 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025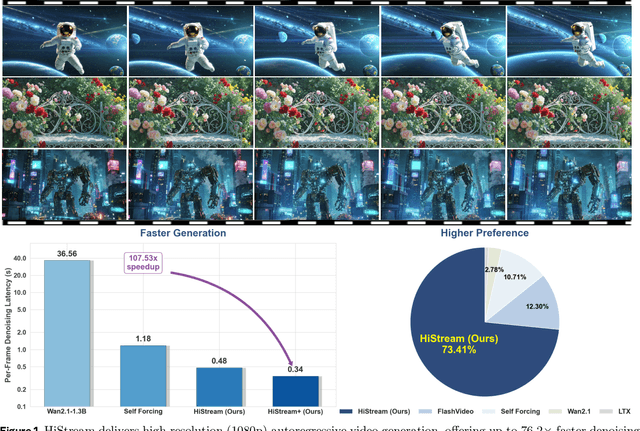
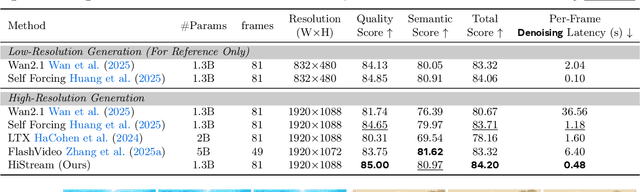
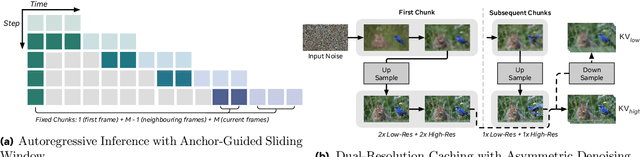
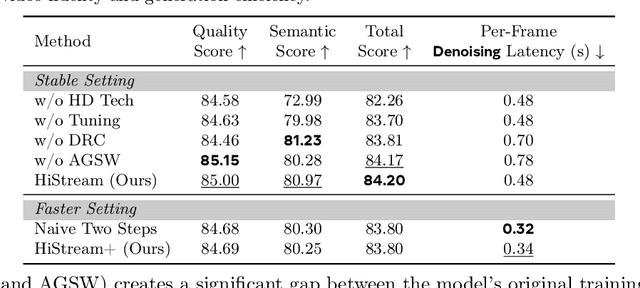
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
PixelFlow: Pixel-Space Generative Models with Flow
Apr 10, 2025



We present PixelFlow, a family of image generation models that operate directly in the raw pixel space, in contrast to the predominant latent-space models. This approach simplifies the image generation process by eliminating the need for a pre-trained Variational Autoencoder (VAE) and enabling the whole model end-to-end trainable. Through efficient cascade flow modeling, PixelFlow achieves affordable computation cost in pixel space. It achieves an FID of 1.98 on 256$\times$256 ImageNet class-conditional image generation benchmark. The qualitative text-to-image results demonstrate that PixelFlow excels in image quality, artistry, and semantic control. We hope this new paradigm will inspire and open up new opportunities for next-generation visual generation models. Code and models are available at https://github.com/ShoufaChen/PixelFlow.
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
FlashVideo:Flowing Fidelity to Detail for Efficient High-Resolution Video Generation
Feb 07, 2025DiT diffusion models have achieved great success in text-to-video generation, leveraging their scalability in model capacity and data scale. High content and motion fidelity aligned with text prompts, however, often require large model parameters and a substantial number of function evaluations (NFEs). Realistic and visually appealing details are typically reflected in high resolution outputs, further amplifying computational demands especially for single stage DiT models. To address these challenges, we propose a novel two stage framework, FlashVideo, which strategically allocates model capacity and NFEs across stages to balance generation fidelity and quality. In the first stage, prompt fidelity is prioritized through a low resolution generation process utilizing large parameters and sufficient NFEs to enhance computational efficiency. The second stage establishes flow matching between low and high resolutions, effectively generating fine details with minimal NFEs. Quantitative and visual results demonstrate that FlashVideo achieves state-of-the-art high resolution video generation with superior computational efficiency. Additionally, the two-stage design enables users to preview the initial output before committing to full resolution generation, thereby significantly reducing computational costs and wait times as well as enhancing commercial viability .
Prompt-A-Video: Prompt Your Video Diffusion Model via Preference-Aligned LLM
Dec 19, 2024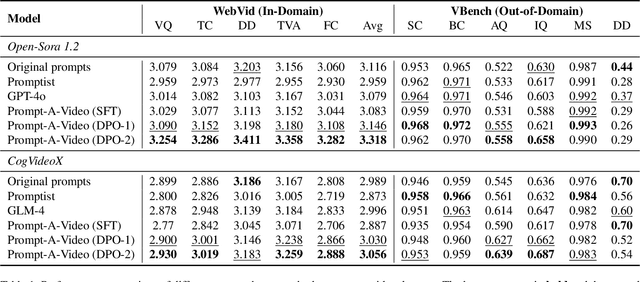

