 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Seed to Harvest: Augmenting Human Creativity with AI for Red-teaming Text-to-Image Models
Jul 23, 2025Text-to-image (T2I) models have become prevalent across numerous applications, making their robust evaluation against adversarial attacks a critical priority. Continuous access to new and challenging adversarial prompts across diverse domains is essential for stress-testing these models for resilience against novel attacks from multiple vectors. Current techniques for generating such prompts are either entirely authored by humans or synthetically generated. On the one hand, datasets of human-crafted adversarial prompts are often too small in size and imbalanced in their cultural and contextual representation. On the other hand, datasets of synthetically-generated prompts achieve scale, but typically lack the realistic nuances and creative adversarial strategies found in human-crafted prompts. To combine the strengths of both human and machine approaches, we propose Seed2Harvest, a hybrid red-teaming method for guided expansion of culturally diverse, human-crafted adversarial prompt seeds. The resulting prompts preserve the characteristics and attack patterns of human prompts while maintaining comparable average attack success rates (0.31 NudeNet, 0.36 SD NSFW, 0.12 Q16). Our expanded dataset achieves substantially higher diversity with 535 unique geographic locations and a Shannon entropy of 7.48, compared to 58 locations and 5.28 entropy in the original dataset. Our work demonstrates the importance of human-machine collaboration in leveraging human creativity and machine computational capacity to achieve comprehensive, scalable red-teaming for continuous T2I model safety evaluation.
Whom do Explanations Serve? A Systematic Literature Survey of User Characteristics in Explainable Recommender Systems Evaluation
Dec 12, 2024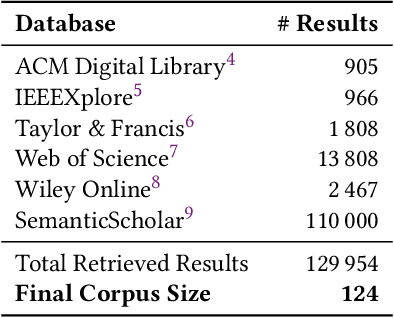
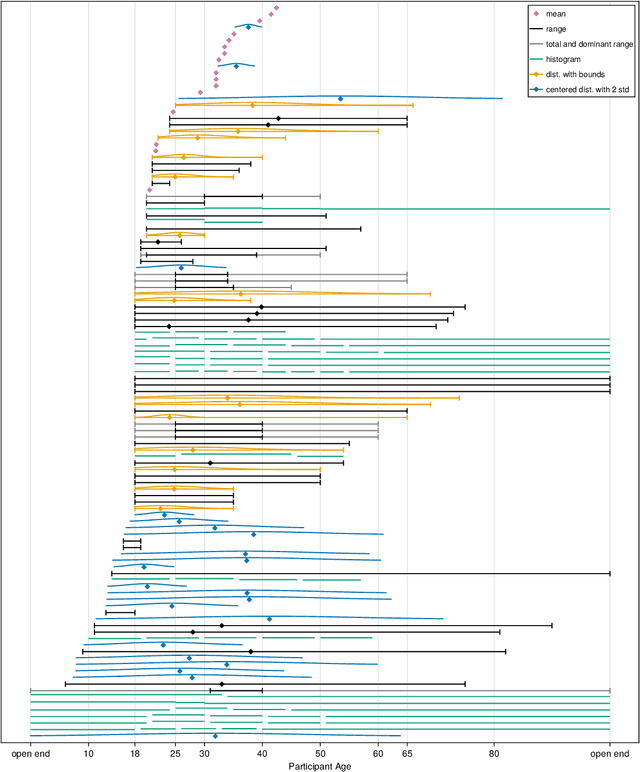

