 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Brittleness of CLIP Text Encoders
Nov 07, 2025
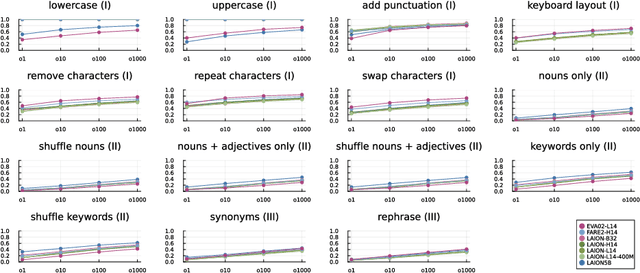


Multimodal co-embedding models, especially CLIP, have advanced the state of the art in zero-shot classification and multimedia information retrieval in recent years by aligning images and text in a shared representation space. However, such modals trained on a contrastive alignment can lack stability towards small input perturbations. Especially when dealing with manually expressed queries, minor variations in the query can cause large differences in the ranking of the best-matching results. In this paper, we present a systematic analysis of the effect of multiple classes of non-semantic query perturbations in an multimedia information retrieval scenario. We evaluate a diverse set of lexical, syntactic, and semantic perturbations across multiple CLIP variants using the TRECVID Ad-Hoc Video Search queries and the V3C1 video collection. Across models, we find that syntactic and semantic perturbations drive the largest instabilities, while brittleness is concentrated in trivial surface edits such as punctuation and case. Our results highlight robustness as a critical dimension for evaluating vision-language models beyond benchmark accuracy.
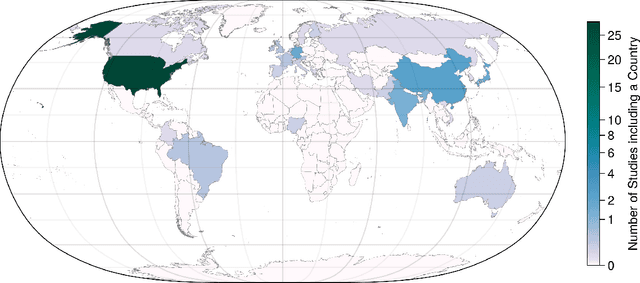
The State-of-the-Art in Lifelog Retrieval: A Review of Progress at the ACM Lifelog Search Challenge Workshop 2022-24
Jun 07, 2025The ACM Lifelog Search Challenge (LSC) is a venue that welcomes and compares systems that support the exploration of lifelog data, and in particular the retrieval of specific information, through an interactive competition format. This paper reviews the recent advances in interactive lifelog retrieval as demonstrated at the ACM LSC from 2022 to 2024. Through a detailed comparative analysis, we highlight key improvements across three main retrieval tasks: known-item search, question answering, and ad-hoc search. Our analysis identifies trends such as the widespread adoption of embedding-based retrieval methods (e.g., CLIP, BLIP), increased integration of large language models (LLMs) for conversational retrieval, and continued innovation in multimodal and collaborative search interfaces. We further discuss how specific retrieval techniques and user interface (UI) designs have impacted system performance, emphasizing the importance of balancing retrieval complexity with usability. Our findings indicate that embedding-driven approaches combined with LLMs show promise for lifelog retrieval systems. Likewise, improving UI design can enhance usability and efficiency. Additionally, we recommend reconsidering multi-instance system evaluations within the expert track to better manage variability in user familiarity and configuration effectiveness.
