 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARPA: A Testability-Driven, Literature-Grounded Framework for Research Ideation
Oct 01, 2025While there has been a surge of interest in automated scientific discovery (ASD), especially with the emergence of LLMs, it remains challenging for tools to generate hypotheses that are both testable and grounded in the scientific literature. Additionally, existing ideation tools are not adaptive to prior experimental outcomes. We developed HARPA to address these challenges by incorporating the ideation workflow inspired by human researchers. HARPA first identifies emerging research trends through literature mining, then explores hypothesis design spaces, and finally converges on precise, testable hypotheses by pinpointing research gaps and justifying design choices. Our evaluations show that HARPA-generated hypothesis-driven research proposals perform comparably to a strong baseline AI-researcher across most qualitative dimensions (e.g., specificity, novelty, overall quality), but achieve significant gains in feasibility(+0.78, p$<0.05$, bootstrap) and groundedness (+0.85, p$<0.01$, bootstrap) on a 10-point Likert scale. When tested with the ASD agent (CodeScientist), HARPA produced more successful executions (20 vs. 11 out of 40) and fewer failures (16 vs. 21 out of 40), showing that expert feasibility judgments track with actual execution success. Furthermore, to simulate how researchers continuously refine their understanding of what hypotheses are both testable and potentially interesting from experience, HARPA learns a reward model that scores new hypotheses based on prior experimental outcomes, achieving approx. a 28\% absolute gain over HARPA's untrained baseline scorer. Together, these methods represent a step forward in the field of AI-driven scientific discovery.
HypER: Literature-grounded Hypothesis Generation and Distillation with Provenance
Jun 15, 2025



Large Language models have demonstrated promising performance in research ideation across scientific domains. Hypothesis development, the process of generating a highly specific declarative statement connecting a research idea with empirical validation, has received relatively less attention. Existing approaches trivially deploy retrieval augmentation and focus only on the quality of the final output ignoring the underlying reasoning process behind ideation. We present $\texttt{HypER}$ ($\textbf{Hyp}$othesis Generation with $\textbf{E}$xplanation and $\textbf{R}$easoning), a small language model (SLM) trained for literature-guided reasoning and evidence-based hypothesis generation. $\texttt{HypER}$ is trained in a multi-task setting to discriminate between valid and invalid scientific reasoning chains in presence of controlled distractions. We find that $\texttt{HypER}$ outperformes the base model, distinguishing valid from invalid reasoning chains (+22\% average absolute F1), generates better evidence-grounded hypotheses (0.327 vs. 0.305 base model) with high feasibility and impact as judged by human experts ($>$3.5 on 5-point Likert scale).
Deep Generative Model-Based Generation of Synthetic Individual-Specific Brain MRI Segmentations
Apr 15, 2025


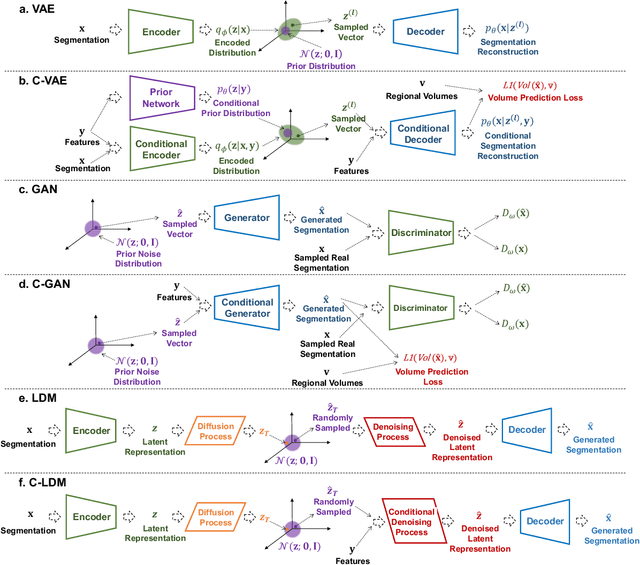
To the best of our knowledge, all existing methods that can generate synthetic brain magnetic resonance imaging (MRI) scans for a specific individual require detailed structural or volumetric information about the individual's brain. However, such brain information is often scarce, expensive, and difficult to obtain. In this paper, we propose the first approach capable of generating synthetic brain MRI segmentations -- specifically, 3D white matter (WM), gray matter (GM), and cerebrospinal fluid (CSF) segmentations -- for individuals using their easily obtainable and often readily available demographic, interview, and cognitive test information. Our approach features a novel deep generative model, CSegSynth, which outperforms existing prominent generative models, including conditional variational autoencoder (C-VAE), conditional generative adversarial network (C-GAN), and conditional latent diffusion model (C-LDM). We demonstrate the high quality of our synthetic segmentations through extensive evaluations. Also, in assessing the effectiveness of the individual-specific generation, we achieve superior volume prediction, with Pearson correlation coefficients reaching 0.80, 0.82, and 0.70 between the ground-truth WM, GM, and CSF volumes of test individuals and those volumes predicted based on generated individual-specific segmentations, respectively.
