 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtRAG: Retrieval-Augmented Generation with Structured Context for Visual Art Understanding
May 09, 2025Understanding visual art requires reasoning across multiple perspectives -- cultural, historical, and stylistic -- beyond mere object recognition. While recent multimodal large language models (MLLMs) perform well on general image captioning, they often fail to capture the nuanced interpretations that fine art demands. We propose ArtRAG, a novel, training-free framework that combines structured knowledge with retrieval-augmented generation (RAG) for multi-perspective artwork explanation. ArtRAG automatically constructs an Art Context Knowledge Graph (ACKG) from domain-specific textual sources, organizing entities such as artists, movements, themes, and historical events into a rich, interpretable graph. At inference time, a multi-granular structured retriever selects semantically and topologically relevant subgraphs to guide generation. This enables MLLMs to produce contextually grounded, culturally informed art descriptions. Experiments on the SemArt and Artpedia datasets show that ArtRAG outperforms several heavily trained baselines. Human evaluations further confirm that ArtRAG generates coherent, insightful, and culturally enriched interpretations.
TULIP: Token-length Upgraded CLIP
Oct 13, 2024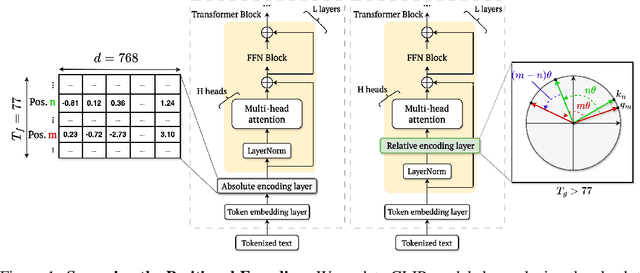
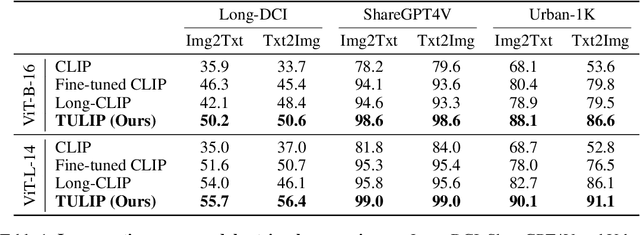
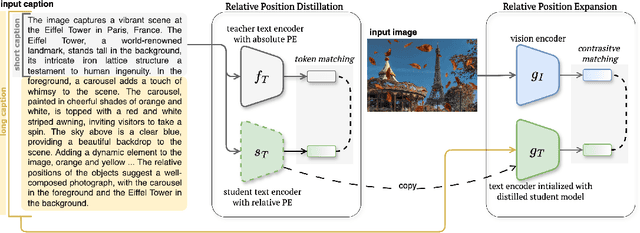
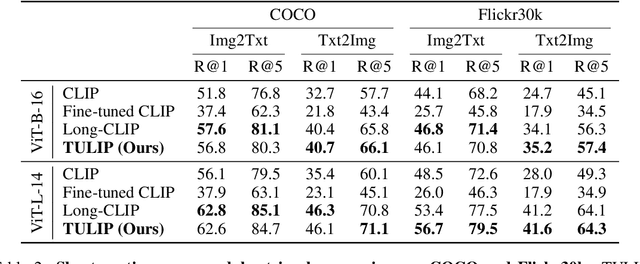
We address the challenge of representing long captions in vision-language models, such as CLIP. By design these models are limited by fixed, absolute positional encodings, restricting inputs to a maximum of 77 tokens and hindering performance on tasks requiring longer descriptions. Although recent work has attempted to overcome this limit, their proposed approaches struggle to model token relationships over longer distances and simply extend to a fixed new token length. Instead, we propose a generalizable method, named TULIP, able to upgrade the token length to any length for CLIP-like models. We do so by improving the architecture with relative position encodings, followed by a training procedure that (i) distills the original CLIP text encoder into an encoder with relative position encodings and (ii) enhances the model for aligning longer captions with images. By effectively encoding captions longer than the default 77 tokens, our model outperforms baselines on cross-modal tasks such as retrieval and text-to-image generation.
In-Context Learning Improves Compositional Understanding of Vision-Language Models
Jul 22, 2024Vision-Language Models (VLMs) have shown remarkable capabilities in a large number of downstream tasks. Nonetheless, compositional image understanding remains a rather difficult task due to the object bias present in training data. In this work, we investigate the reasons for such a lack of capability by performing an extensive bench-marking of compositional understanding in VLMs. We compare contrastive models with generative ones and analyze their differences in architecture, pre-training data, and training tasks and losses. Furthermore, we leverage In-Context Learning (ICL) as a way to improve the ability of VLMs to perform more complex reasoning and understanding given an image. Our extensive experiments demonstrate that our proposed approach outperforms baseline models across multiple compositional understanding datasets.