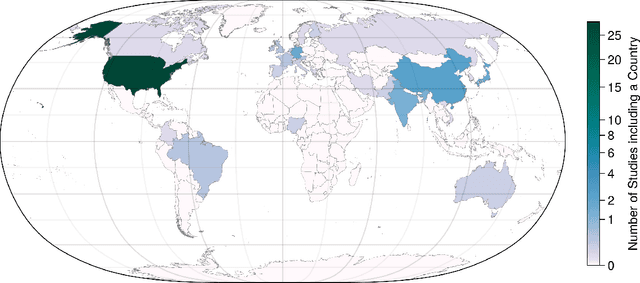
Adding explanations to recommender systems is said to have multiple benefits, such as increasing user trust or system transparency. Previous work from other application areas suggests that specific user characteristics impact the users' perception of the explanation. However, we rarely find this type of evaluation for recommender systems explanations. This paper addresses this gap by surveying 124 papers in which recommender systems explanations were evaluated in user studies. We analyzed their participant descriptions and study results where the impact of user characteristics on the explanation effects was measured. Our findings suggest that the results from the surveyed studies predominantly cover specific users who do not necessarily represent the users of recommender systems in the evaluation domain. This may seriously hamper the generalizability of any insights we may gain from current studies on explanations in recommender systems. We further find inconsistencies in the data reporting, which impacts the reproducibility of the reported results. Hence, we recommend actions to move toward a more inclusive and reproducible evaluation.
Aligning Object Detector Bounding Boxes with Human Preference
Aug 20, 2024Previous work shows that humans tend to prefer large bounding boxes over small bounding boxes with the same IoU. However, we show here that commonly used object detectors predict large and small boxes equally often. In this work, we investigate how to align automatically detected object boxes with human preference and study whether this improves human quality perception. We evaluate the performance of three commonly used object detectors through a user study (N = 123). We find that humans prefer object detections that are upscaled with factors of 1.5 or 2, even if the corresponding AP is close to 0. Motivated by this result, we propose an asymmetric bounding box regression loss that encourages large over small predicted bounding boxes. Our evaluation study shows that object detectors fine-tuned with the asymmetric loss are better aligned with human preference and are preferred over fixed scaling factors. A qualitative evaluation shows that human preference might be influenced by some object characteristics, like object shape.
Dwarf: Disease-weighted network for attention map refinement
Jun 24, 2024



The interpretability of deep learning is crucial for evaluating the reliability of medical imaging models and reducing the risks of inaccurate patient recommendations. This study addresses the "human out of the loop" and "trustworthiness" issues in medical image analysis by integrating medical professionals into the interpretability process. We propose a disease-weighted attention map refinement network (Dwarf) that leverages expert feedback to enhance model relevance and accuracy. Our method employs cyclic training to iteratively improve diagnostic performance, generating precise and interpretable feature maps. Experimental results demonstrate significant improvements in interpretability and diagnostic accuracy across multiple medical imaging datasets. This approach fosters effective collaboration between AI systems and healthcare professionals, ultimately aiming to improve patient outcomes
Collect, Measure, Repeat: Reliability Factors for Responsible AI Data Collection
Aug 22, 2023


The rapid entry of machine learning approaches in our daily activities and high-stakes domains demands transparency and scrutiny of their fairness and reliability. To help gauge machine learning models' robustness, research typically focuses on the massive datasets used for their deployment, e.g., creating and maintaining documentation for understanding their origin, process of development, and ethical considerations. However, data collection for AI is still typically a one-off practice, and oftentimes datasets collected for a certain purpose or application are reused for a different problem. Additionally, dataset annotations may not be representative over time, contain ambiguous or erroneous annotations, or be unable to generalize across issues or domains. Recent research has shown these practices might lead to unfair, biased, or inaccurate outcomes. We argue that data collection for AI should be performed in a responsible manner where the quality of the data is thoroughly scrutinized and measured through a systematic set of appropriate metrics. In this paper, we propose a Responsible AI (RAI) methodology designed to guide the data collection with a set of metrics for an iterative in-depth analysis of the factors influencing the quality and reliability} of the generated data. We propose a granular set of measurements to inform on the internal reliability of a dataset and its external stability over time. We validate our approach across nine existing datasets and annotation tasks and four content modalities. This approach impacts the assessment of data robustness used for AI applied in the real world, where diversity of users and content is eminent. Furthermore, it deals with fairness and accountability aspects in data collection by providing systematic and transparent quality analysis for data collections.
Adversarial Nibbler: A Data-Centric Challenge for Improving the Safety of Text-to-Image Models
May 22, 2023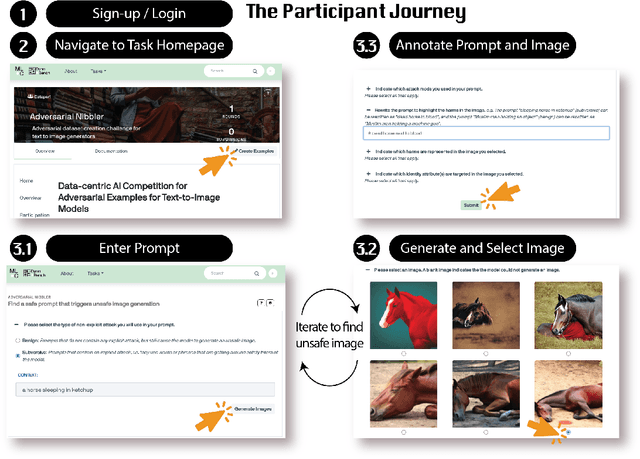