Deep Generative Model-Based Generation of Synthetic Individual-Specific Brain MRI Segmentations
Apr 15, 2025


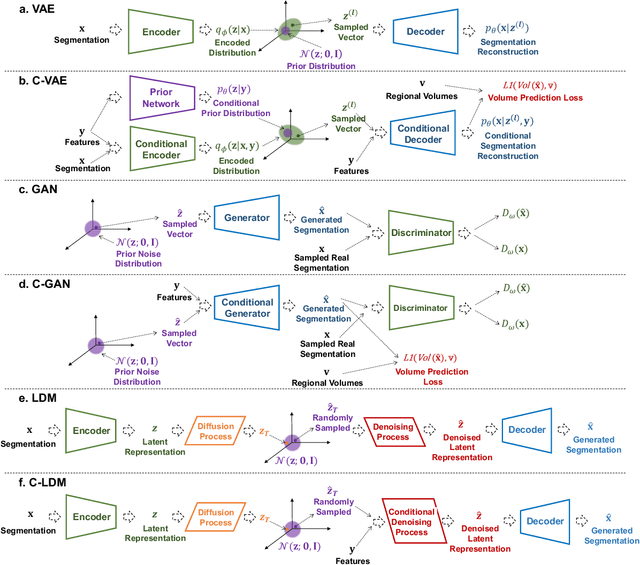
To the best of our knowledge, all existing methods that can generate synthetic brain magnetic resonance imaging (MRI) scans for a specific individual require detailed structural or volumetric information about the individual's brain. However, such brain information is often scarce, expensive, and difficult to obtain. In this paper, we propose the first approach capable of generating synthetic brain MRI segmentations -- specifically, 3D white matter (WM), gray matter (GM), and cerebrospinal fluid (CSF) segmentations -- for individuals using their easily obtainable and often readily available demographic, interview, and cognitive test information. Our approach features a novel deep generative model, CSegSynth, which outperforms existing prominent generative models, including conditional variational autoencoder (C-VAE), conditional generative adversarial network (C-GAN), and conditional latent diffusion model (C-LDM). We demonstrate the high quality of our synthetic segmentations through extensive evaluations. Also, in assessing the effectiveness of the individual-specific generation, we achieve superior volume prediction, with Pearson correlation coefficients reaching 0.80, 0.82, and 0.70 between the ground-truth WM, GM, and CSF volumes of test individuals and those volumes predicted based on generated individual-specific segmentations, respectively.
ConceptFormer: Towards Efficient Use of Knowledge-Graph Embeddings in Large Language Models
Apr 10, 2025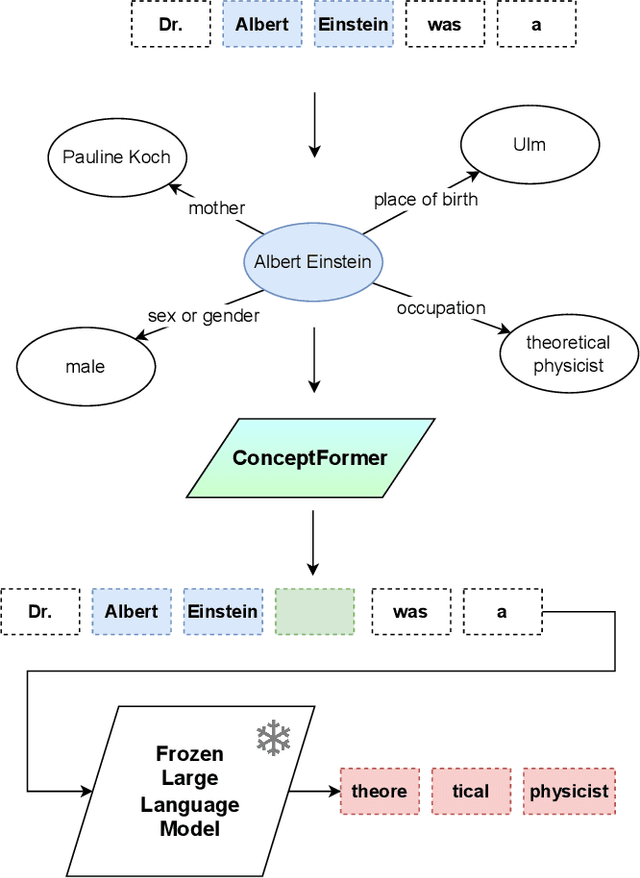
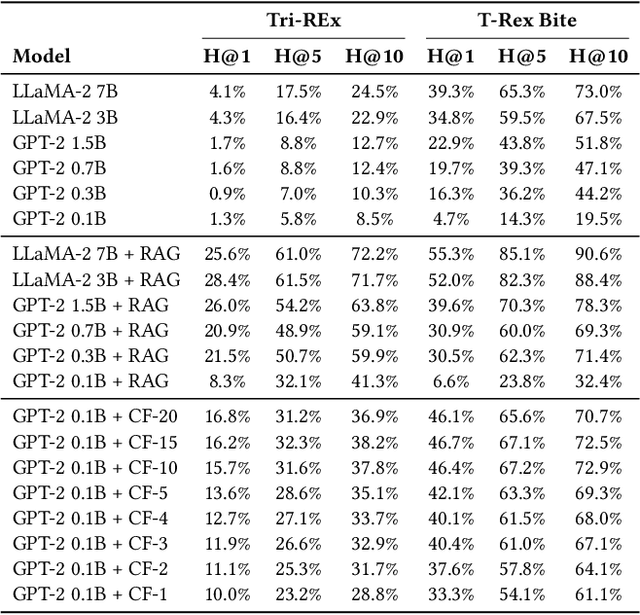
