 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Embeddings for Multi-Lingual Structured Representations of Radiology Reports
Paper and Code



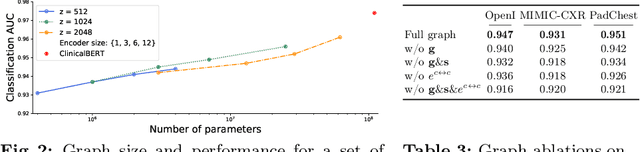
The way we analyse clinical texts has undergone major changes over the last years. The introduction of language models such as BERT led to adaptations for the (bio)medical domain like PubMedBERT and ClinicalBERT. These models rely on large databases of archived medical documents. While performing well in terms of accuracy, both the lack of interpretability and limitations to transfer across languages limit their use in clinical setting. We introduce a novel light-weight graph-based embedding method specifically catering radiology reports. It takes into account the structure and composition of the report, while also connecting medical terms in the report through the multi-lingual SNOMED Clinical Terms knowledge base. The resulting graph embedding uncovers the underlying relationships among clinical terms, achieving a representation that is better understandable for clinicians and clinically more accurate, without reliance on large pre-training datasets. We show the use of this embedding on two tasks namely disease classification of X-ray reports and image classification. For disease classification our model is competitive with its BERT-based counterparts, while being magnitudes smaller in size and training data requirements. For image classification, we show the effectiveness of the graph embedding leveraging cross-modal knowledge transfer and show how this method is usable across different languages.