ConceptFormer: Towards Efficient Use of Knowledge-Graph Embeddings in Large Language Models
Apr 10, 2025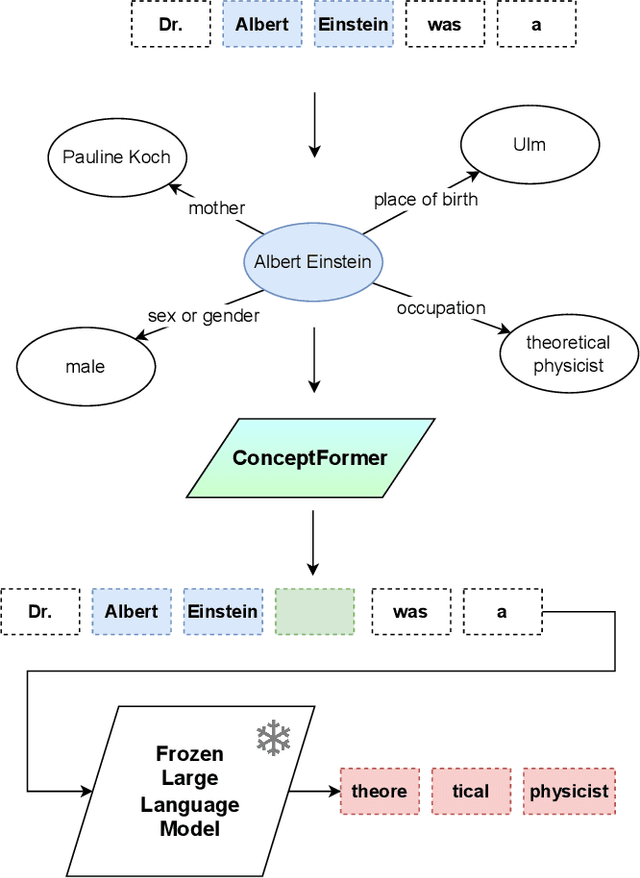
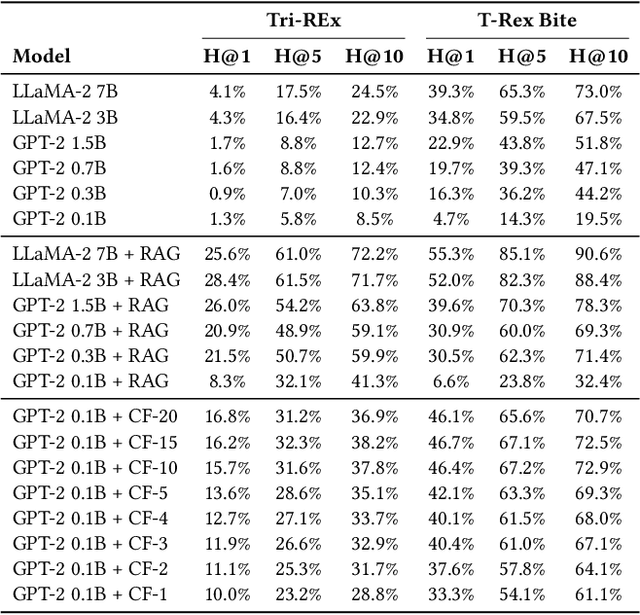
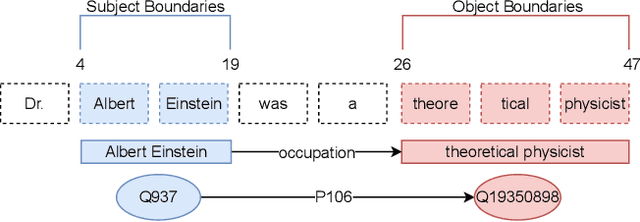
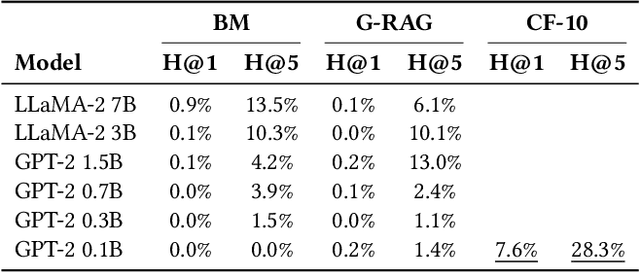
Retrieval Augmented Generation (RAG) has enjoyed increased attention in the recent past and recent advancements in Large Language Models (LLMs) have highlighted the importance of integrating world knowledge into these systems. Current RAG methodologies often modify the internal architecture of pre-trained language models (PLMs) or rely on textifying knowledge graphs (KGs), which is inefficient in terms of token usage. This paper introduces ConceptFormer, a new approach to augment LLMs with structured knowledge from KGs, such as Wikidata, without altering their internal structure or relying on textual input of KGs. ConceptFormer operates in the LLM embedding vector space, creating and injecting \emph{concept vectors} that encapsulate the information of the KG nodes directly. Trained in conjunction with a frozen LLM, ConceptFormer generates a comprehensive lookup table that maps KG nodes to their respective concept vectors. The approach aims to enhance the factual recall capabilities of LLMs by enabling them to process these concept vectors natively, thus enriching them with structured world knowledge in an efficient and scalable manner. Our experiments demonstrate that the addition of concept vectors to GPT-2 0.1B substantially increases its factual recall ability (Hit@10) by up to 272\% when tested on sentences from Wikipedia and up to 348\% on synthetically generated sentences. Even injecting only a single concept vector into the prompt increases factual recall ability (Hit@10) by up to 213\% on Wikipedia sentences, significantly outperforming RAG with graph textification while consuming 130x fewer input tokens.