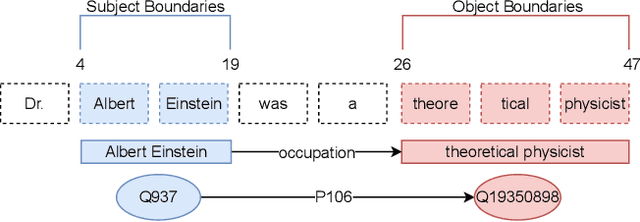
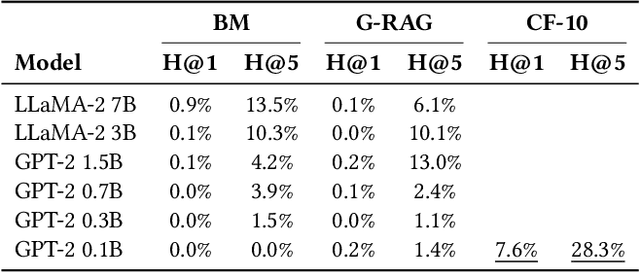
Retrieval Augmented Generation (RAG) has enjoyed increased attention in the recent past and recent advancements in Large Language Models (LLMs) have highlighted the importance of integrating world knowledge into these systems. Current RAG methodologies often modify the internal architecture of pre-trained language models (PLMs) or rely on textifying knowledge graphs (KGs), which is inefficient in terms of token usage. This paper introduces ConceptFormer, a new approach to augment LLMs with structured knowledge from KGs, such as Wikidata, without altering their internal structure or relying on textual input of KGs. ConceptFormer operates in the LLM embedding vector space, creating and injecting \emph{concept vectors} that encapsulate the information of the KG nodes directly. Trained in conjunction with a frozen LLM, ConceptFormer generates a comprehensive lookup table that maps KG nodes to their respective concept vectors. The approach aims to enhance the factual recall capabilities of LLMs by enabling them to process these concept vectors natively, thus enriching them with structured world knowledge in an efficient and scalable manner. Our experiments demonstrate that the addition of concept vectors to GPT-2 0.1B substantially increases its factual recall ability (Hit@10) by up to 272\% when tested on sentences from Wikipedia and up to 348\% on synthetically generated sentences. Even injecting only a single concept vector into the prompt increases factual recall ability (Hit@10) by up to 213\% on Wikipedia sentences, significantly outperforming RAG with graph textification while consuming 130x fewer input tokens.
