 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Autonomous UAV Visual Object Search in City Space: Benchmark and Agentic Methodology
May 14, 2025Aerial Visual Object Search (AVOS) tasks in urban environments require Unmanned Aerial Vehicles (UAVs) to autonomously search for and identify target objects using visual and textual cues without external guidance. Existing approaches struggle in complex urban environments due to redundant semantic processing, similar object distinction, and the exploration-exploitation dilemma. To bridge this gap and support the AVOS task, we introduce CityAVOS, the first benchmark dataset for autonomous search of common urban objects. This dataset comprises 2,420 tasks across six object categories with varying difficulty levels, enabling comprehensive evaluation of UAV agents' search capabilities. To solve the AVOS tasks, we also propose PRPSearcher (Perception-Reasoning-Planning Searcher), a novel agentic method powered by multi-modal large language models (MLLMs) that mimics human three-tier cognition. Specifically, PRPSearcher constructs three specialized maps: an object-centric dynamic semantic map enhancing spatial perception, a 3D cognitive map based on semantic attraction values for target reasoning, and a 3D uncertainty map for balanced exploration-exploitation search. Also, our approach incorporates a denoising mechanism to mitigate interference from similar objects and utilizes an Inspiration Promote Thought (IPT) prompting mechanism for adaptive action planning. Experimental results on CityAVOS demonstrate that PRPSearcher surpasses existing baselines in both success rate and search efficiency (on average: +37.69% SR, +28.96% SPL, -30.69% MSS, and -46.40% NE). While promising, the performance gap compared to humans highlights the need for better semantic reasoning and spatial exploration capabilities in AVOS tasks. This work establishes a foundation for future advances in embodied target search. Dataset and source code are available at https://anonymous.4open.science/r/CityAVOS-3DF8.
DLW-CI: A Dynamic Likelihood-Weighted Cooperative Infotaxis Approach for Multi-Source Search in Urban Environments Using Consumer Drone Networks
Apr 19, 2025Consumer-grade drones equipped with low-cost sensors have emerged as a cornerstone of Autonomous Intelligent Systems (AISs) for environmental monitoring and hazardous substance detection in urban environments. However, existing research primarily addresses single-source search problems, overlooking the complexities of real-world urban scenarios where both the location and quantity of hazardous sources remain unknown. To address this issue, we propose the Dynamic Likelihood-Weighted Cooperative Infotaxis (DLW-CI) approach for consumer drone networks. Our approach enhances multi-drone collaboration in AISs by combining infotaxis (a cognitive search strategy) with optimized source term estimation and an innovative cooperative mechanism. Specifically, we introduce a novel source term estimation method that utilizes multiple parallel particle filters, with each filter dedicated to estimating the parameters of a potentially unknown source within the search scene. Furthermore, we develop a cooperative mechanism based on dynamic likelihood weights to prevent multiple drones from simultaneously estimating and searching for the same source, thus optimizing the energy efficiency and search coverage of the consumer AIS. Experimental results demonstrate that the DLW-CI approach significantly outperforms baseline methods regarding success rate, accuracy, and root mean square error, particularly in scenarios with relatively few sources, regardless of the presence of obstacles. Also, the effectiveness of the proposed approach is verified in a diffusion scenario generated by the computational fluid dynamics (CFD) model. Research findings indicate that our approach could improve source estimation accuracy and search efficiency by consumer drone-based AISs, making a valuable contribution to environmental safety monitoring applications within smart city infrastructure.
CityEQA: A Hierarchical LLM Agent on Embodied Question Answering Benchmark in City Space
Feb 20, 2025Embodied Question Answering (EQA) has primarily focused on indoor environments, leaving the complexities of urban settings - spanning environment, action, and perception - largely unexplored. To bridge this gap, we introduce CityEQA, a new task where an embodied agent answers open-vocabulary questions through active exploration in dynamic city spaces. To support this task, we present CityEQA-EC, the first benchmark dataset featuring 1,412 human-annotated tasks across six categories, grounded in a realistic 3D urban simulator. Moreover, we propose Planner-Manager-Actor (PMA), a novel agent tailored for CityEQA. PMA enables long-horizon planning and hierarchical task execution: the Planner breaks down the question answering into sub-tasks, the Manager maintains an object-centric cognitive map for spatial reasoning during the process control, and the specialized Actors handle navigation, exploration, and collection sub-tasks. Experiments demonstrate that PMA achieves 60.7% of human-level answering accuracy, significantly outperforming frontier-based baselines. While promising, the performance gap compared to humans highlights the need for enhanced visual reasoning in CityEQA. This work paves the way for future advancements in urban spatial intelligence. Dataset and code are available at https://github.com/BiluYong/CityEQA.git.
