 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictor-Corrector Enhanced Transformers with Exponential Moving Average Coefficient Learning
Nov 05, 2024Residual networks, as discrete approximations of Ordinary Differential Equations (ODEs), have inspired significant advancements in neural network design, including multistep methods, high-order methods, and multi-particle dynamical systems. The precision of the solution to ODEs significantly affects parameter optimization, thereby impacting model performance. In this work, we present a series of advanced explorations of Transformer architecture design to minimize the error compared to the true ``solution.'' First, we introduce a predictor-corrector learning framework to minimize truncation errors, which consists of a high-order predictor and a multistep corrector. Second, we propose an exponential moving average-based coefficient learning method to strengthen our higher-order predictor. Extensive experiments on large-scale machine translation, abstractive summarization, language modeling, and natural language understanding benchmarks demonstrate the superiority of our approach. On the WMT'14 English-German and English-French tasks, our model achieved BLEU scores of 30.95 and 44.27, respectively. Furthermore, on the OPUS multilingual machine translation task, our model surpasses a robust 3.8B DeepNet by an average of 2.9 SacreBLEU, using only 1/3 parameters. Notably, it also beats LLama models by 5.7 accuracy points on the LM Harness Evaluation.
Rethinking Semantic Parsing for Large Language Models: Enhancing LLM Performance with Semantic Hints
Sep 22, 2024Semantic Parsing aims to capture the meaning of a sentence and convert it into a logical, structured form. Previous studies show that semantic parsing enhances the performance of smaller models (e.g., BERT) on downstream tasks. However, it remains unclear whether the improvements extend similarly to LLMs. In this paper, our empirical findings reveal that, unlike smaller models, directly adding semantic parsing results into LLMs reduces their performance. To overcome this, we propose SENSE, a novel prompting approach that embeds semantic hints within the prompt. Experiments show that SENSE consistently improves LLMs' performance across various tasks, highlighting the potential of integrating semantic information to improve LLM capabilities.
Graph Neural Network Enhanced Retrieval for Question Answering of LLMs
Jun 03, 2024Retrieval augmented generation has revolutionized large language model (LLM) outputs by providing factual supports. Nevertheless, it struggles to capture all the necessary knowledge for complex reasoning questions. Existing retrieval methods typically divide reference documents into passages, treating them in isolation. These passages, however, are often interrelated, such as passages that are contiguous or share the same keywords. Therefore, recognizing the relatedness is crucial for enhancing the retrieval process. In this paper, we propose a novel retrieval method, called GNN-Ret, which leverages graph neural networks (GNNs) to enhance retrieval by considering the relatedness between passages. Specifically, we first construct a graph of passages by connecting passages that are structure-related and keyword-related. A graph neural network (GNN) is then leveraged to exploit the relationships between passages and improve the retrieval of supporting passages. Furthermore, we extend our method to handle multi-hop reasoning questions using a recurrent graph neural network (RGNN), named RGNN-Ret. At each step, RGNN-Ret integrates the graphs of passages from previous steps, thereby enhancing the retrieval of supporting passages. Extensive experiments on benchmark datasets demonstrate that GNN-Ret achieves higher accuracy for question answering with a single query of LLMs than strong baselines that require multiple queries, and RGNN-Ret further improves accuracy and achieves state-of-the-art performance, with up to 10.4% accuracy improvement on the 2WikiMQA dataset.
LaDiC: Are Diffusion Models Really Inferior to Autoregressive Counterparts for Image-to-Text Generation?