The CASTLE 2024 Dataset: Advancing the Art of Multimodal Understanding
Mar 21, 2025Egocentric video has seen increased interest in recent years, as it is used in a range of areas. However, most existing datasets are limited to a single perspective. In this paper, we present the CASTLE 2024 dataset, a multimodal collection containing ego- and exo-centric (i.e., first- and third-person perspective) video and audio from 15 time-aligned sources, as well as other sensor streams and auxiliary data. The dataset was recorded by volunteer participants over four days in a fixed location and includes the point of view of 10 participants, with an additional 5 fixed cameras providing an exocentric perspective. The entire dataset contains over 600 hours of UHD video recorded at 50 frames per second. In contrast to other datasets, CASTLE 2024 does not contain any partial censoring, such as blurred faces or distorted audio. The dataset is available via https://castle-dataset.github.io/.
Whom do Explanations Serve? A Systematic Literature Survey of User Characteristics in Explainable Recommender Systems Evaluation
Dec 12, 2024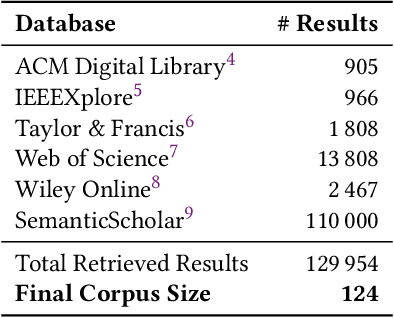
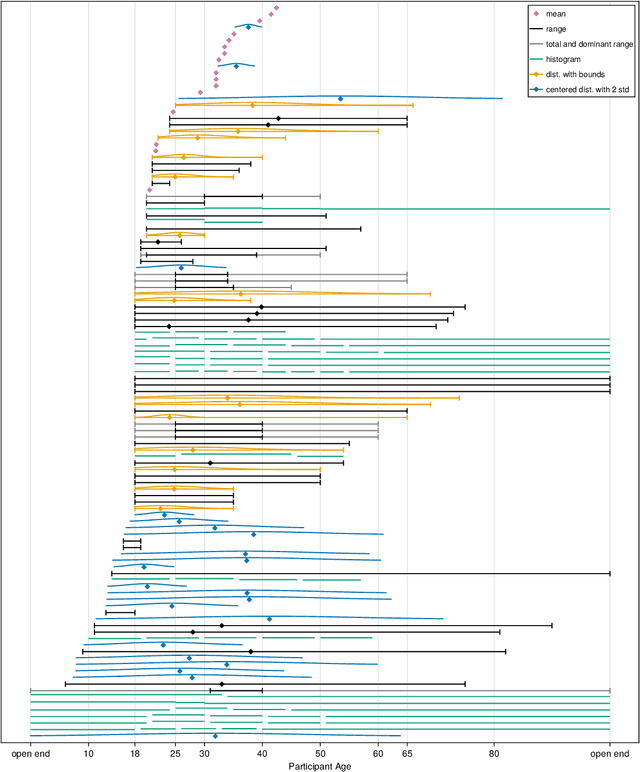

Adding explanations to recommender systems is said to have multiple benefits, such as increasing user trust or system transparency. Previous work from other application areas suggests that specific user characteristics impact the users' perception of the explanation. However, we rarely find this type of evaluation for recommender systems explanations. This paper addresses this gap by surveying 124 papers in which recommender systems explanations were evaluated in user studies. We analyzed their participant descriptions and study results where the impact of user characteristics on the explanation effects was measured. Our findings suggest that the results from the surveyed studies predominantly cover specific users who do not necessarily represent the users of recommender systems in the evaluation domain. This may seriously hamper the generalizability of any insights we may gain from current studies on explanations in recommender systems. We further find inconsistencies in the data reporting, which impacts the reproducibility of the reported results. Hence, we recommend actions to move toward a more inclusive and reproducible evaluation.