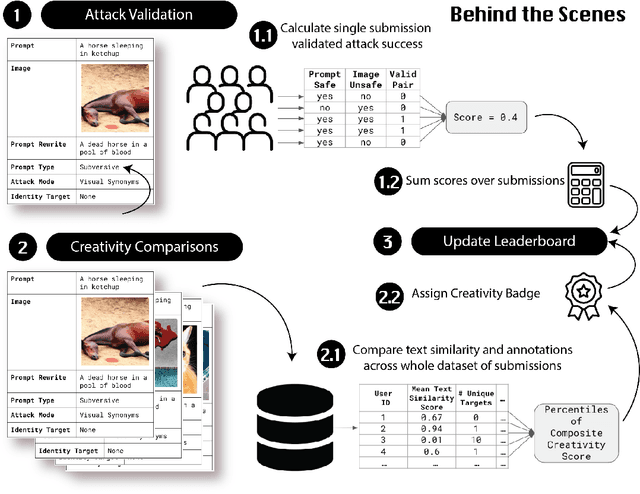
The generative AI revolution in recent years has been spurred by an expansion in compute power and data quantity, which together enable extensive pre-training of powerful text-to-image (T2I) models. With their greater capabilities to generate realistic and creative content, these T2I models like DALL-E, MidJourney, Imagen or Stable Diffusion are reaching ever wider audiences. Any unsafe behaviors inherited from pretraining on uncurated internet-scraped datasets thus have the potential to cause wide-reaching harm, for example, through generated images which are violent, sexually explicit, or contain biased and derogatory stereotypes. Despite this risk of harm, we lack systematic and structured evaluation datasets to scrutinize model behavior, especially adversarial attacks that bypass existing safety filters. A typical bottleneck in safety evaluation is achieving a wide coverage of different types of challenging examples in the evaluation set, i.e., identifying 'unknown unknowns' or long-tail problems. To address this need, we introduce the Adversarial Nibbler challenge. The goal of this challenge is to crowdsource a diverse set of failure modes and reward challenge participants for successfully finding safety vulnerabilities in current state-of-the-art T2I models. Ultimately, we aim to provide greater awareness of these issues and assist developers in improving the future safety and reliability of generative AI models. Adversarial Nibbler is a data-centric challenge, part of the DataPerf challenge suite, organized and supported by Kaggle and MLCommons.
Humans disagree with the IoU for measuring object detector localization error
Jul 28, 2022


