 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Markov Multi-Round Conversational Image Generation with History-Conditioned MLLMs
Jan 28, 2026Conversational image generation requires a model to follow user instructions across multiple rounds of interaction, grounded in interleaved text and images that accumulate as chat history. While recent multimodal large language models (MLLMs) can generate and edit images, most existing multi-turn benchmarks and training recipes are effectively Markov: the next output depends primarily on the most recent image, enabling shortcut solutions that ignore long-range history. In this work we formalize and target the more challenging non-Markov setting, where a user may refer back to earlier states, undo changes, or reference entities introduced several rounds ago. We present (i) non-Markov multi-round data construction strategies, including rollback-style editing that forces retrieval of earlier visual states and name-based multi-round personalization that binds names to appearances across rounds; (ii) a history-conditioned training and inference framework with token-level caching to prevent multi-round identity drift; and (iii) enabling improvements for high-fidelity image reconstruction and editable personalization, including a reconstruction-based DiT detokenizer and a multi-stage fine-tuning curriculum. We demonstrate that explicitly training for non-Markov interactions yields substantial improvements in multi-round consistency and instruction compliance, while maintaining strong single-round editing and personalization.
MoCha: Towards Movie-Grade Talking Character Synthesis
Mar 30, 2025
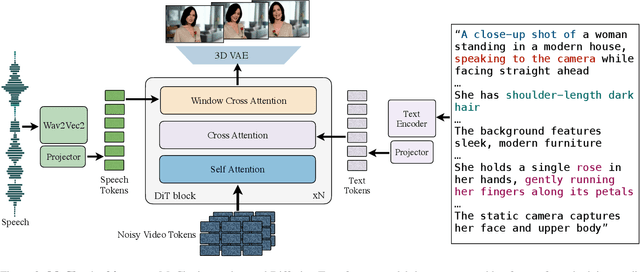

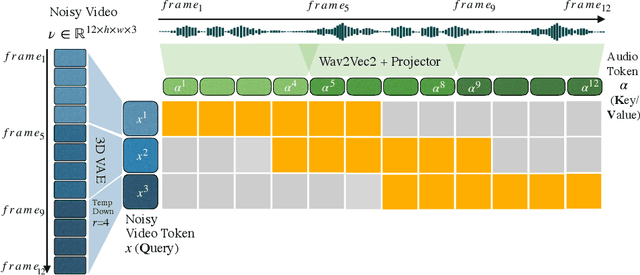
Recent advancements in video generation have achieved impressive motion realism, yet they often overlook character-driven storytelling, a crucial task for automated film, animation generation. We introduce Talking Characters, a more realistic task to generate talking character animations directly from speech and text. Unlike talking head, Talking Characters aims at generating the full portrait of one or more characters beyond the facial region. In this paper, we propose MoCha, the first of its kind to generate talking characters. To ensure precise synchronization between video and speech, we propose a speech-video window attention mechanism that effectively aligns speech and video tokens. To address the scarcity of large-scale speech-labeled video datasets, we introduce a joint training strategy that leverages both speech-labeled and text-labeled video data, significantly improving generalization across diverse character actions. We also design structured prompt templates with character tags, enabling, for the first time, multi-character conversation with turn-based dialogue-allowing AI-generated characters to engage in context-aware conversations with cinematic coherence. Extensive qualitative and quantitative evaluations, including human preference studies and benchmark comparisons, demonstrate that MoCha sets a new standard for AI-generated cinematic storytelling, achieving superior realism, expressiveness, controllability and generalization.
DirectorLLM for Human-Centric Video Generation
Dec 19, 2024



In this paper, we introduce DirectorLLM, a novel video generation model that employs a large language model (LLM) to orchestrate human poses within videos. As foundational text-to-video models rapidly evolve, the demand for high-quality human motion and interaction grows. To address this need and enhance the authenticity of human motions, we extend the LLM from a text generator to a video director and human motion simulator. Utilizing open-source resources from Llama 3, we train the DirectorLLM to generate detailed instructional signals, such as human poses, to guide video generation. This approach offloads the simulation of human motion from the video generator to the LLM, effectively creating informative outlines for human-centric scenes. These signals are used as conditions by the video renderer, facilitating more realistic and prompt-following video generation. As an independent LLM module, it can be applied to different video renderers, including UNet and DiT, with minimal effort. Experiments on automatic evaluation benchmarks and human evaluations show that our model outperforms existing ones in generating videos with higher human motion fidelity, improved prompt faithfulness, and enhanced rendered subject naturalness.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation
Dec 07, 2023



