 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommerceMM: Large-Scale Commerce MultiModal Representation Learning with Omni Retrieval
Paper and Code
Feb 15, 2022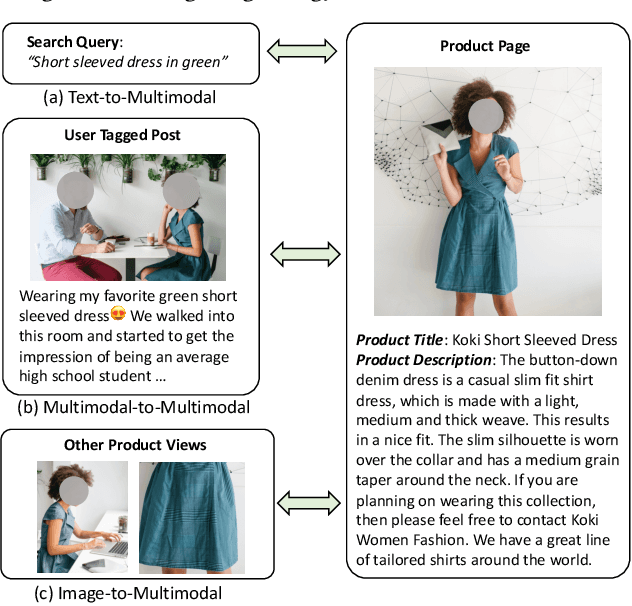
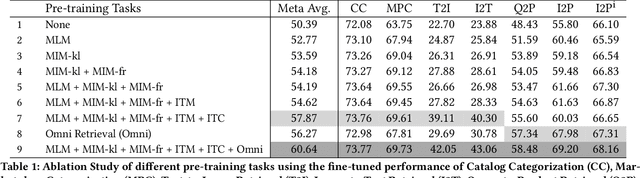
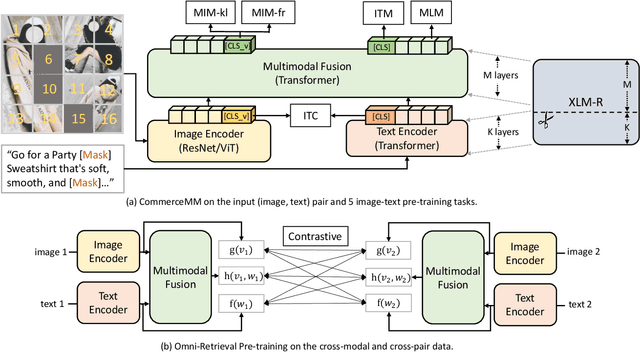

We introduce CommerceMM - a multimodal model capable of providing a diverse and granular understanding of commerce topics associated to the given piece of content (image, text, image+text), and having the capability to generalize to a wide range of tasks, including Multimodal Categorization, Image-Text Retrieval, Query-to-Product Retrieval, Image-to-Product Retrieval, etc. We follow the pre-training + fine-tuning training regime and present 5 effective pre-training tasks on image-text pairs. To embrace more common and diverse commerce data with text-to-multimodal, image-to-multimodal, and multimodal-to-multimodal mapping, we propose another 9 novel cross-modal and cross-pair retrieval tasks, called Omni-Retrieval pre-training. The pre-training is conducted in an efficient manner with only two forward/backward updates for the combined 14 tasks. Extensive experiments and analysis show the effectiveness of each task. When combining all pre-training tasks, our model achieves state-of-the-art performance on 7 commerce-related downstream tasks after fine-tuning. Additionally, we propose a novel approach of modality randomization to dynamically adjust our model under different efficiency constraints.