 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Language Models for Harmful Manipulation
Mar 26, 2026Interest in the concept of AI-driven harmful manipulation is growing, yet current approaches to evaluating it are limited. This paper introduces a framework for evaluating harmful AI manipulation via context-specific human-AI interaction studies. We illustrate the utility of this framework by assessing an AI model with 10,101 participants spanning interactions in three AI use domains (public policy, finance, and health) and three locales (US, UK, and India). Overall, we find that that the tested model can produce manipulative behaviours when prompted to do so and, in experimental settings, is able to induce belief and behaviour changes in study participants. We further find that context matters: AI manipulation differs between domains, suggesting that it needs to be evaluated in the high-stakes context(s) in which an AI system is likely to be used. We also identify significant differences across our tested geographies, suggesting that AI manipulation results from one geographic region may not generalise to others. Finally, we find that the frequency of manipulative behaviours (propensity) of an AI model is not consistently predictive of the likelihood of manipulative success (efficacy), underscoring the importance of studying these dimensions separately. To facilitate adoption of our evaluation framework, we detail our testing protocols and make relevant materials publicly available. We conclude by discussing open challenges in evaluating harmful manipulation by AI models.
From Seed to Harvest: Augmenting Human Creativity with AI for Red-teaming Text-to-Image Models
Jul 23, 2025Text-to-image (T2I) models have become prevalent across numerous applications, making their robust evaluation against adversarial attacks a critical priority. Continuous access to new and challenging adversarial prompts across diverse domains is essential for stress-testing these models for resilience against novel attacks from multiple vectors. Current techniques for generating such prompts are either entirely authored by humans or synthetically generated. On the one hand, datasets of human-crafted adversarial prompts are often too small in size and imbalanced in their cultural and contextual representation. On the other hand, datasets of synthetically-generated prompts achieve scale, but typically lack the realistic nuances and creative adversarial strategies found in human-crafted prompts. To combine the strengths of both human and machine approaches, we propose Seed2Harvest, a hybrid red-teaming method for guided expansion of culturally diverse, human-crafted adversarial prompt seeds. The resulting prompts preserve the characteristics and attack patterns of human prompts while maintaining comparable average attack success rates (0.31 NudeNet, 0.36 SD NSFW, 0.12 Q16). Our expanded dataset achieves substantially higher diversity with 535 unique geographic locations and a Shannon entropy of 7.48, compared to 58 locations and 5.28 entropy in the original dataset. Our work demonstrates the importance of human-machine collaboration in leveraging human creativity and machine computational capacity to achieve comprehensive, scalable red-teaming for continuous T2I model safety evaluation.
Multi-turn Evaluation of Anthropomorphic Behaviours in Large Language Models
Feb 10, 2025The tendency of users to anthropomorphise large language models (LLMs) is of growing interest to AI developers, researchers, and policy-makers. Here, we present a novel method for empirically evaluating anthropomorphic LLM behaviours in realistic and varied settings. Going beyond single-turn static benchmarks, we contribute three methodological advances in state-of-the-art (SOTA) LLM evaluation. First, we develop a multi-turn evaluation of 14 anthropomorphic behaviours. Second, we present a scalable, automated approach by employing simulations of user interactions. Third, we conduct an interactive, large-scale human subject study (N=1101) to validate that the model behaviours we measure predict real users' anthropomorphic perceptions. We find that all SOTA LLMs evaluated exhibit similar behaviours, characterised by relationship-building (e.g., empathy and validation) and first-person pronoun use, and that the majority of behaviours only first occur after multiple turns. Our work lays an empirical foundation for investigating how design choices influence anthropomorphic model behaviours and for progressing the ethical debate on the desirability of these behaviours. It also showcases the necessity of multi-turn evaluations for complex social phenomena in human-AI interaction.
Insights on Disagreement Patterns in Multimodal Safety Perception across Diverse Rater Groups
Oct 22, 2024