Performance Evaluation in Multimedia Retrieval
Oct 09, 2024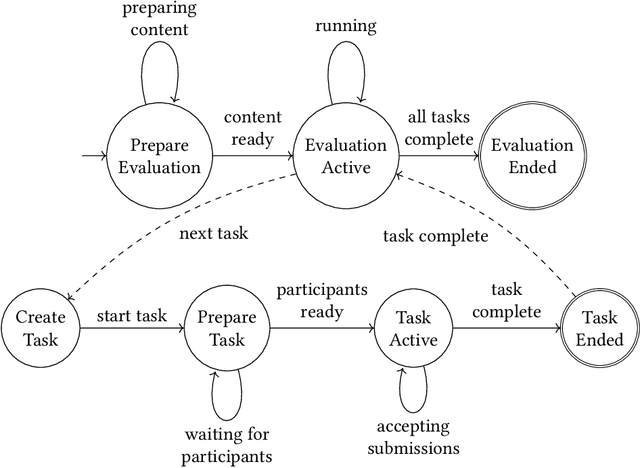
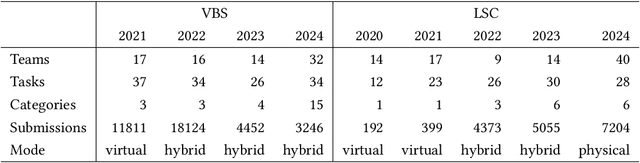
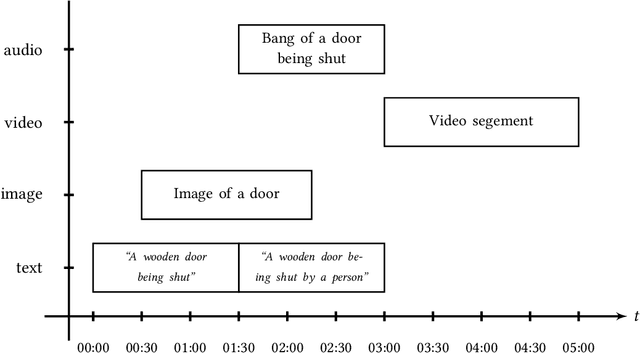
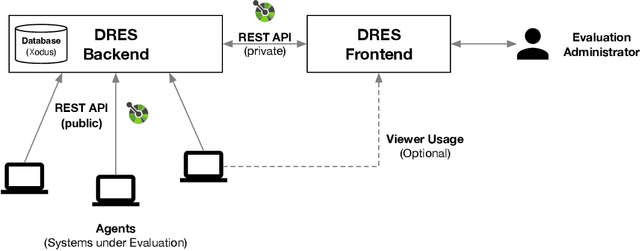
Performance evaluation in multimedia retrieval, as in the information retrieval domain at large, relies heavily on retrieval experiments, employing a broad range of techniques and metrics. These can involve human-in-the-loop and machine-only settings for the retrieval process itself and the subsequent verification of results. Such experiments can be elaborate and use-case-specific, which can make them difficult to compare or replicate. In this paper, we present a formal model to express all relevant aspects of such retrieval experiments, as well as a flexible open-source evaluation infrastructure that implements the model. These contributions intend to make a step towards lowering the hurdles for conducting retrieval experiments and improving their reproducibility.
