 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Embeddings for Multi-Lingual Structured Representations of Radiology Reports
Sep 14, 2023


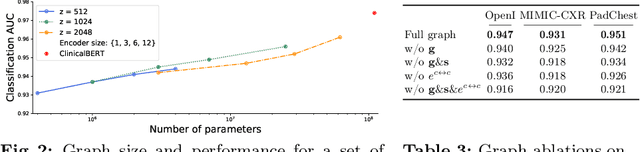
The way we analyse clinical texts has undergone major changes over the last years. The introduction of language models such as BERT led to adaptations for the (bio)medical domain like PubMedBERT and ClinicalBERT. These models rely on large databases of archived medical documents. While performing well in terms of accuracy, both the lack of interpretability and limitations to transfer across languages limit their use in clinical setting. We introduce a novel light-weight graph-based embedding method specifically catering radiology reports. It takes into account the structure and composition of the report, while also connecting medical terms in the report through the multi-lingual SNOMED Clinical Terms knowledge base. The resulting graph embedding uncovers the underlying relationships among clinical terms, achieving a representation that is better understandable for clinicians and clinically more accurate, without reliance on large pre-training datasets. We show the use of this embedding on two tasks namely disease classification of X-ray reports and image classification. For disease classification our model is competitive with its BERT-based counterparts, while being magnitudes smaller in size and training data requirements. For image classification, we show the effectiveness of the graph embedding leveraging cross-modal knowledge transfer and show how this method is usable across different languages.
Open-Ended Medical Visual Question Answering Through Prefix Tuning of Language Models
Mar 10, 2023



Medical Visual Question Answering (VQA) is an important challenge, as it would lead to faster and more accurate diagnoses and treatment decisions. Most existing methods approach it as a multi-class classification problem, which restricts the outcome to a predefined closed-set of curated answers. We focus on open-ended VQA and motivated by the recent advances in language models consider it as a generative task. Leveraging pre-trained language models, we introduce a novel method particularly suited for small, domain-specific, medical datasets. To properly communicate the medical images to the language model, we develop a network that maps the extracted visual features to a set of learnable tokens. Then, alongside the question, these learnable tokens directly prompt the language model. We explore recent parameter-efficient fine-tuning strategies for language models, which allow for resource- and data-efficient fine-tuning. We evaluate our approach on the prime medical VQA benchmarks, namely, Slake, OVQA and PathVQA. The results demonstrate that our approach outperforms existing methods across various training settings while also being computationally efficient.
X-TRA: Improving Chest X-ray Tasks with Cross-Modal Retrieval Augmentation
Feb 22, 2023


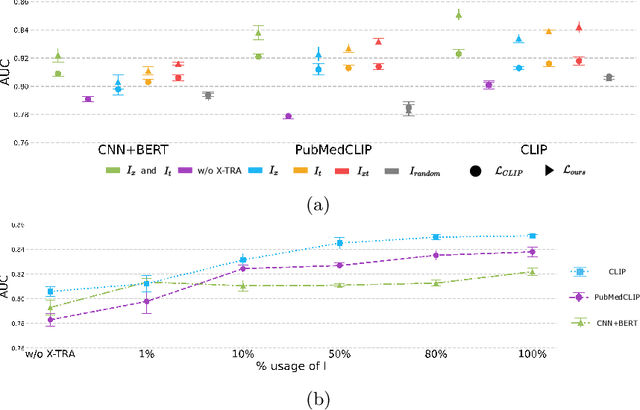
An important component of human analysis of medical images and their context is the ability to relate newly seen things to related instances in our memory. In this paper we mimic this ability by using multi-modal retrieval augmentation and apply it to several tasks in chest X-ray analysis. By retrieving similar images and/or radiology reports we expand and regularize the case at hand with additional knowledge, while maintaining factual knowledge consistency. The method consists of two components. First, vision and language modalities are aligned using a pre-trained CLIP model. To enforce that the retrieval focus will be on detailed disease-related content instead of global visual appearance it is fine-tuned using disease class information. Subsequently, we construct a non-parametric retrieval index, which reaches state-of-the-art retrieval levels. We use this index in our downstream tasks to augment image representations through multi-head attention for disease classification and report retrieval. We show that retrieval augmentation gives considerable improvements on these tasks. Our downstream report retrieval even shows to be competitive with dedicated report generation methods, paving the path for this method in medical imaging.