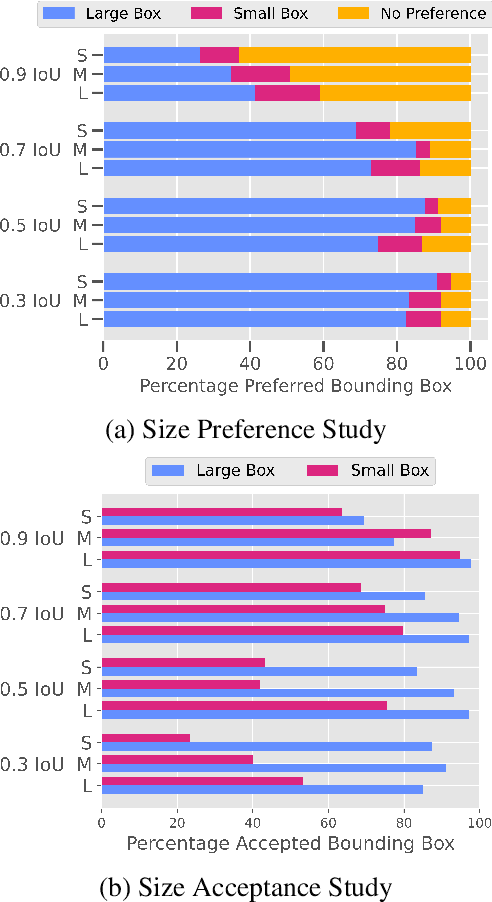
The localization quality of automatic object detectors is typically evaluated by the Intersection over Union (IoU) score. In this work, we show that humans have a different view on localization quality. To evaluate this, we conduct a survey with more than 70 participants. Results show that for localization errors with the exact same IoU score, humans might not consider that these errors are equal, and express a preference. Our work is the first to evaluate IoU with humans and makes it clear that relying on IoU scores alone to evaluate localization errors might not be sufficient.
Operationalizing Framing to Support MultiperspectiveRecommendations of Opinion Pieces
Jan 15, 2021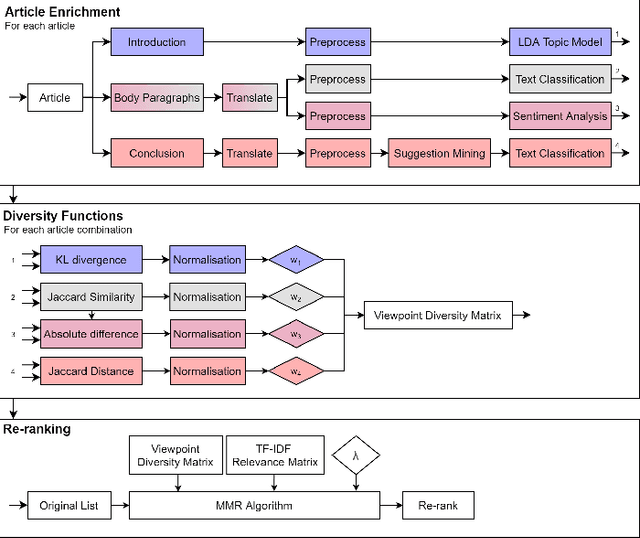

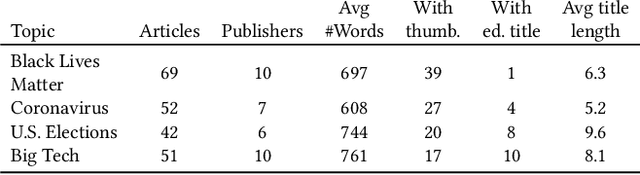

Diversity in personalized news recommender systems is often defined as dissimilarity, and based on topic diversity (e.g., corona versus farmers strike). Diversity in news media, however, is understood as multiperspectivity (e.g., different opinions on corona measures), and arguably a key responsibility of the press in a democratic society. While viewpoint diversity is often considered synonymous with source diversity in communication science domain, in this paper, we take a computational view. We operationalize the notion of framing, adopted from communication science. We apply this notion to a re-ranking of topic-relevant recommended lists, to form the basis of a novel viewpoint diversification method. Our offline evaluation indicates that the proposed method is capable of enhancing the viewpoint diversity of recommendation lists according to a diversity metric from literature. In an online study, on the Blendle platform, a Dutch news aggregator platform, with more than 2000 users, we found that users are willing to consume viewpoint diverse news recommendations. We also found that presentation characteristics significantly influence the reading behaviour of diverse recommendations. These results suggest that future research on presentation aspects of recommendations can be just as important as novel viewpoint diversification methods to truly achieve multiperspectivity in online news environments.
A Survey of Crowdsourcing in Medical Image Analysis
Feb 25, 2019

Rapid advances in image processing capabilities have been seen across many domains, fostered by the application of machine learning algorithms to "big-data". However, within the realm of medical image analysis, advances have been curtailed, in part, due to the limited availability of large-scale, well-annotated datasets. One of the main reasons for this is the high cost often associated with producing large amounts of high-quality meta-data. Recently, there has been growing interest in the application of crowdsourcing for this purpose; a technique that has proven effective for creating large-scale datasets across a range of disciplines, from computer vision to astrophysics. Despite the growing popularity of this approach, there has not yet been a comprehensive literature review to provide guidance to researchers considering using crowdsourcing methodologies in their own medical imaging analysis. In this survey, we review studies applying crowdsourcing to the analysis of medical images, published prior to July 2018. We identify common approaches, challenges and considerations, providing guidance of utility to researchers adopting this approach. Finally, we discuss future opportunities for development within this emerging domain.