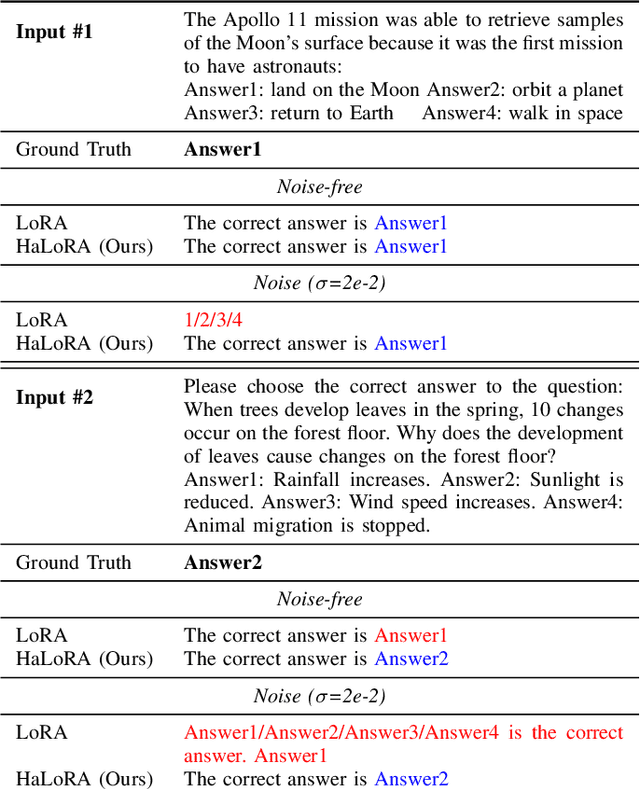
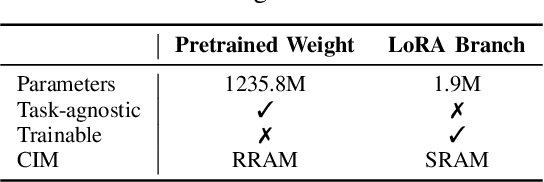
Low-rank adaptation (LoRA) is a predominant parameter-efficient finetuning method to adapt large language models (LLMs) for downstream tasks. In this paper, we first propose to deploy the LoRA-finetuned LLMs on the hybrid compute-in-memory (CIM) architecture (i.e., pretrained weights onto RRAM and LoRA onto SRAM). To address performance degradation from RRAM's inherent noise, we design a novel Hardware-aware Low-rank Adaption (HaLoRA) method, aiming to train a LoRA branch that is both robust and accurate by aligning the training objectives under both ideal and noisy conditions. Experiments finetuning LLaMA 3.2 1B and 3B demonstrate HaLoRA's effectiveness across multiple reasoning tasks, achieving up to 22.7 improvement in average score while maintaining robustness at various noise levels.
Stochastic Multivariate Universal-Radix Finite-State Machine: a Theoretically and Practically Elegant Nonlinear Function Approximator
May 03, 2024



Nonlinearities are crucial for capturing complex input-output relationships especially in deep neural networks. However, nonlinear functions often incur various hardware and compute overheads. Meanwhile, stochastic computing (SC) has emerged as a promising approach to tackle this challenge by trading output precision for hardware simplicity. To this end, this paper proposes a first-of-its-kind stochastic multivariate universal-radix finite-state machine (SMURF) that harnesses SC for hardware-simplistic multivariate nonlinear function generation at high accuracy. We present the finite-state machine (FSM) architecture for SMURF, as well as analytical derivations of sampling gate coefficients for accurately approximating generic nonlinear functions. Experiments demonstrate the superiority of SMURF, requiring only 16.07% area and 14.45% power consumption of Taylor-series approximation, and merely 2.22% area of look-up table (LUT) schemes.