In this study, we explore Transformer-based diffusion models for image and video generation. Despite the dominance of Transformer architectures in various fields due to their flexibility and scalability, the visual generative domain primarily utilizes CNN-based U-Net architectures, particularly in diffusion-based models. We introduce GenTron, a family of Generative models employing Transformer-based diffusion, to address this gap. Our initial step was to adapt Diffusion Transformers (DiTs) from class to text conditioning, a process involving thorough empirical exploration of the conditioning mechanism. We then scale GenTron from approximately 900M to over 3B parameters, observing significant improvements in visual quality. Furthermore, we extend GenTron to text-to-video generation, incorporating novel motion-free guidance to enhance video quality. In human evaluations against SDXL, GenTron achieves a 51.1% win rate in visual quality (with a 19.8% draw rate), and a 42.3% win rate in text alignment (with a 42.9% draw rate). GenTron also excels in the T2I-CompBench, underscoring its strengths in compositional generation. We believe this work will provide meaningful insights and serve as a valuable reference for future research.
Gen2Det: Generate to Detect
Dec 07, 2023Recently diffusion models have shown improvement in synthetic image quality as well as better control in generation. We motivate and present Gen2Det, a simple modular pipeline to create synthetic training data for object detection for free by leveraging state-of-the-art grounded image generation methods. Unlike existing works which generate individual object instances, require identifying foreground followed by pasting on other images, we simplify to directly generating scene-centric images. In addition to the synthetic data, Gen2Det also proposes a suite of techniques to best utilize the generated data, including image-level filtering, instance-level filtering, and better training recipe to account for imperfections in the generation. Using Gen2Det, we show healthy improvements on object detection and segmentation tasks under various settings and agnostic to detection methods. In the long-tailed detection setting on LVIS, Gen2Det improves the performance on rare categories by a large margin while also significantly improving the performance on other categories, e.g. we see an improvement of 2.13 Box AP and 1.84 Mask AP over just training on real data on LVIS with Mask R-CNN. In the low-data regime setting on COCO, Gen2Det consistently improves both Box and Mask AP by 2.27 and 1.85 points. In the most general detection setting, Gen2Det still demonstrates robust performance gains, e.g. it improves the Box and Mask AP on COCO by 0.45 and 0.32 points.
Context Diffusion: In-Context Aware Image Generation
Dec 06, 2023We propose Context Diffusion, a diffusion-based framework that enables image generation models to learn from visual examples presented in context. Recent work tackles such in-context learning for image generation, where a query image is provided alongside context examples and text prompts. However, the quality and fidelity of the generated images deteriorate when the prompt is not present, demonstrating that these models are unable to truly learn from the visual context. To address this, we propose a novel framework that separates the encoding of the visual context and preserving the structure of the query images. This results in the ability to learn from the visual context and text prompts, but also from either one of them. Furthermore, we enable our model to handle few-shot settings, to effectively address diverse in-context learning scenarios. Our experiments and user study demonstrate that Context Diffusion excels in both in-domain and out-of-domain tasks, resulting in an overall enhancement in image quality and fidelity compared to counterpart models.
Text-to-Sticker: Style Tailoring Latent Diffusion Models for Human Expression
Nov 17, 2023



We introduce Style Tailoring, a recipe to finetune Latent Diffusion Models (LDMs) in a distinct domain with high visual quality, prompt alignment and scene diversity. We choose sticker image generation as the target domain, as the images significantly differ from photorealistic samples typically generated by large-scale LDMs. We start with a competent text-to-image model, like Emu, and show that relying on prompt engineering with a photorealistic model to generate stickers leads to poor prompt alignment and scene diversity. To overcome these drawbacks, we first finetune Emu on millions of sticker-like images collected using weak supervision to elicit diversity. Next, we curate human-in-the-loop (HITL) Alignment and Style datasets from model generations, and finetune to improve prompt alignment and style alignment respectively. Sequential finetuning on these datasets poses a tradeoff between better style alignment and prompt alignment gains. To address this tradeoff, we propose a novel fine-tuning method called Style Tailoring, which jointly fits the content and style distribution and achieves best tradeoff. Evaluation results show our method improves visual quality by 14%, prompt alignment by 16.2% and scene diversity by 15.3%, compared to prompt engineering the base Emu model for stickers generation.
FaD-VLP: Fashion Vision-and-Language Pre-training towards Unified Retrieval and Captioning
Oct 26, 2022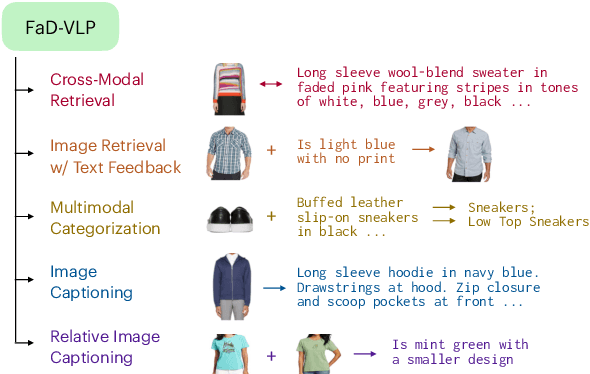

