 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Beyond the Obvious: A Survey on Abstract Concept Recognition for Video Understanding
Aug 28, 2025The automatic understanding of video content is advancing rapidly. Empowered by deeper neural networks and large datasets, machines are increasingly capable of understanding what is concretely visible in video frames, whether it be objects, actions, events, or scenes. In comparison, humans retain a unique ability to also look beyond concrete entities and recognize abstract concepts like justice, freedom, and togetherness. Abstract concept recognition forms a crucial open challenge in video understanding, where reasoning on multiple semantic levels based on contextual information is key. In this paper, we argue that the recent advances in foundation models make for an ideal setting to address abstract concept understanding in videos. Automated understanding of high-level abstract concepts is imperative as it enables models to be more aligned with human reasoning and values. In this survey, we study different tasks and datasets used to understand abstract concepts in video content. We observe that, periodically and over a long period, researchers have attempted to solve these tasks, making the best use of the tools available at their disposal. We advocate that drawing on decades of community experience will help us shed light on this important open grand challenge and avoid ``re-inventing the wheel'' as we start revisiting it in the era of multi-modal foundation models.
ArtRAG: Retrieval-Augmented Generation with Structured Context for Visual Art Understanding
May 09, 2025Understanding visual art requires reasoning across multiple perspectives -- cultural, historical, and stylistic -- beyond mere object recognition. While recent multimodal large language models (MLLMs) perform well on general image captioning, they often fail to capture the nuanced interpretations that fine art demands. We propose ArtRAG, a novel, training-free framework that combines structured knowledge with retrieval-augmented generation (RAG) for multi-perspective artwork explanation. ArtRAG automatically constructs an Art Context Knowledge Graph (ACKG) from domain-specific textual sources, organizing entities such as artists, movements, themes, and historical events into a rich, interpretable graph. At inference time, a multi-granular structured retriever selects semantically and topologically relevant subgraphs to guide generation. This enables MLLMs to produce contextually grounded, culturally informed art descriptions. Experiments on the SemArt and Artpedia datasets show that ArtRAG outperforms several heavily trained baselines. Human evaluations further confirm that ArtRAG generates coherent, insightful, and culturally enriched interpretations.
The CASTLE 2024 Dataset: Advancing the Art of Multimodal Understanding
Mar 21, 2025Egocentric video has seen increased interest in recent years, as it is used in a range of areas. However, most existing datasets are limited to a single perspective. In this paper, we present the CASTLE 2024 dataset, a multimodal collection containing ego- and exo-centric (i.e., first- and third-person perspective) video and audio from 15 time-aligned sources, as well as other sensor streams and auxiliary data. The dataset was recorded by volunteer participants over four days in a fixed location and includes the point of view of 10 participants, with an additional 5 fixed cameras providing an exocentric perspective. The entire dataset contains over 600 hours of UHD video recorded at 50 frames per second. In contrast to other datasets, CASTLE 2024 does not contain any partial censoring, such as blurred faces or distorted audio. The dataset is available via https://castle-dataset.github.io/.