Context Diffusion: In-Context Aware Image Generation
Dec 06, 2023We propose Context Diffusion, a diffusion-based framework that enables image generation models to learn from visual examples presented in context. Recent work tackles such in-context learning for image generation, where a query image is provided alongside context examples and text prompts. However, the quality and fidelity of the generated images deteriorate when the prompt is not present, demonstrating that these models are unable to truly learn from the visual context. To address this, we propose a novel framework that separates the encoding of the visual context and preserving the structure of the query images. This results in the ability to learn from the visual context and text prompts, but also from either one of them. Furthermore, we enable our model to handle few-shot settings, to effectively address diverse in-context learning scenarios. Our experiments and user study demonstrate that Context Diffusion excels in both in-domain and out-of-domain tasks, resulting in an overall enhancement in image quality and fidelity compared to counterpart models.
Small Visual Language Models can also be Open-Ended Few-Shot Learners
Sep 30, 2023We present Self-Context Adaptation (SeCAt), a self-supervised approach that unlocks open-ended few-shot abilities of small visual language models. Our proposed adaptation algorithm explicitly learns from symbolic, yet self-supervised training tasks. Specifically, our approach imitates image captions in a self-supervised way based on clustering a large pool of images followed by assigning semantically-unrelated names to clusters. By doing so, we construct the `self-context', a training signal consisting of interleaved sequences of image and pseudo-caption pairs and a query image for which the model is trained to produce the right pseudo-caption. We demonstrate the performance and flexibility of SeCAt on several multimodal few-shot datasets, spanning various granularities. By using models with approximately 1B parameters we outperform the few-shot abilities of much larger models, such as Frozen and FROMAGe. SeCAt opens new possibilities for research in open-ended few-shot learning that otherwise requires access to large or proprietary models.
Open-Ended Medical Visual Question Answering Through Prefix Tuning of Language Models
Mar 10, 2023



Medical Visual Question Answering (VQA) is an important challenge, as it would lead to faster and more accurate diagnoses and treatment decisions. Most existing methods approach it as a multi-class classification problem, which restricts the outcome to a predefined closed-set of curated answers. We focus on open-ended VQA and motivated by the recent advances in language models consider it as a generative task. Leveraging pre-trained language models, we introduce a novel method particularly suited for small, domain-specific, medical datasets. To properly communicate the medical images to the language model, we develop a network that maps the extracted visual features to a set of learnable tokens. Then, alongside the question, these learnable tokens directly prompt the language model. We explore recent parameter-efficient fine-tuning strategies for language models, which allow for resource- and data-efficient fine-tuning. We evaluate our approach on the prime medical VQA benchmarks, namely, Slake, OVQA and PathVQA. The results demonstrate that our approach outperforms existing methods across various training settings while also being computationally efficient.
Meta Learning to Bridge Vision and Language Models for Multimodal Few-Shot Learning
Feb 28, 2023



Multimodal few-shot learning is challenging due to the large domain gap between vision and language modalities. Existing methods are trying to communicate visual concepts as prompts to frozen language models, but rely on hand-engineered task induction to reduce the hypothesis space. To make the whole process learnable, we introduce a multimodal meta-learning approach. Specifically, our approach decomposes the training of the model into a set of related multimodal few-shot tasks. We define a meta-mapper network, acting as a meta-learner, to efficiently bridge frozen large-scale vision and language models and leverage their already learned capacity. By updating the learnable parameters only of the meta-mapper, it learns to accrue shared meta-knowledge among these tasks. Thus, it can rapidly adapt to newly presented samples with only a few gradient updates. Importantly, it induces the task in a completely data-driven manner, with no need for a hand-engineered task induction. We evaluate our approach on recently proposed multimodal few-shot benchmarks, measuring how rapidly the model can bind novel visual concepts to words and answer visual questions by observing only a limited set of labeled examples. The experimental results show that our meta-learning approach outperforms the baseline across multiple datasets and various training settings while being computationally more efficient.