Adaptive political surveys and GPT-4: Tackling the cold start problem with simulated user interactions
Mar 12, 2025

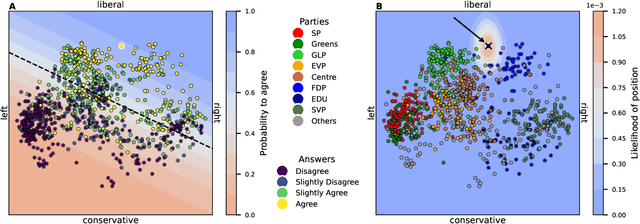

Adaptive questionnaires dynamically select the next question for a survey participant based on their previous answers. Due to digitalisation, they have become a viable alternative to traditional surveys in application areas such as political science. One limitation, however, is their dependency on data to train the model for question selection. Often, such training data (i.e., user interactions) are unavailable a priori. To address this problem, we (i) test whether Large Language Models (LLM) can accurately generate such interaction data and (ii) explore if these synthetic data can be used to pre-train the statistical model of an adaptive political survey. To evaluate this approach, we utilise existing data from the Swiss Voting Advice Application (VAA) Smartvote in two ways: First, we compare the distribution of LLM-generated synthetic data to the real distribution to assess its similarity. Second, we compare the performance of an adaptive questionnaire that is randomly initialised with one pre-trained on synthetic data to assess their suitability for training. We benchmark these results against an "oracle" questionnaire with perfect prior knowledge. We find that an off-the-shelf LLM (GPT-4) accurately generates answers to the Smartvote questionnaire from the perspective of different Swiss parties. Furthermore, we demonstrate that initialising the statistical model with synthetic data can (i) significantly reduce the error in predicting user responses and (ii) increase the candidate recommendation accuracy of the VAA. Our work emphasises the considerable potential of LLMs to create training data to improve the data collection process in adaptive questionnaires in LLM-affine areas such as political surveys.