Gradient Weight-normalized Low-rank Projection for Efficient LLM Training
Dec 27, 2024Large Language Models (LLMs) have shown remarkable performance across various tasks, but the escalating demands on computational resources pose significant challenges, particularly in the extensive utilization of full fine-tuning for downstream tasks. To address this, parameter-efficient fine-tuning (PEFT) methods have been developed, but they often underperform compared to full fine-tuning and struggle with memory efficiency. In this work, we introduce Gradient Weight-Normalized Low-Rank Projection (GradNormLoRP), a novel approach that enhances both parameter and memory efficiency while maintaining comparable performance to full fine-tuning. GradNormLoRP normalizes the weight matrix to improve gradient conditioning, facilitating better convergence during optimization. Additionally, it applies low-rank approximations to the weight and gradient matrices, significantly reducing memory usage during training. Extensive experiments demonstrate that our 8-bit GradNormLoRP reduces optimizer memory usage by up to 89.5% and enables the pre-training of large LLMs, such as LLaMA 7B, on consumer-level GPUs like the NVIDIA RTX 4090, without additional inference costs. Moreover, GradNormLoRP outperforms existing low-rank methods in fine-tuning tasks. For instance, when fine-tuning the RoBERTa model on all GLUE tasks with a rank of 8, GradNormLoRP achieves an average score of 80.65, surpassing LoRA's score of 79.23. These results underscore GradNormLoRP as a promising alternative for efficient LLM pre-training and fine-tuning. Source code and Appendix: https://github.com/Jhhuangkay/Gradient-Weight-normalized-Low-rank-Projection-for-Efficient-LLM-Training
Non-Progressive Influence Maximization in Dynamic Social Networks
Dec 10, 2024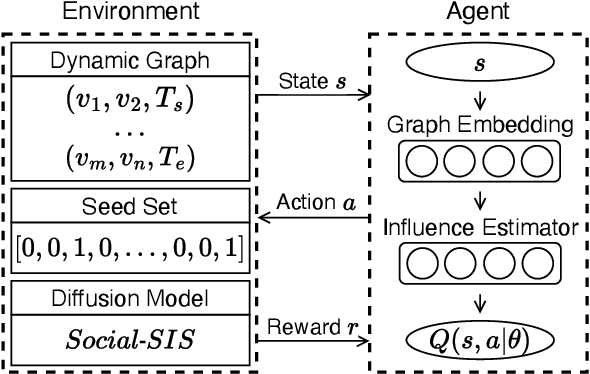



The influence maximization (IM) problem involves identifying a set of key individuals in a social network who can maximize the spread of influence through their network connections. With the advent of geometric deep learning on graphs, great progress has been made towards better solutions for the IM problem. In this paper, we focus on the dynamic non-progressive IM problem, which considers the dynamic nature of real-world social networks and the special case where the influence diffusion is non-progressive, i.e., nodes can be activated multiple times. We first extend an existing diffusion model to capture the non-progressive influence propagation in dynamic social networks. We then propose the method, DNIMRL, which employs deep reinforcement learning and dynamic graph embedding to solve the dynamic non-progressive IM problem. In particular, we propose a novel algorithm that effectively leverages graph embedding to capture the temporal changes of dynamic networks and seamlessly integrates with deep reinforcement learning. The experiments, on different types of real-world social network datasets, demonstrate that our method outperforms state-of-the-art baselines.
Image2Text2Image: A Novel Framework for Label-Free Evaluation of Image-to-Text Generation with Text-to-Image Diffusion Models
Nov 08, 2024



Evaluating the quality of automatically generated image descriptions is a complex task that requires metrics capturing various dimensions, such as grammaticality, coverage, accuracy, and truthfulness. Although human evaluation provides valuable insights, its cost and time-consuming nature pose limitations. Existing automated metrics like BLEU, ROUGE, METEOR, and CIDEr attempt to fill this gap, but they often exhibit weak correlations with human judgment. To address this challenge, we propose a novel evaluation framework called Image2Text2Image, which leverages diffusion models, such as Stable Diffusion or DALL-E, for text-to-image generation. In the Image2Text2Image framework, an input image is first processed by a selected image captioning model, chosen for evaluation, to generate a textual description. Using this generated description, a diffusion model then creates a new image. By comparing features extracted from the original and generated images, we measure their similarity using a designated similarity metric. A high similarity score suggests that the model has produced a faithful textual description, while a low score highlights discrepancies, revealing potential weaknesses in the model's performance. Notably, our framework does not rely on human-annotated reference captions, making it a valuable tool for assessing image captioning models. Extensive experiments and human evaluations validate the efficacy of our proposed Image2Text2Image evaluation framework. The code and dataset will be published to support further research in the community.
