 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReIn: Conversational Error Recovery with Reasoning Inception
Feb 19, 2026Conversational agents powered by large language models (LLMs) with tool integration achieve strong performance on fixed task-oriented dialogue datasets but remain vulnerable to unanticipated, user-induced errors. Rather than focusing on error prevention, this work focuses on error recovery, which necessitates the accurate diagnosis of erroneous dialogue contexts and execution of proper recovery plans. Under realistic constraints precluding model fine-tuning or prompt modification due to significant cost and time requirements, we explore whether agents can recover from contextually flawed interactions and how their behavior can be adapted without altering model parameters and prompts. To this end, we propose Reasoning Inception (ReIn), a test-time intervention method that plants an initial reasoning into the agent's decision-making process. Specifically, an external inception module identifies predefined errors within the dialogue context and generates recovery plans, which are subsequently integrated into the agent's internal reasoning process to guide corrective actions, without modifying its parameters or system prompts. We evaluate ReIn by systematically simulating conversational failure scenarios that directly hinder successful completion of user goals: user's ambiguous and unsupported requests. Across diverse combinations of agent models and inception modules, ReIn substantially improves task success and generalizes to unseen error types. Moreover, it consistently outperforms explicit prompt-modification approaches, underscoring its utility as an efficient, on-the-fly method. In-depth analysis of its operational mechanism, particularly in relation to instruction hierarchy, indicates that jointly defining recovery tools with ReIn can serve as a safe and effective strategy for improving the resilience of conversational agents without modifying the backbone models or system prompts.
HypER: Literature-grounded Hypothesis Generation and Distillation with Provenance
Jun 15, 2025



Large Language models have demonstrated promising performance in research ideation across scientific domains. Hypothesis development, the process of generating a highly specific declarative statement connecting a research idea with empirical validation, has received relatively less attention. Existing approaches trivially deploy retrieval augmentation and focus only on the quality of the final output ignoring the underlying reasoning process behind ideation. We present $\texttt{HypER}$ ($\textbf{Hyp}$othesis Generation with $\textbf{E}$xplanation and $\textbf{R}$easoning), a small language model (SLM) trained for