Whom do Explanations Serve? A Systematic Literature Survey of User Characteristics in Explainable Recommender Systems Evaluation
Dec 12, 2024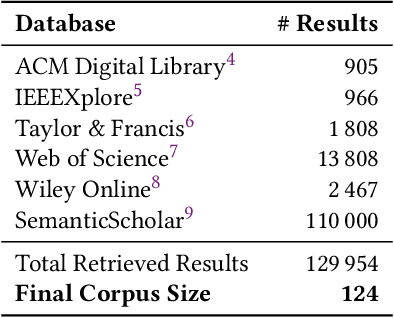
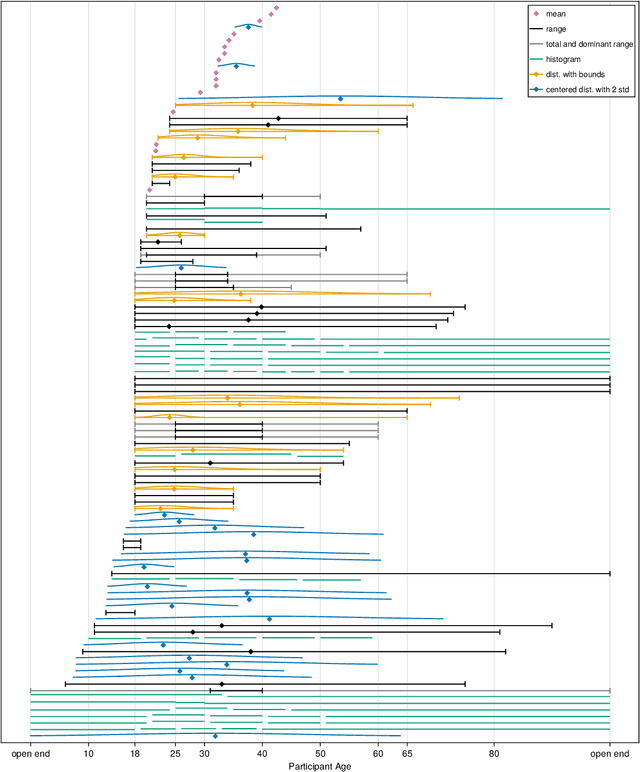

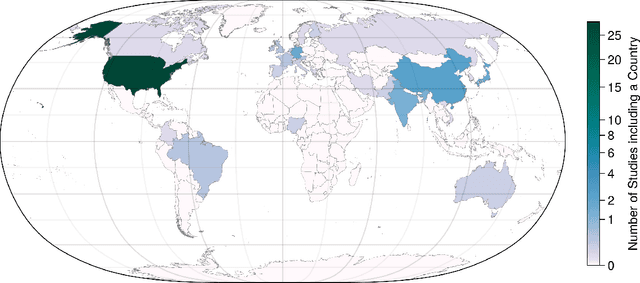
Adding explanations to recommender systems is said to have multiple benefits, such as increasing user trust or system transparency. Previous work from other application areas suggests that specific user characteristics impact the users' perception of the explanation. However, we rarely find this type of evaluation for recommender systems explanations. This paper addresses this gap by surveying 124 papers in which recommender systems explanations were evaluated in user studies. We analyzed their participant descriptions and study results where the impact of user characteristics on the explanation effects was measured. Our findings suggest that the results from the surveyed studies predominantly cover specific users who do not necessarily represent the users of recommender systems in the evaluation domain. This may seriously hamper the generalizability of any insights we may gain from current studies on explanations in recommender systems. We further find inconsistencies in the data reporting, which impacts the reproducibility of the reported results. Hence, we recommend actions to move toward a more inclusive and reproducible evaluation.
Performance Evaluation in Multimedia Retrieval
Oct 09, 2024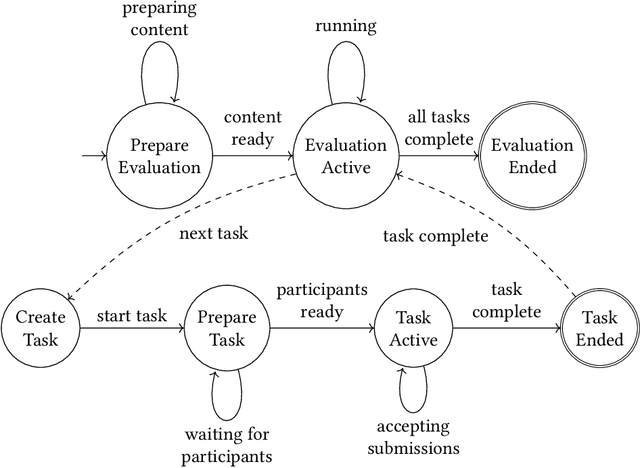
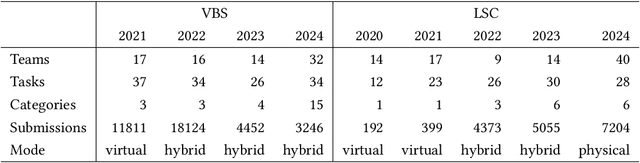
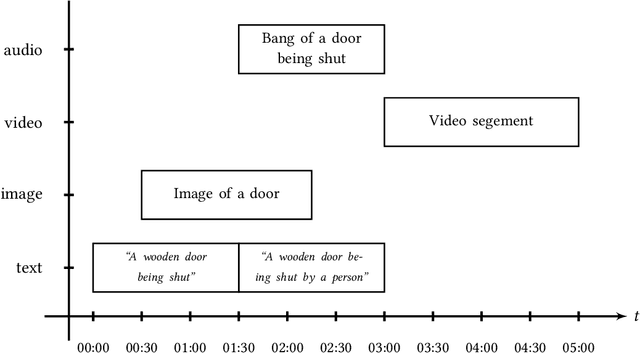
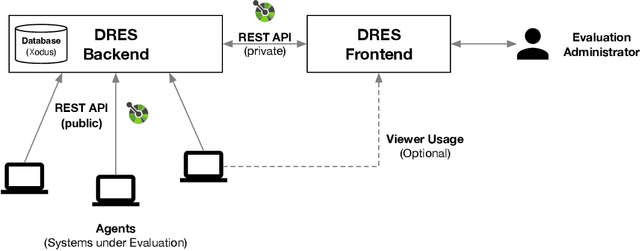
Performance evaluation in multimedia retrieval, as in the information retrieval domain at large, relies heavily on retrieval experiments, employing a broad range of techniques and metrics. These can involve human-in-the-loop and machine-only settings for the retrieval process itself and the subsequent verification of results. Such experiments can be elaborate and use-case-specific, which can make them difficult to compare or replicate. In this paper, we present a formal model to express all relevant aspects of such retrieval experiments, as well as a flexible open-source evaluation infrastructure that implements the model. These contributions intend to make a step towards lowering the hurdles for conducting retrieval experiments and improving their reproducibility.