Set2Seq Transformer: Learning Permutation Aware Set Representations of Artistic Sequences
Aug 06, 2024
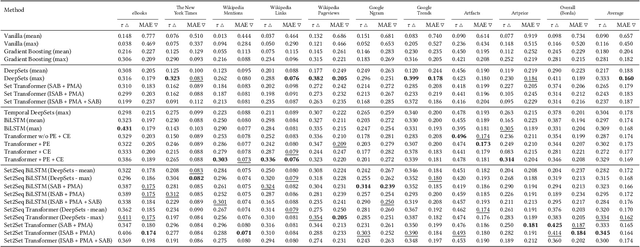
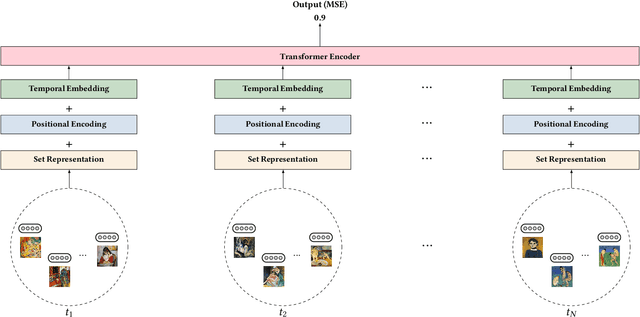
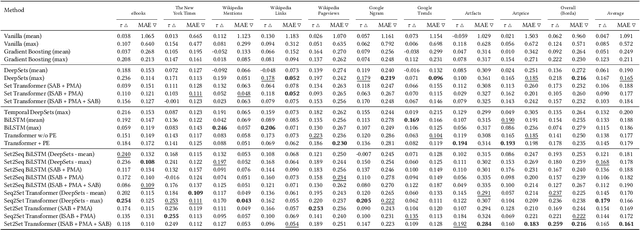
We propose Set2Seq Transformer, a novel sequential multiple instance architecture, that learns to rank permutation aware set representations of sequences. First, we illustrate that learning temporal position-aware representations of discrete timesteps can greatly improve static visual multiple instance learning methods that do not regard temporality and concentrate almost exclusively on visual content analysis. We further demonstrate the significant advantages of end-to-end sequential multiple instance learning, integrating visual content and temporal information in a multimodal manner. As application we focus on fine art analysis related tasks. To that end, we show that our Set2Seq Transformer can leverage visual set and temporal position-aware representations for modelling visual artists' oeuvres for predicting artistic success. Finally, through extensive quantitative and qualitative evaluation using a novel dataset, WikiArt-Seq2Rank, and a visual learning-to-rank downstream task, we show that our Set2Seq Transformer captures essential temporal information improving the performance of strong static and sequential multiple instance learning methods for predicting artistic success.
A Novel Evaluation Framework for Image2Text Generation
Aug 03, 2024Evaluating the quality of automatically generated image descriptions is challenging, requiring metrics that capture various aspects such as grammaticality, coverage, correctness, and truthfulness. While human evaluation offers valuable insights, its cost and time-consuming nature pose limitations. Existing automated metrics like BLEU, ROUGE, METEOR, and CIDEr aim to bridge this gap but often show weak correlations with human judgment. We address this challenge by introducing a novel evaluation framework rooted in a modern large language model (LLM), such as GPT-4 or Gemini, capable of image generation. In our proposed framework, we begin by feeding an input image into a designated image captioning model, chosen for evaluation, to generate a textual description. Using this description, an LLM then creates a new image. By extracting features from both the original and LLM-created images, we measure their similarity using a designated similarity metric. A high similarity score suggests that the image captioning model has accurately generated textual descriptions, while a low similarity score indicates discrepancies, revealing potential shortcomings in the model's performance. Human-annotated reference captions are not required in our proposed evaluation framework, which serves as a valuable tool for evaluating the effectiveness of image captioning models. Its efficacy is confirmed through human evaluation.
Ada-HGNN: Adaptive Sampling for Scalable Hypergraph Neural Networks
May 22, 2024Hypergraphs serve as an effective model for depicting complex connections in various real-world scenarios, from social to biological networks. The development of Hypergraph Neural Networks (HGNNs) has emerged as a valuable method to manage the intricate associations in data, though scalability is a notable challenge due to memory limitations. In this study, we introduce a new adaptive sampling strategy specifically designed for hypergraphs, which tackles their unique complexities in an efficient manner. We also present a Random Hyperedge Augmentation (RHA) technique and an additional Multilayer Perceptron (MLP) module to improve the robustness and generalization capabilities of our approach. Thorough experiments with real-world datasets have proven the effectiveness of our method, markedly reducing computational and memory demands while maintaining performance levels akin to conventional HGNNs and other baseline models. This research paves the way for improving both the scalability and efficacy of HGNNs in extensive applications. We will also make our codebase publicly accessible.
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Apr 29, 2024



Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10\% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.