Probabilistic Integration of Object Level Annotations in Chest X-ray Classification
Oct 13, 2022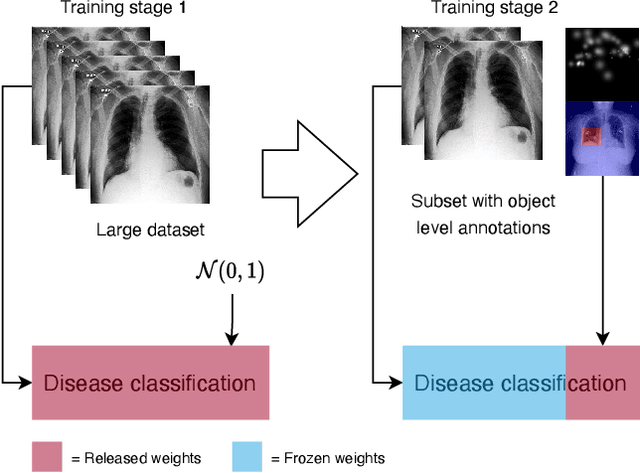

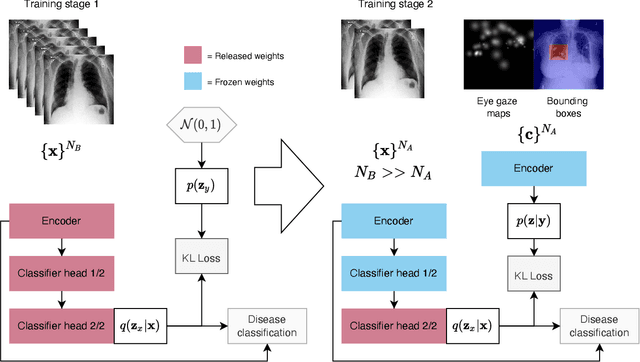
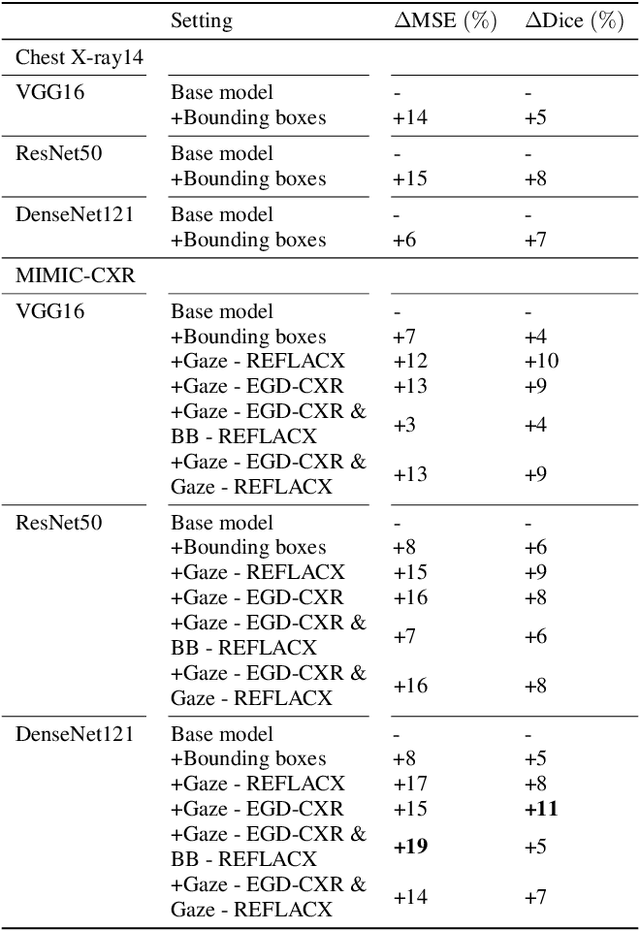
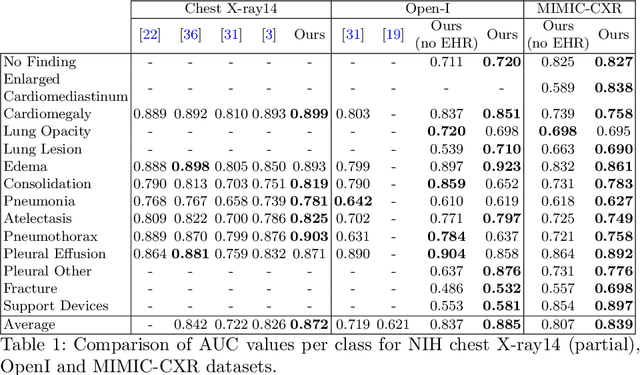
Medical image datasets and their annotations are not growing as fast as their equivalents in the general domain. This makes translation from the newest, more data-intensive methods that have made a large impact on the vision field increasingly more difficult and less efficient. In this paper, we propose a new probabilistic latent variable model for disease classification in chest X-ray images. Specifically we consider chest X-ray datasets that contain global disease labels, and for a smaller subset contain object level expert annotations in the form of eye gaze patterns and disease bounding boxes. We propose a two-stage optimization algorithm which is able to handle these different label granularities through a single training pipeline in a two-stage manner. In our pipeline global dataset features are learned in the lower level layers of the model. The specific details and nuances in the fine-grained expert object-level annotations are learned in the final layers of the model using a knowledge distillation method inspired by conditional variational inference. Subsequently, model weights are frozen to guide this learning process and prevent overfitting on the smaller richly annotated data subsets. The proposed method yields consistent classification improvement across different backbones on the common benchmark datasets Chest X-ray14 and MIMIC-CXR. This shows how two-stage learning of labels from coarse to fine-grained, in particular with object level annotations, is an effective method for more optimal annotation usage.
LifeLonger: A Benchmark for Continual Disease Classification
Apr 12, 2022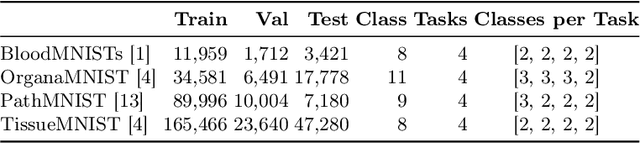
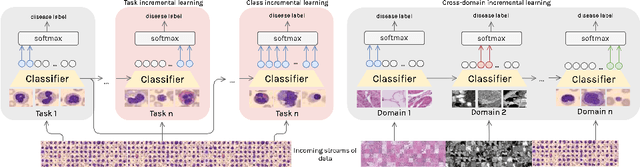
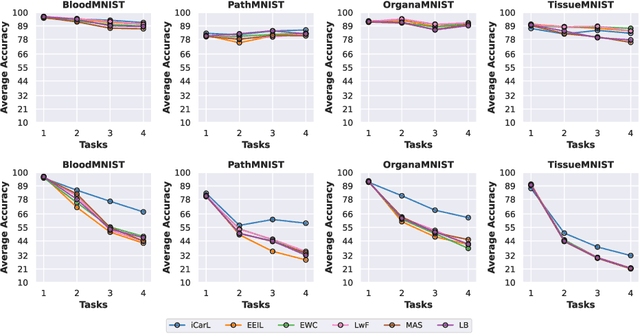
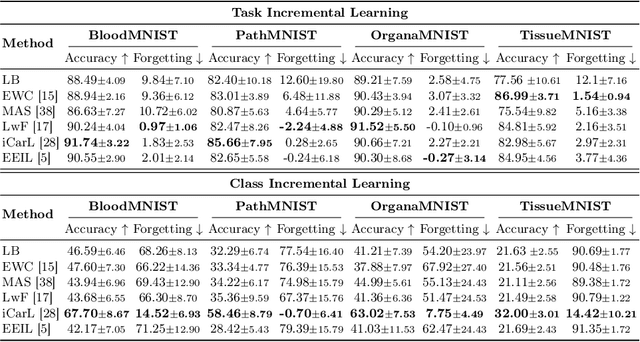