Apr 16, 2024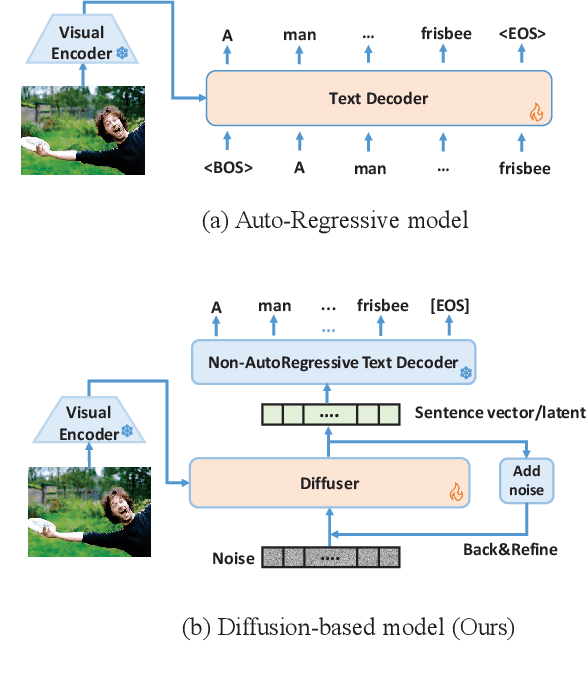
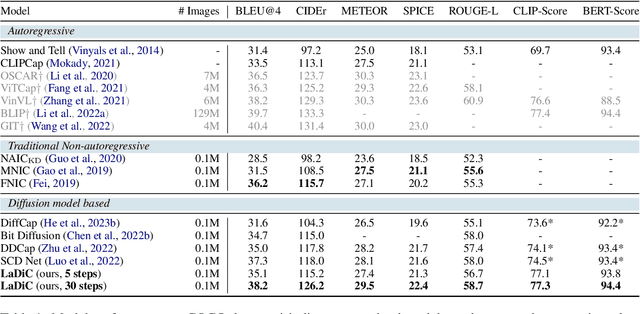
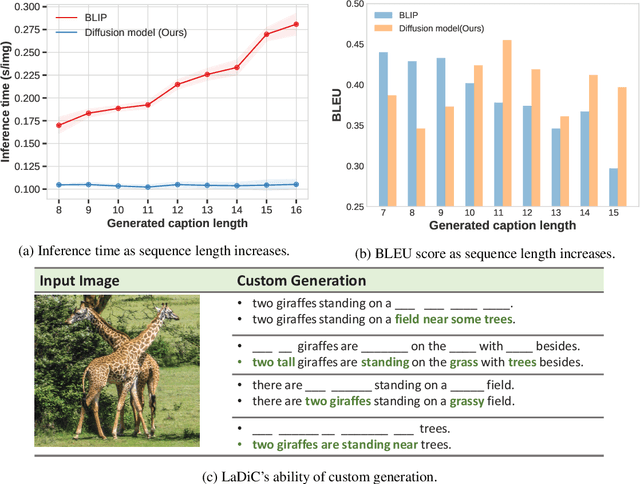
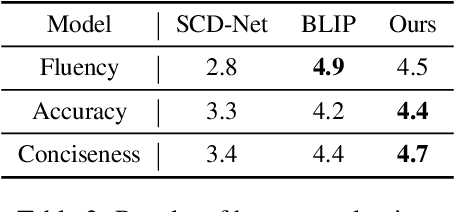
Diffusion models have exhibited remarkable capabilities in text-to-image generation. However, their performance in image-to-text generation, specifically image captioning, has lagged behind Auto-Regressive (AR) models, casting doubt on their applicability for such tasks. In this work, we revisit diffusion models, highlighting their capacity for holistic context modeling and parallel decoding. With these benefits, diffusion models can alleviate the inherent limitations of AR methods, including their slow inference speed, error propagation, and unidirectional constraints. Furthermore, we identify the prior underperformance of diffusion models stemming from the absence of an effective latent space for image-text alignment, and the discrepancy between continuous diffusion processes and discrete textual data. In response, we introduce a novel architecture, LaDiC, which utilizes a split BERT to create a dedicated latent space for captions and integrates a regularization module to manage varying text lengths. Our framework also includes a diffuser for semantic image-to-text conversion and a Back&Refine technique to enhance token interactivity during inference. LaDiC achieves state-of-the-art performance for diffusion-based methods on the MS COCO dataset with 38.2 BLEU@4 and 126.2 CIDEr, demonstrating exceptional performance without pre-training or ancillary modules. This indicates strong competitiveness with AR models, revealing the previously untapped potential of diffusion models in image-to-text generation.