OnlineVPO: Align Video Diffusion Model with Online Video-Centric Preference Optimization
Dec 19, 2024



In recent years, the field of text-to-video (T2V) generation has made significant strides. Despite this progress, there is still a gap between theoretical advancements and practical application, amplified by issues like degraded image quality and flickering artifacts. Recent advancements in enhancing the video diffusion model (VDM) through feedback learning have shown promising results. However, these methods still exhibit notable limitations, such as misaligned feedback and inferior scalability. To tackle these issues, we introduce OnlineVPO, a more efficient preference learning approach tailored specifically for video diffusion models. Our method features two novel designs, firstly, instead of directly using image-based reward feedback, we leverage the video quality assessment (VQA) model trained on synthetic data as the reward model to provide distribution and modality-aligned feedback on the video diffusion model. Additionally, we introduce an online DPO algorithm to address the off-policy optimization and scalability issue in existing video preference learning frameworks. By employing the video reward model to offer concise video feedback on the fly, OnlineVPO offers effective and efficient preference guidance. Extensive experiments on the open-source video-diffusion model demonstrate OnlineVPO as a simple yet effective and more importantly scalable preference learning algorithm for video diffusion models, offering valuable insights for future advancements in this domain.
Prompt-A-Video: Prompt Your Video Diffusion Model via Preference-Aligned LLM
Dec 19, 2024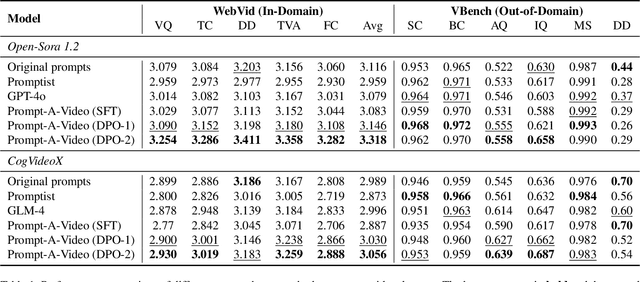

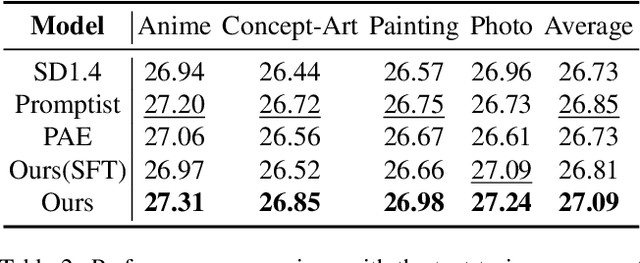

Text-to-video models have made remarkable advancements through optimization on high-quality text-video pairs, where the textual prompts play a pivotal role in determining quality of output videos. However, achieving the desired output often entails multiple revisions and iterative inference to refine user-provided prompts. Current automatic methods for refining prompts encounter challenges such as Modality-Inconsistency, Cost-Discrepancy, and Model-Unaware when applied to text-to-video diffusion models. To address these problem, we introduce an LLM-based prompt adaptation framework, termed as Prompt-A-Video, which excels in crafting Video-Centric, Labor-Free and Preference-Aligned prompts tailored to specific video diffusion model. Our approach involves a meticulously crafted two-stage optimization and alignment system. Initially, we conduct a reward-guided prompt evolution pipeline to automatically create optimal prompts pool and leverage them for supervised fine-tuning (SFT) of the LLM. Then multi-dimensional rewards are employed to generate pairwise data for the SFT model, followed by the direct preference optimization (DPO) algorithm to further facilitate preference alignment. Through extensive experimentation and comparative analyses, we validate the effectiveness of Prompt-A-Video across diverse generation models, highlighting its potential to push the boundaries of video generation.
IDA-VLM: Towards Movie Understanding via ID-Aware Large Vision-Language Model
Jul 10, 2024



The rapid advancement of Large Vision-Language models (LVLMs) has demonstrated a spectrum of emergent capabilities. Nevertheless, current models only focus on the visual content of a single scenario, while their ability to associate instances across different scenes has not yet been explored, which is essential for understanding complex visual content, such as movies with multiple characters and intricate plots. Towards movie understanding, a critical initial step for LVLMs is to unleash the potential of character identities memory and recognition across multiple visual scenarios. To achieve the goal, we propose visual instruction tuning with ID reference and develop an ID-Aware Large Vision-Language Model, IDA-VLM. Furthermore, our research introduces a novel benchmark MM-ID, to examine LVLMs on instance IDs memory and recognition across four dimensions: matching, location, question-answering, and captioning. Our findings highlight the limitations of existing LVLMs in recognizing and associating instance identities with ID reference. This paper paves the way for future artificial intelligence systems to possess multi-identity visual inputs, thereby facilitating the comprehension of complex visual narratives like movies.