Deep learning models have shown a great effectiveness in recognition of findings in medical images. However, they cannot handle the ever-changing clinical environment, bringing newly annotated medical data from different sources. To exploit the incoming streams of data, these models would benefit largely from sequentially learning from new samples, without forgetting the previously obtained knowledge. In this paper we introduce LifeLonger, a benchmark for continual disease classification on the MedMNIST collection, by applying existing state-of-the-art continual learning methods. In particular, we consider three continual learning scenarios, namely, task and class incremental learning and the newly defined cross-domain incremental learning. Task and class incremental learning of diseases address the issue of classifying new samples without re-training the models from scratch, while cross-domain incremental learning addresses the issue of dealing with datasets originating from different institutions while retaining the previously obtained knowledge. We perform a thorough analysis of the performance and examine how the well-known challenges of continual learning, such as the catastrophic forgetting exhibit themselves in this setting. The encouraging results demonstrate that continual learning has a major potential to advance disease classification and to produce a more robust and efficient learning framework for clinical settings. The code repository, data partitions and baseline results for the complete benchmark will be made publicly available.
Variational Knowledge Distillation for Disease Classification in Chest X-Rays
Mar 19, 2021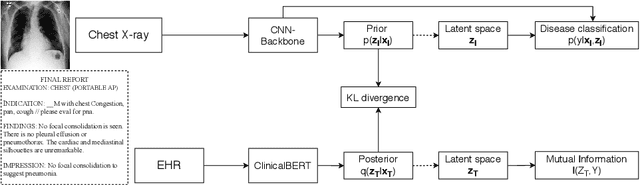


Disease classification relying solely on imaging data attracts great interest in medical image analysis. Current models could be further improved, however, by also employing Electronic Health Records (EHRs), which contain rich information on patients and findings from clinicians. It is challenging to incorporate this information into disease classification due to the high reliance on clinician input in EHRs, limiting the possibility for automated diagnosis. In this paper, we propose \textit{variational