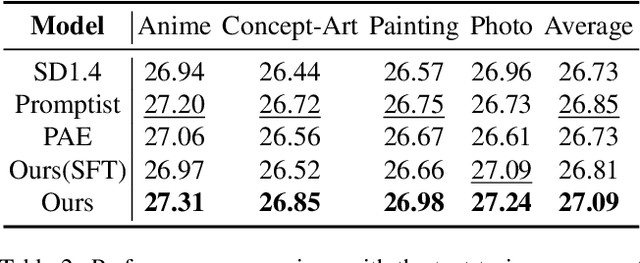

Text-to-video models have made remarkable advancements through optimization on high-quality text-video pairs, where the textual prompts play a pivotal role in determining quality of output videos. However, achieving the desired output often entails multiple revisions and iterative inference to refine user-provided prompts. Current automatic methods for refining prompts encounter challenges such as Modality-Inconsistency, Cost-Discrepancy, and Model-Unaware when applied to text-to-video diffusion models. To address these problem, we introduce an LLM-based prompt adaptation framework, termed as Prompt-A-Video, which excels in crafting Video-Centric, Labor-Free and Preference-Aligned prompts tailored to specific video diffusion model. Our approach involves a meticulously crafted two-stage optimization and alignment system. Initially, we conduct a reward-guided prompt evolution pipeline to automatically create optimal prompts pool and leverage them for supervised fine-tuning (SFT) of the LLM. Then multi-dimensional rewards are employed to generate pairwise data for the SFT model, followed by the direct preference optimization (DPO) algorithm to further facilitate preference alignment. Through extensive experimentation and comparative analyses, we validate the effectiveness of Prompt-A-Video across diverse generation models, highlighting its potential to push the boundaries of video generation.
ControlAR: Controllable Image Generation with Autoregressive Models
Oct 03, 2024



Autoregressive (AR) models have reformulated image generation as next-token prediction, demonstrating remarkable potential and emerging as strong competitors to diffusion models. However, control-to-image generation, akin to ControlNet, remains largely unexplored within AR models. Although a natural approach, inspired by advancements in Large Language Models, is to tokenize control images into tokens and prefill them into the autoregressive model before decoding image tokens, it still falls short in generation quality compared to ControlNet and suffers from inefficiency. To this end, we introduce ControlAR, an efficient and effective framework for integrating spatial controls into autoregressive image generation models. Firstly, we explore control encoding for AR models and propose a lightweight control encoder to transform spatial inputs (e.g., canny edges or depth maps) into control tokens. Then ControlAR exploits the conditional decoding method to generate the next image token conditioned on the per-token fusion between control and image tokens, similar to positional encodings. Compared to prefilling tokens, using conditional decoding significantly strengthens the control capability of AR models but also maintains the model's efficiency. Furthermore, the proposed ControlAR surprisingly empowers AR models with arbitrary-resolution image generation via conditional decoding and specific controls. Extensive experiments can demonstrate the controllability of the proposed ControlAR for the autoregressive control-to-image generation across diverse inputs, including edges, depths, and segmentation masks. Furthermore, both quantitative and qualitative results indicate that ControlAR surpasses previous state-of-the-art controllable diffusion models, e.g., ControlNet++. Code, models, and demo will soon be available at https://github.com/hustvl/ControlAR.
MobileAgentBench: An Efficient and User-Friendly Benchmark for Mobile LLM Agents
Jun 12, 2024



Large language model (LLM)-based mobile agents are increasingly popular due to their capability to interact directly with mobile phone Graphic User Interfaces (GUIs) and their potential to autonomously manage daily tasks. Despite their promising prospects in both academic and industrial sectors, little research has focused on benchmarking the performance of existing mobile agents, due to the inexhaustible states of apps and the vague definition of feasible action sequences. To address this challenge, we propose an efficient and user-friendly benchmark, MobileAgentBench, designed to alleviate the burden of extensive manual testing. We initially define 100 tasks across 10 open-source apps, categorized by multiple levels of difficulty. Subsequently, we evaluate several existing mobile agents, including AppAgent and MobileAgent, to thoroughly and systematically compare their performance. All materials are accessible on our project webpage: https://MobileAgentBench.github.io, contributing to the advancement of both academic and industrial fields.
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Jun 10, 2024