PIN: A Knowledge-Intensive Dataset for Paired and Interleaved Multimodal Documents
Jun 20, 2024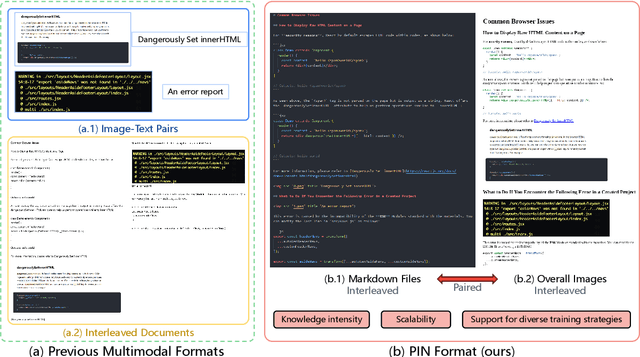
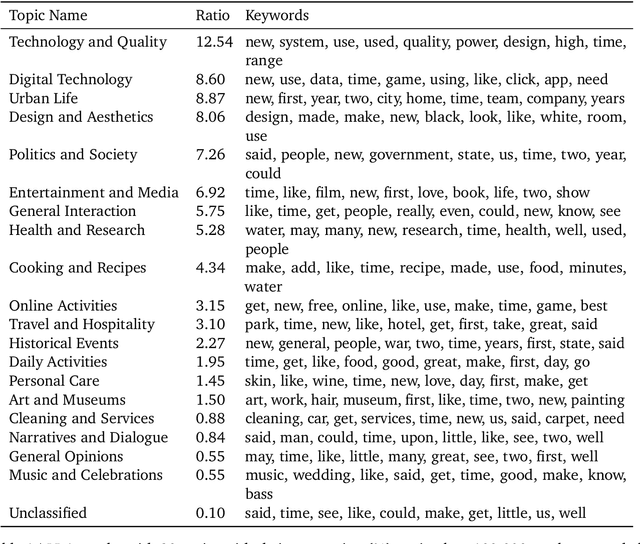


Recent advancements in Large Multimodal Models (LMMs) have leveraged extensive multimodal datasets to enhance capabilities in complex knowledge-driven tasks. However, persistent challenges in perceptual and reasoning errors limit their efficacy, particularly in interpreting intricate visual data and deducing multimodal relationships. Addressing these issues, we introduce a novel dataset format, PIN (Paired and INterleaved multimodal documents), designed to significantly improve both the depth and breadth of multimodal training. The PIN format is built on three foundational principles: knowledge intensity, scalability, and support for diverse training modalities. This innovative format combines markdown files and comprehensive images to enrich training data with a dense knowledge structure and versatile training strategies. We present PIN-14M, an open-source dataset comprising 14 million samples derived from a diverse range of Chinese and English sources, tailored to include complex web and scientific content. This dataset is constructed meticulously to ensure data quality and ethical integrity, aiming to facilitate advanced training strategies and improve model robustness against common multimodal training pitfalls. Our initial results, forming the basis of this technical report, suggest significant potential for the PIN format in refining LMM performance, with plans for future expansions and detailed evaluations of its impact on model capabilities.
Taming Lookup Tables for Efficient Image Retouching
Mar 28, 2024The widespread use of high-definition screens in edge devices, such as end-user cameras, smartphones, and televisions, is spurring a significant demand for image enhancement. Existing enhancement models often optimize for high performance while falling short of reducing hardware inference time and power consumption, especially on edge devices with constrained computing and storage resources. To this end, we propose Image Color Enhancement Lookup Table (ICELUT) that adopts LUTs for extremely efficient edge inference, without any convolutional neural network (CNN). During training, we leverage pointwise (1x1) convolution to extract color information, alongside a split fully connected layer to incorporate global information. Both components are then seamlessly converted into LUTs for hardware-agnostic deployment. ICELUT achieves near-state-of-the-art performance and remarkably low power consumption. We observe that the pointwise network structure exhibits robust scalability, upkeeping the performance even with a heavily downsampled 32x32 input image. These enable ICELUT, the first-ever purely LUT-based image enhancer, to reach an unprecedented speed of 0.4ms on GPU and 7ms on CPU, at least one order faster than any CNN solution. Codes are available at https://github.com/Stephen0808/ICELUT.