knowledge distillation} (VKD), which is a new probabilistic inference framework for disease classification based on X-rays that leverages knowledge from EHRs. Specifically, we introduce a conditional latent variable model, where we infer the latent representation of the X-ray image with the variational posterior conditioning on the associated EHR text. By doing so, the model acquires the ability to extract the visual features relevant to the disease during learning and can therefore perform more accurate classification for unseen patients at inference based solely on their X-ray scans. We demonstrate the effectiveness of our method on three public benchmark datasets with paired X-ray images and EHRs. The results show that the proposed variational knowledge distillation can consistently improve the performance of medical image classification and significantly surpasses current methods.
Predicting Scores of Medical Imaging Segmentation Methods with Meta-Learning
May 08, 2020


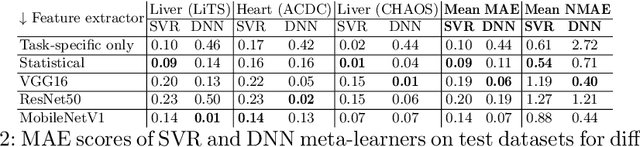
Deep learning has led to state-of-the-art results for many medical imaging tasks, such as segmentation of different anatomical structures. With the increased numbers of deep learning publications and openly available code, the approach to choosing a model for a new task becomes more complicated, while time and (computational) resources are limited. A possible solution to choosing a model efficiently is meta-learning, a learning method in which prior performance of a model is used to predict the performance for new tasks. We investigate meta-learning for segmentation across ten datasets of different organs and modalities. We propose four ways to represent each dataset by meta-features: one based on statistical features of the images and three are based on deep learning features. We use support vector regression and deep neural networks to learn the relationship between the meta-features and prior model performance. On three external test datasets these methods give Dice scores within 0.10 of the true performance. These results demonstrate the potential of meta-learning in medical imaging.