Fast and Adaptive Questionnaires for Voting Advice Applications
Apr 02, 2024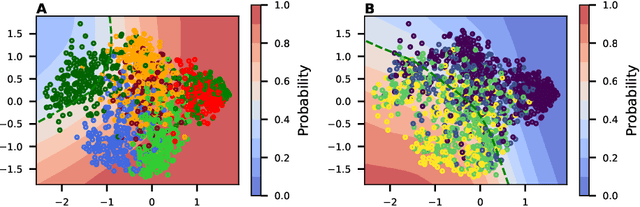
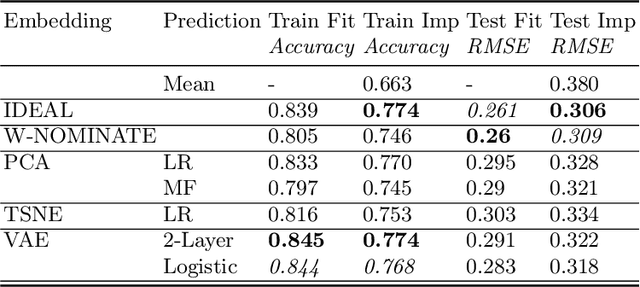
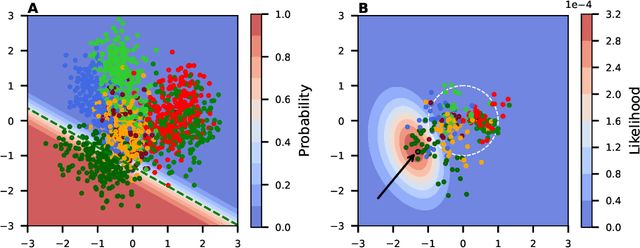
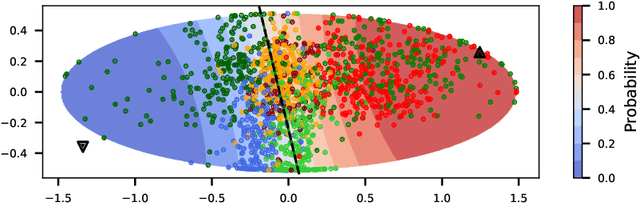
The effectiveness of Voting Advice Applications (VAA) is often compromised by the length of their questionnaires. To address user fatigue and incomplete responses, some applications (such as the Swiss Smartvote) offer a condensed version of their questionnaire. However, these condensed versions can not ensure the accuracy of recommended parties or candidates, which we show to remain below 40%. To tackle these limitations, this work introduces an adaptive questionnaire approach that selects subsequent questions based on users' previous answers, aiming to enhance recommendation accuracy while reducing the number of questions posed to the voters. Our method uses an encoder and decoder module to predict missing values at any completion stage, leveraging a two-dimensional latent space reflective of political science's traditional methods for visualizing political orientations. Additionally, a selector module is proposed to determine the most informative subsequent question based on the voter's current position in the latent space and the remaining unanswered questions. We validated our approach using the Smartvote dataset from the Swiss Federal elections in 2019, testing various spatial models and selection methods to optimize the system's predictive accuracy. Our findings indicate that employing the IDEAL model both as encoder and decoder, combined with a PosteriorRMSE method for question selection, significantly improves the accuracy of recommendations, achieving 74% accuracy after asking the same number of questions as in the condensed version.