Mitigating Reversal Curse via Semantic-aware Permutation Training
Mar 07, 2024

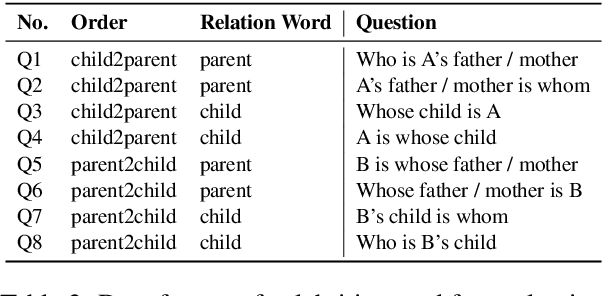

While large language models (LLMs) have achieved impressive performance across diverse tasks, recent studies showcase that causal LLMs suffer from the "reversal curse". It is a typical example that the model knows "A's father is B", but is unable to reason "B's child is A". This limitation poses a challenge to the advancement of artificial general intelligence (AGI), as it suggests a gap in the models' ability to comprehend and apply bidirectional reasoning. In this paper, we first conduct substantial evaluation and identify that the root cause of the reversal curse lies in the different word order between the training and inference stage, namely, the poor ability of causal language models to predict antecedent words within the training data. Accordingly, permutation on the training data is considered as a potential solution, since this can make the model predict antecedent words or tokens. However, previous permutation methods may disrupt complete phrases or entities, thereby posing challenges for the model to comprehend and learn from training data. To address this issue, we propose Semantic-aware Permutation Training (SPT), which addresses this issue by segmenting the training sentences into semantic units (i.e., entities or phrases) with an assistant language model and permuting these units before feeding into the model. Extensive experiments demonstrate that SPT effectively mitigates the reversal curse since the performance on reversed questions approximates that on the forward ones, and significantly advances the performance of existing works.
Hint-enhanced In-Context Learning wakes Large Language Models up for knowledge-intensive tasks
Nov 03, 2023In-context learning (ICL) ability has emerged with the increasing scale of large language models (LLMs), enabling them to learn input-label mappings from demonstrations and perform well on downstream tasks. However, under the standard ICL setting, LLMs may sometimes neglect query-related information in demonstrations, leading to incorrect predictions. To address this limitation, we propose a new paradigm called Hint-enhanced In-Context Learning (HICL) to explore the power of ICL in open-domain question answering, an important form in knowledge-intensive tasks. HICL leverages LLMs' reasoning ability to extract query-related knowledge from demonstrations, then concatenates the knowledge to prompt LLMs in a more explicit way. Furthermore, we track the source of this knowledge to identify specific examples, and introduce a Hint-related Example Retriever (HER) to select informative examples for enhanced demonstrations. We evaluate HICL with HER on 3 open-domain QA benchmarks, and observe average performance gains of 2.89 EM score and 2.52 F1 score on gpt-3.5-turbo, 7.62 EM score and 7.27 F1 score on LLaMA-2-Chat-7B compared with standard setting.
Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers
Sep 15, 2023Large Language Models (LLMs) excel in various tasks, but they rely on carefully crafted prompts that often demand substantial human effort. To automate this process, in this paper, we propose a novel framework for discrete prompt optimization, called EvoPrompt, which borrows the idea of evolutionary algorithms (EAs) as they exhibit good performance and fast convergence. To enable EAs to work on discrete prompts, which are natural language expressions that need to be coherent and human-readable, we connect LLMs with EAs. This approach allows us to simultaneously leverage the powerful language processing capabilities of LLMs and the efficient optimization performance of EAs. Specifically, abstaining from any gradients or parameters, EvoPrompt starts from a population of prompts and iteratively generates new prompts with LLMs based on the evolutionary operators, improving the population based on the development set. We optimize prompts for both closed- and open-source LLMs including GPT-3.5 and Alpaca, on 9 datasets spanning language understanding and generation tasks. EvoPrompt significantly outperforms human-engineered prompts and existing methods for automatic prompt generation by up to 25% and 14% respectively. Furthermore, EvoPrompt demonstrates that connecting LLMs with EAs creates synergies, which could inspire further research on the combination of LLMs and conventional algorithms.
MvP: Multi-view Prompting Improves Aspect Sentiment Tuple Prediction
May 22, 2023



Generative methods greatly promote aspect-based sentiment analysis via generating a sequence of sentiment elements in a specified format. However, existing studies usually predict sentiment elements in a fixed order, which ignores the effect of the interdependence of the elements in a sentiment tuple and the diversity of language expression on the results. In this work, we propose Multi-view Prompting (MvP) that aggregates sentiment elements generated in different orders, leveraging the intuition of human-like problem-solving processes from different views. Specifically, MvP introduces element order prompts to guide the language model to generate multiple sentiment tuples, each with a different element order, and then selects the most reasonable tuples by voting. MvP can naturally model multi-view and multi-task as permutations and combinations of elements, respectively, outperforming previous task-specific designed methods on multiple ABSA tasks with a single model. Extensive experiments show that MvP significantly advances the state-of-the-art performance on 10 datasets of 4 benchmark tasks, and performs quite effectively in low-resource settings. Detailed evaluation verified the effectiveness, flexibility, and cross-task transferability of MvP.