NLQxform-UI: A Natural Language Interface for Querying DBLP Interactively
Mar 13, 2024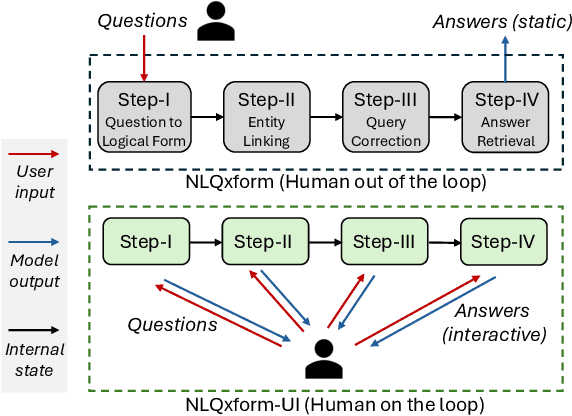
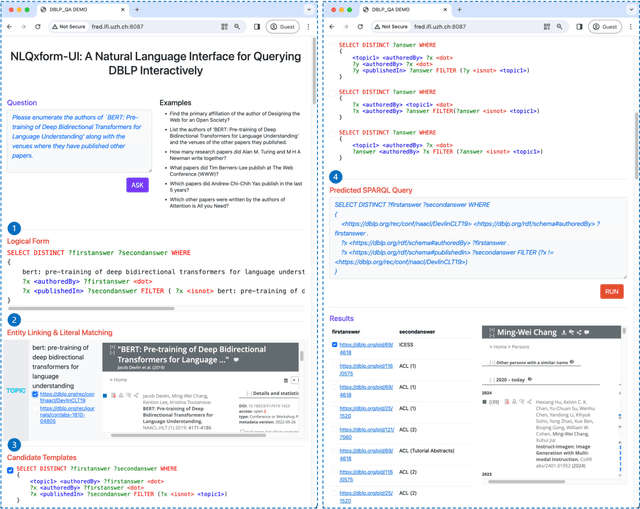
In recent years, the DBLP computer science bibliography has been prominently used for searching scholarly information, such as publications, scholars, and venues. However, its current search service lacks the capability to handle complex queries, which limits the usability of DBLP. In this paper, we present NLQxform-UI, a web-based natural language interface that enables users to query DBLP directly with complex natural language questions. NLQxform-UI automatically translates given questions into SPARQL queries and executes the queries over the DBLP knowledge graph to retrieve answers. The querying process is presented to users in an interactive manner, which improves the transparency of the system and helps examine the returned answers. Also, intermediate results in the querying process can be previewed and manually altered to improve the accuracy of the system. NLQxform-UI has been completely open-sourced: https://github.com/ruijie-wang-uzh/NLQxform-UI.
GNN2R: Weakly-Supervised Rationale-Providing Question Answering over Knowledge Graphs
Dec 04, 2023



Most current methods for multi-hop question answering (QA) over knowledge graphs (KGs) only provide final conclusive answers without explanations, such as a set of KG entities that is difficult for normal users to review and comprehend. This issue severely limits the application of KG-based QA in real-world scenarios. However, it is non-trivial to solve due to two challenges: First, annotations of reasoning chains of multi-hop questions, which could serve as supervision for explanation generation, are usually lacking. Second, it is difficult to maintain high efficiency when explicit KG triples need to be retrieved to generate explanations. In this paper, we propose a novel Graph Neural Network-based Two-Step Reasoning model (GNN2R) to solve this issue. GNN2R can provide both final answers and reasoning subgraphs as a rationale behind final answers efficiently with only weak supervision that is available through question-final answer pairs. We extensively evaluated GNN2R with detailed analyses in experiments. The results demonstrate that, in terms of effectiveness, efficiency, and quality of generated explanations, GNN2R outperforms existing state-of-the-art methods that are applicable to this task. Our code and pre-trained models are available at https://github.com/ruijie-wang-uzh/GNN2R.
NLQxform: A Language Model-based Question to SPARQL Transformer
Nov 08, 2023

In recent years, scholarly data has grown dramatically in terms of both scale and complexity. It becomes increasingly challenging to retrieve information from scholarly knowledge graphs that include large-scale heterogeneous relationships, such as authorship, affiliation, and citation, between various types of entities, e.g., scholars, papers, and organizations. As part of the Scholarly QALD Challenge, this paper presents a question-answering (QA) system called NLQxform, which provides an easy-to-use natural language interface to facilitate accessing scholarly knowledge graphs. NLQxform allows users to express their complex query intentions in natural language questions. A transformer-based language model, i.e., BART, is employed to translate questions into standard SPARQL queries, which can be evaluated to retrieve the required information. According to the public leaderboard of the Scholarly QALD Challenge at ISWC 2023 (Task 1: DBLP-QUAD - Knowledge Graph Question Answering over DBLP), NLQxform achieved an F1 score of 0.85 and ranked first on the QA task, demonstrating the competitiveness of the system.