Bridging the Gap: A Unified Video Comprehension Framework for Moment Retrieval and Highlight Detection
Nov 28, 2023Video Moment Retrieval (MR) and Highlight Detection (HD) have attracted significant attention due to the growing demand for video analysis. Recent approaches treat MR and HD as similar video grounding problems and address them together with transformer-based architecture. However, we observe that the emphasis of MR and HD differs, with one necessitating the perception of local relationships and the other prioritizing the understanding of global contexts. Consequently, the lack of task-specific design will inevitably lead to limitations in associating the intrinsic specialty of two tasks. To tackle the issue, we propose a Unified Video COMprehension framework (UVCOM) to bridge the gap and jointly solve MR and HD effectively. By performing progressive integration on intra and inter-modality across multi-granularity, UVCOM achieves the comprehensive understanding in processing a video. Moreover, we present multi-aspect contrastive learning to consolidate the local relation modeling and global knowledge accumulation via well aligned multi-modal space. Extensive experiments on QVHighlights, Charades-STA, TACoS , YouTube Highlights and TVSum datasets demonstrate the effectiveness and rationality of UVCOM which outperforms the state-of-the-art methods by a remarkable margin.
Global and Local Semantic Completion Learning for Vision-Language Pre-training
Jun 12, 2023
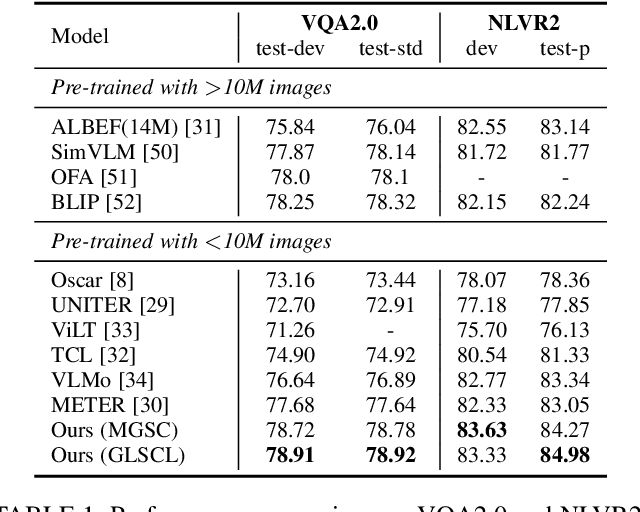
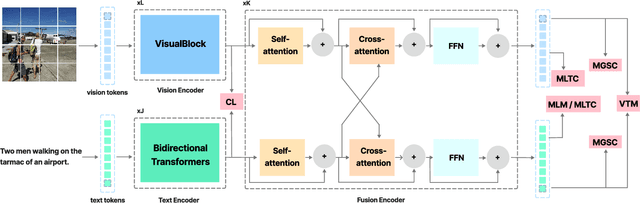
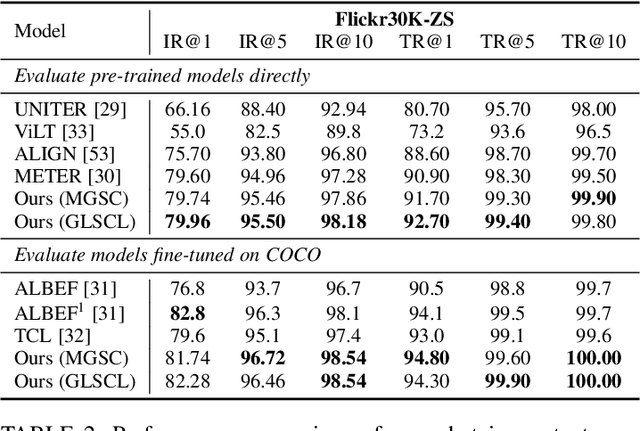
Cross-modal alignment plays a crucial role in vision-language pre-training (VLP) models, enabling them to capture meaningful associations across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-local alignment, i.e., associations between image patches and text tokens. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in a limited cross-modal alignment ability of global representations to local features of the other modality. Therefore, in this paper, we propose a novel Global and Local Semantic Completion Learning (GLSCL) task to facilitate global-local alignment and local-local alignment simultaneously. Specifically, the GLSCL task complements the missing semantics of masked data and recovers global and local features by cross-modal interactions. Our GLSCL consists of masked global semantic completion (MGSC) and masked local token completion (MLTC). MGSC promotes learning more representative global features which have a great impact on the performance of downstream tasks, and MLTC can further enhance accurate comprehension on multimodal data. Moreover, we present a flexible vision encoder, enabling our model to simultaneously perform image-text and video-text multimodal tasks. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.