literature-guided reasoning and evidence-based hypothesis generation. $\texttt{HypER}$ is trained in a multi-task setting to discriminate between valid and invalid scientific reasoning chains in presence of controlled distractions. We find that $\texttt{HypER}$ outperformes the base model, distinguishing valid from invalid reasoning chains (+22\% average absolute F1), generates better evidence-grounded hypotheses (0.327 vs. 0.305 base model) with high feasibility and impact as judged by human experts ($>$3.5 on 5-point Likert scale).
Med-EASi: Finely Annotated Dataset and Models for Controllable Simplification of Medical Texts
Feb 17, 2023
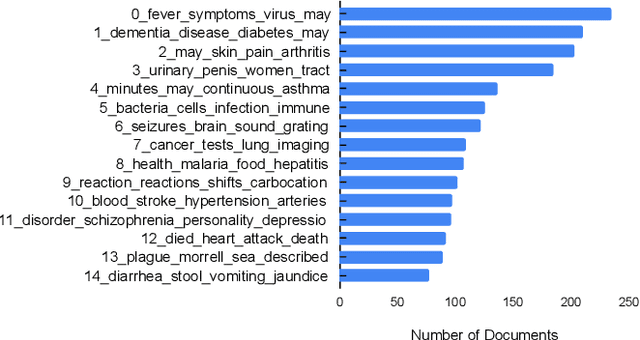

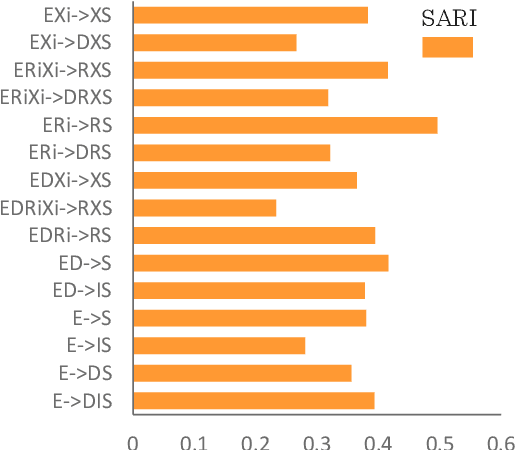
Automatic medical text simplification can assist providers with patient-friendly communication and make medical texts more accessible, thereby improving health literacy. But curating a quality corpus for this task requires the supervision of medical experts. In this work, we present $\textbf{Med-EASi}$ ($\underline{\textbf{Med}}$ical dataset for $\underline{\textbf{E}}$laborative and $\underline{\textbf{A}}$bstractive $\underline{\textbf{Si}}$mplification), a uniquely crowdsourced and finely annotated dataset for supervised simplification of short medical texts. Its $\textit{expert-layman-AI collaborative}$ annotations facilitate $\textit{controllability}$ over text simplification by marking four kinds of textual transformations: elaboration, replacement, deletion, and insertion. To learn medical text simplification, we fine-tune T5-large with four different styles of input-output combinations, leading to two control-free and two controllable versions of the model. We add two types of $\textit{controllability}$ into text simplification, by using a multi-angle training approach: $\textit{position-aware}$, which uses in-place annotated inputs and outputs, and $\textit{position-agnostic}$, where the model only knows the contents to be edited, but not their positions. Our results show that our fine-grained annotations improve learning compared to the unannotated baseline. Furthermore, $\textit{position-aware}$ control generates better simplification than the $\textit{position-agnostic}$ one. The data and code are available at https://github.com/Chandrayee/CTRL-SIMP.
Do You Want Your Autonomous Car To Drive Like You?
Feb 05, 2018