NLQxform-UI: A Natural Language Interface for Querying DBLP Interactively
Mar 13, 2024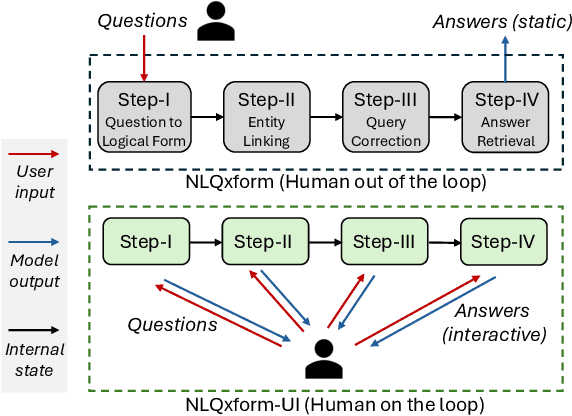
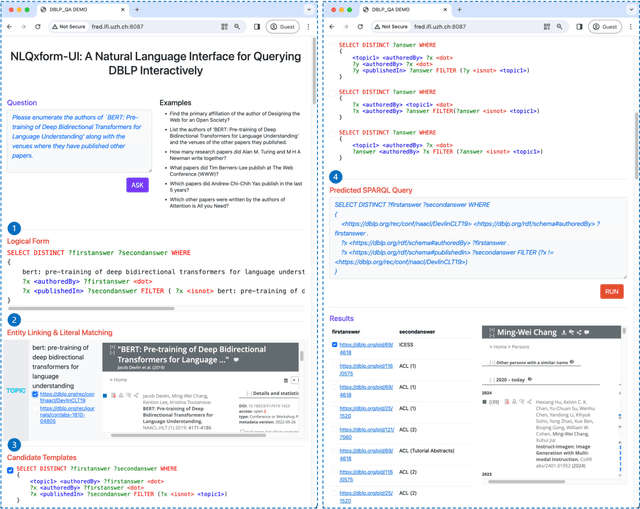
In recent years, the DBLP computer science bibliography has been prominently used for searching scholarly information, such as publications, scholars, and venues. However, its current search service lacks the capability to handle complex queries, which limits the usability of DBLP. In this paper, we present NLQxform-UI, a web-based natural language interface that enables users to query DBLP directly with complex natural language questions. NLQxform-UI automatically translates given questions into SPARQL queries and executes the queries over the DBLP knowledge graph to retrieve answers. The querying process is presented to users in an interactive manner, which improves the transparency of the system and helps examine the returned answers. Also, intermediate results in the querying process can be previewed and manually altered to improve the accuracy of the system. NLQxform-UI has been completely open-sourced: https://github.com/ruijie-wang-uzh/NLQxform-UI.
GNN2R: Weakly-Supervised Rationale-Providing Question Answering over Knowledge Graphs
Dec 04, 2023



Most current methods for multi-hop question answering (QA) over knowledge graphs (KGs) only provide final conclusive answers without explanations, such as a set of KG entities that is difficult for normal users to review and comprehend. This issue severely limits the application of KG-based QA in real-world scenarios. However, it is non-trivial to solve due to two challenges: First, annotations of reasoning chains of multi-hop questions, which could serve as supervision for explanation generation, are usually lacking. Second, it is difficult to maintain high efficiency when explicit KG triples need to be retrieved to generate explanations. In this paper, we propose a novel Graph Neural Network-based Two-Step Reasoning model (GNN2R) to solve this issue. GNN2R can provide both final answers and reasoning subgraphs as a rationale behind final answers efficiently with only weak supervision that is available through question-final answer pairs. We extensively evaluated GNN2R with detailed analyses in experiments. The results demonstrate that, in terms of effectiveness, efficiency, and quality of generated explanations, GNN2R outperforms existing state-of-the-art methods that are applicable to this task. Our code and pre-trained models are available at https://github.com/ruijie-wang-uzh/GNN2R.