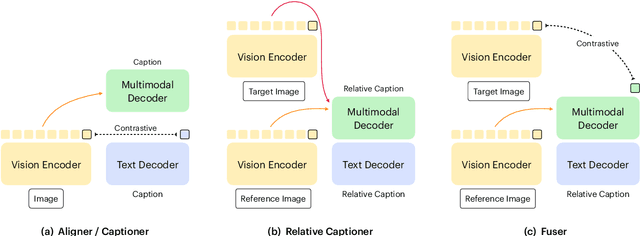
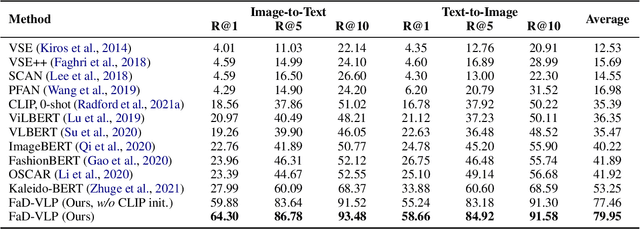
Multimodal tasks in the fashion domain have significant potential for e-commerce, but involve challenging vision-and-language learning problems - e.g., retrieving a fashion item given a reference image plus text feedback from a user. Prior works on multimodal fashion tasks have either been limited by the data in individual benchmarks, or have leveraged generic vision-and-language pre-training but have not taken advantage of the characteristics of fashion data. Additionally, these works have mainly been restricted to multimodal understanding tasks. To address these gaps, we make two key contributions. First, we propose a novel fashion-specific pre-training framework based on weakly-supervised triplets constructed from fashion image-text pairs. We show the triplet-based tasks are an effective addition to standard multimodal pre-training tasks. Second, we propose a flexible decoder-based model architecture capable of both fashion retrieval and captioning tasks. Together, our model design and pre-training approach are competitive on a diverse set of fashion tasks, including cross-modal retrieval, image retrieval with text feedback, image captioning, relative image captioning, and multimodal categorization.
CommerceMM: Large-Scale Commerce MultiModal Representation Learning with Omni Retrieval
Feb 15, 2022
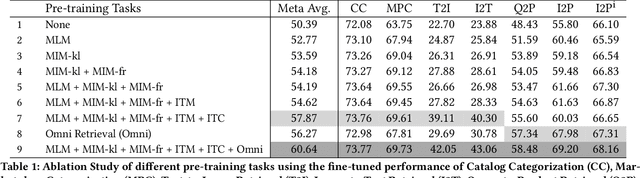
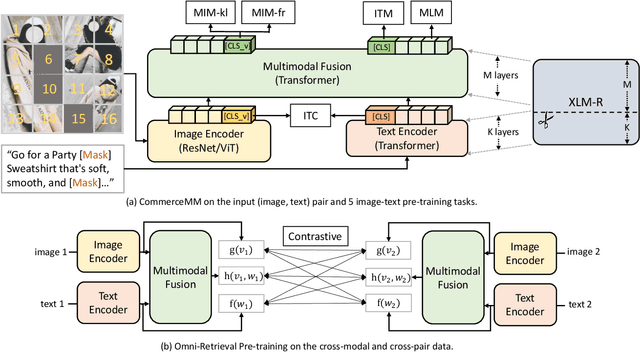

We introduce CommerceMM - a multimodal model capable of providing a diverse and granular understanding of commerce topics associated to the given piece of content (image, text, image+text), and having the capability to generalize to a wide range of tasks, including Multimodal Categorization, Image-Text Retrieval, Query-to-Product Retrieval, Image-to-Product Retrieval, etc. We follow the pre-training + fine-tuning training regime and present 5 effective pre-training tasks on image-text pairs. To embrace more common and diverse commerce data with text-to-multimodal, image-to-multimodal, and multimodal-to-multimodal mapping, we propose another 9 novel cross-modal and cross-pair retrieval tasks, called Omni-Retrieval pre-training. The pre-training is conducted in an efficient manner with only two forward/backward updates for the combined 14 tasks. Extensive experiments and analysis show the effectiveness of each task. When combining all pre-training tasks, our model achieves state-of-the-art performance on 7 commerce-related downstream tasks after fine-tuning. Additionally, we propose a novel approach of modality randomization to dynamically adjust our model under different efficiency constraints.