We introduce LlamaGen, a new family of image generation models that apply original ``next-token prediction'' paradigm of large language models to visual generation domain. It is an affirmative answer to whether vanilla autoregressive models, e.g., Llama, without inductive biases on visual signals can achieve state-of-the-art image generation performance if scaling properly. We reexamine design spaces of image tokenizers, scalability properties of image generation models, and their training data quality. The outcome of this exploration consists of: (1) An image tokenizer with downsample ratio of 16, reconstruction quality of 0.94 rFID and codebook usage of 97% on ImageNet benchmark. (2) A series of class-conditional image generation models ranging from 111M to 3.1B parameters, achieving 2.18 FID on ImageNet 256x256 benchmarks, outperforming the popular diffusion models such as LDM, DiT. (3) A text-conditional image generation model with 775M parameters, from two-stage training on LAION-COCO and high aesthetics quality images, demonstrating competitive performance of visual quality and text alignment. (4) We verify the effectiveness of LLM serving frameworks in optimizing the inference speed of image generation models and achieve 326% - 414% speedup. We release all models and codes to facilitate open-source community of visual generation and multimodal foundation models.
RoboCodeX: Multimodal Code Generation for Robotic Behavior Synthesis
Feb 25, 2024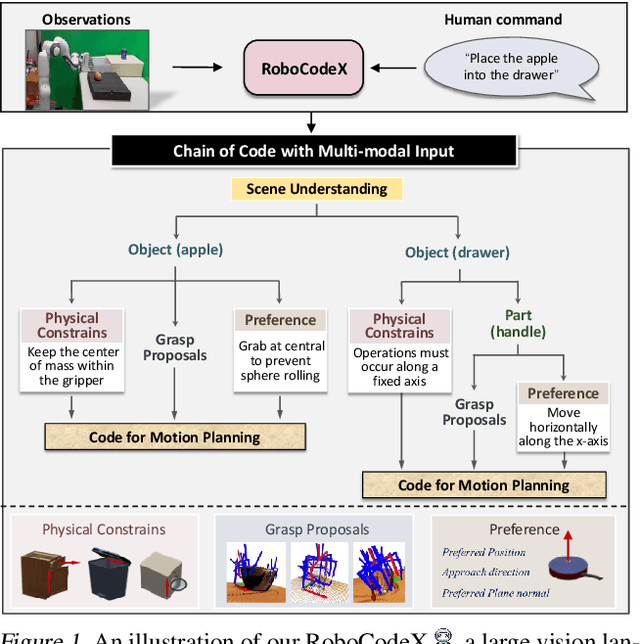
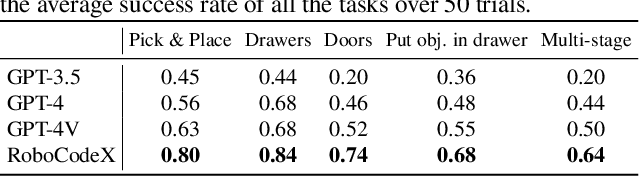
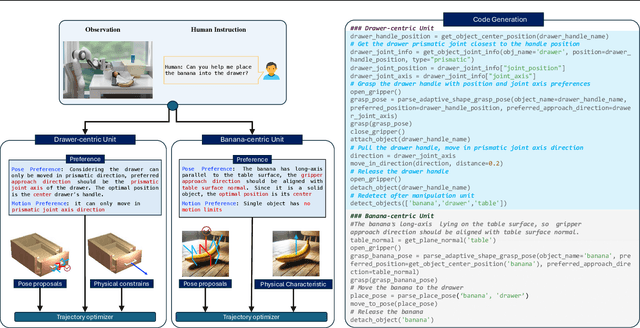

Robotic behavior synthesis, the problem of understanding multimodal inputs and generating precise physical control for robots, is an important part of Embodied AI. Despite successes in applying multimodal large language models for high-level understanding, it remains challenging to translate these conceptual understandings into detailed robotic actions while achieving generalization across various scenarios. In this paper, we propose a tree-structured multimodal code generation framework for generalized robotic behavior synthesis, termed RoboCodeX. RoboCodeX decomposes high-level human instructions into multiple object-centric manipulation units consisting of physical preferences such as affordance and safety constraints, and applies code generation to introduce generalization ability across various robotics platforms. To further enhance the capability to map conceptual and perceptual understanding into control commands, a specialized multimodal reasoning dataset is collected for pre-training and an iterative self-updating methodology is introduced for supervised fine-tuning. Extensive experiments demonstrate that RoboCodeX achieves state-of-the-art performance in both simulators and real robots on four different kinds of manipulation tasks and one navigation task.
GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation
Dec 07, 2023



In this study, we explore Transformer-based diffusion models for image and video generation. Despite the dominance of Transformer architectures in various fields due to their flexibility and scalability, the visual generative domain primarily utilizes CNN-based U-Net architectures, particularly in diffusion-based models. We introduce GenTron, a family of Generative models employing Transformer-based diffusion, to address this gap. Our initial step was to adapt Diffusion Transformers (DiTs) from class to text conditioning, a process involving thorough empirical exploration of the conditioning mechanism. We then scale GenTron from approximately 900M to over 3B parameters, observing significant improvements in visual quality. Furthermore, we extend GenTron to text-to-video generation, incorporating novel motion-free guidance to enhance video quality. In human evaluations against SDXL, GenTron achieves a 51.1% win rate in visual quality (with a 19.8% draw rate), and a 42.3% win rate in text alignment (with a 42.9% draw rate). GenTron also excels in the T2I-CompBench, underscoring its strengths in compositional generation. We believe this work will provide meaningful insights and serve as a valuable reference for future research.