With progress in enabling autonomous cars to drive safely on the road, it is time to start asking how they should be driving. A common answer is that they should be adopting their users' driving style. This makes the assumption that users want their autonomous cars to drive like they drive - aggressive drivers want aggressive cars, defensive drivers want defensive cars. In this paper, we put that assumption to the test. We find that users tend to prefer a significantly more defensive driving style than their own. Interestingly, they prefer the style they think is their own, even though their actual driving style tends to be more aggressive. We also find that preferences do depend on the specific driving scenario, opening the door for new ways of learning driving style preference.
Learning from Richer Human Guidance: Augmenting Comparison-Based Learning with Feature Queries
Feb 05, 2018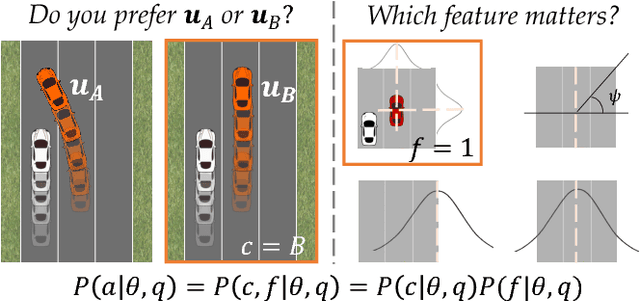
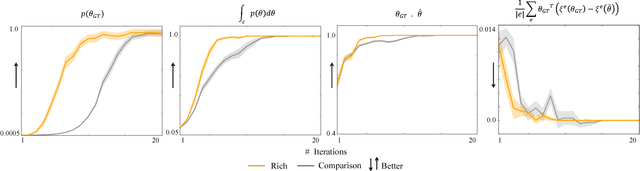
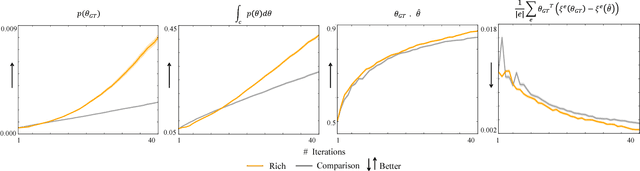
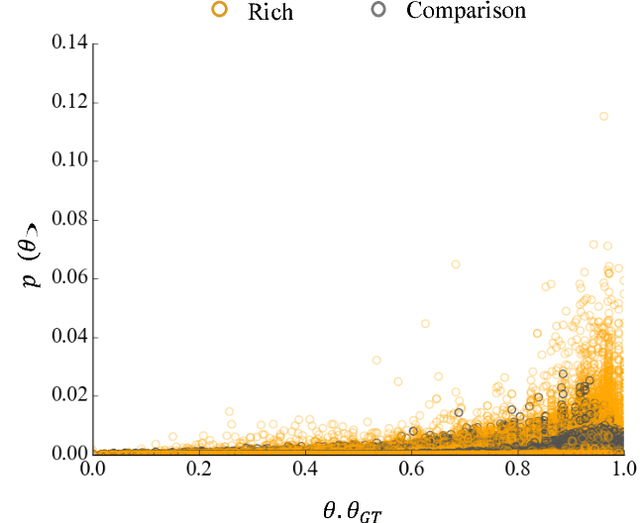
We focus on learning the desired objective function for a robot. Although trajectory demonstrations can be very informative of the desired objective, they can also be difficult for users to provide. Answers to comparison queries, asking which of two trajectories is preferable, are much easier for users, and have emerged as an effective alternative. Unfortunately, comparisons are far less informative. We propose that there is much richer information that users can easily provide and that robots ought to leverage. We focus on augmenting comparisons with feature queries, and introduce a unified formalism for treating all answers as observations about the true desired reward. We derive an active query selection algorithm, and test these queries in simulation and on real users. We find that richer, feature-augmented queries can extract more information faster, leading to robots that better match user preferences in their behavior.
Tracking Motion and Proxemics using Thermal-sensor Array
Nov 25, 2015


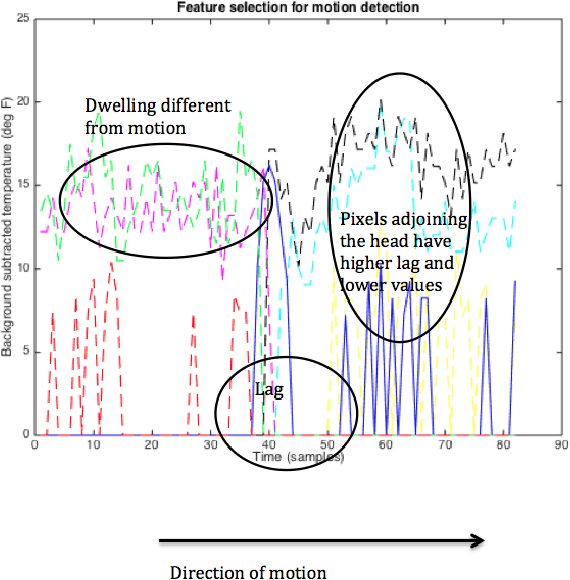
Indoor tracking has all-pervasive applications beyond mere surveillance, for example in education, health monitoring, marketing, energy management and so on. Image and video based tracking systems are intrusive. Thermal array sensors on the other hand can provide coarse-grained tracking while preserving privacy of the subjects. The goal of the project is to facilitate motion detection and group proxemics modeling using an 8 x 8 infrared sensor array. Each of the 8 x 8 pixels is a temperature reading in Fahrenheit. We refer to each 8 x 8 matrix as a scene. We collected approximately 902 scenes with different configurations of human groups and different walking directions. We infer direction of motion of a subject across a set of scenes as left-to-right, right-to-left, up-to-down and down-to-up using cross-correlation analysis. We used features from connected component analysis of each background subtracted scene and performed Support Vector Machine classification to estimate number of instances of human subjects in the scene.