LifeLonger: A Benchmark for Continual Disease Classification
Apr 12, 2022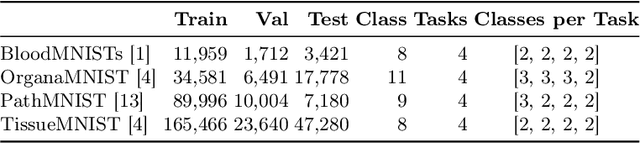
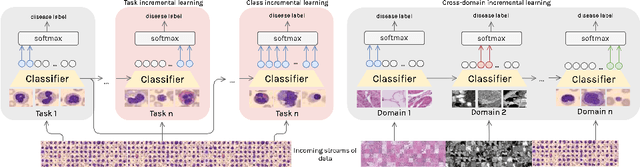
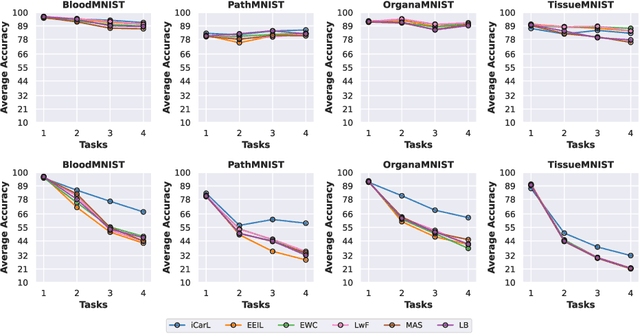
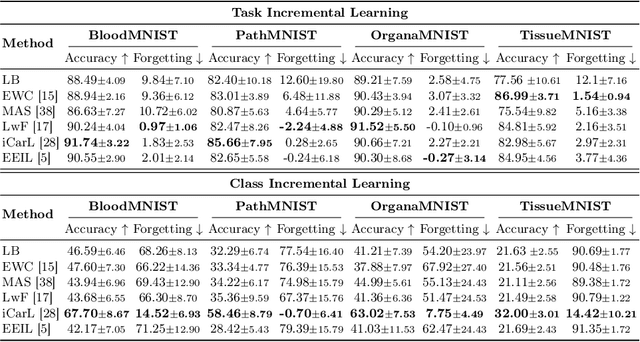
Deep learning models have shown a great effectiveness in recognition of findings in medical images. However, they cannot handle the ever-changing clinical environment, bringing newly annotated medical data from different sources. To exploit the incoming streams of data, these models would benefit largely from sequentially learning from new samples, without forgetting the previously obtained knowledge. In this paper we introduce LifeLonger, a benchmark for continual disease classification on the MedMNIST collection, by applying existing state-of-the-art continual learning methods. In particular, we consider three continual learning scenarios, namely, task and class incremental learning and the newly defined cross-domain incremental learning. Task and class incremental learning of diseases address the issue of classifying new samples without re-training the models from scratch, while cross-domain incremental learning addresses the issue of dealing with datasets originating from different institutions while retaining the previously obtained knowledge. We perform a thorough analysis of the performance and examine how the well-known challenges of continual learning, such as the catastrophic forgetting exhibit themselves in this setting. The encouraging results demonstrate that continual learning has a major potential to advance disease classification and to produce a more robust and efficient learning framework for clinical settings. The code repository, data partitions and baseline results for the complete benchmark will be made publicly available.
Variational Topic Inference for Chest X-Ray Report Generation
Jul 15, 2021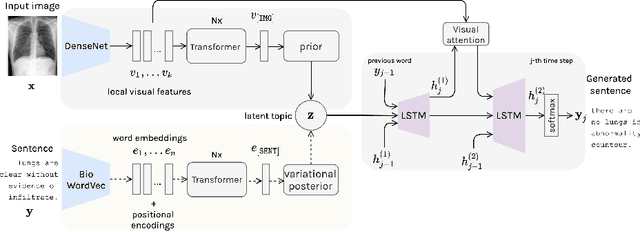



Automating report generation for medical imaging promises to reduce workload and assist diagnosis in clinical practice. Recent work has shown that deep learning models can successfully caption natural images. However, learning from medical data is challenging due to the diversity and uncertainty inherent in the reports written by different radiologists with discrepant expertise and experience. To tackle these challenges, we propose variational topic inference for automatic report generation. Specifically, we introduce a set of topics as latent variables to guide sentence generation by aligning image and language modalities in a latent space. The topics are inferred in a conditional variational inference framework, with each topic governing the generation of a sentence in the report. Further, we adopt a visual attention module that enables the model to attend to different locations in the image and generate more informative descriptions. We conduct extensive experiments on two benchmarks, namely Indiana U. Chest X-rays and MIMIC-CXR. The results demonstrate that our proposed variational topic inference method can generate novel reports rather than mere copies of reports used in training, while still achieving comparable performance to state-of-the-art methods in terms of standard language generation criteria.