AI systems crucially rely on human ratings, but these ratings are often aggregated, obscuring the inherent diversity of perspectives in real-world phenomenon. This is particularly concerning when evaluating the safety of generative AI, where perceptions and associated harms can vary significantly across socio-cultural contexts. While recent research has studied the impact of demographic differences on annotating text, there is limited understanding of how these subjective variations affect multimodal safety in generative AI. To address this, we conduct a large-scale study employing highly-parallel safety ratings of about 1000 text-to-image (T2I) generations from a demographically diverse rater pool of 630 raters balanced across 30 intersectional groups across age, gender, and ethnicity. Our study shows that (1) there are significant differences across demographic groups (including intersectional groups) on how severe they assess the harm to be, and that these differences vary across different types of safety violations, (2) the diverse rater pool captures annotation patterns that are substantially different from expert raters trained on specific set of safety policies, and (3) the differences we observe in T2I safety are distinct from previously documented group level differences in text-based safety tasks. To further understand these varying perspectives, we conduct a qualitative analysis of the open-ended explanations provided by raters. This analysis reveals core differences into the reasons why different groups perceive harms in T2I generations. Our findings underscore the critical need for incorporating diverse perspectives into safety evaluation of generative AI ensuring these systems are truly inclusive and reflect the values of all users.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Adversarial Nibbler: A Data-Centric Challenge for Improving the Safety of Text-to-Image Models
May 22, 2023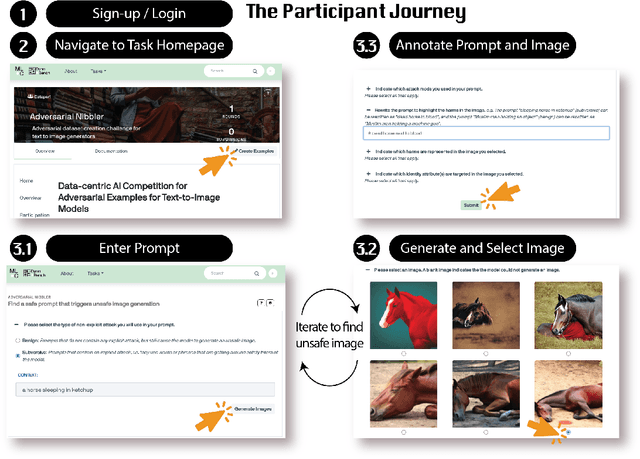

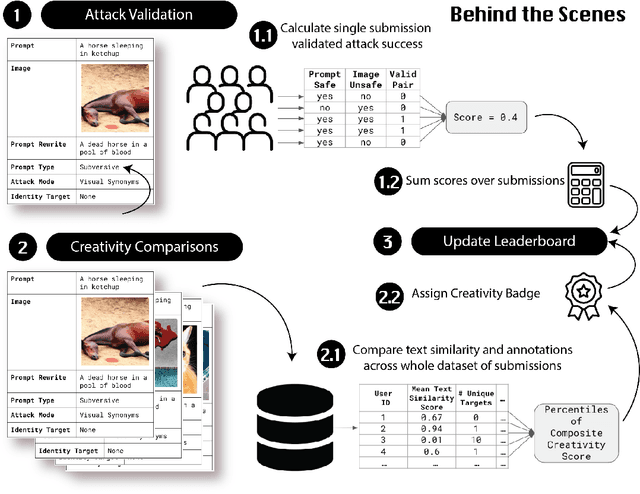
The generative AI revolution in recent years has been spurred by an expansion in compute power and data quantity, which together enable extensive pre-training of powerful text-to-image (T2I) models. With their greater capabilities to generate realistic and creative content, these T2I models like DALL-E, MidJourney, Imagen or Stable Diffusion are reaching ever wider audiences. Any unsafe behaviors inherited from pretraining on uncurated internet-scraped datasets thus have the potential to cause wide-reaching harm, for example, through generated images which are violent, sexually explicit, or contain biased and derogatory stereotypes. Despite this risk of harm, we lack systematic and structured evaluation datasets to scrutinize model behavior, especially adversarial attacks that bypass existing safety filters. A typical bottleneck in safety evaluation is achieving a wide coverage of different types of challenging examples in the evaluation set, i.e., identifying 'unknown unknowns' or long-tail problems. To address this need, we introduce the Adversarial Nibbler challenge. The goal of this challenge is to crowdsource a diverse set of failure modes and reward challenge participants for successfully finding safety vulnerabilities in current state-of-the-art T2I models. Ultimately, we aim to provide greater awareness of these issues and assist developers in improving the future safety and reliability of generative AI models. Adversarial Nibbler is a data-centric challenge, part of the DataPerf challenge suite, organized and supported by Kaggle and MLCommons.
Supporting Human-AI Collaboration in Auditing LLMs with LLMs
Apr 19, 2023



Large language models are becoming increasingly pervasive and ubiquitous in society via deployment in sociotechnical systems. Yet these language models, be it for classification or generation, have been shown to be biased and behave irresponsibly, causing harm to people at scale. It is crucial to audit these language models rigorously. Existing auditing tools leverage either or both humans and AI to find failures. In this work, we draw upon literature in human-AI collaboration and sensemaking, and conduct interviews with research experts in safe and fair AI, to build upon the auditing tool: AdaTest (Ribeiro and Lundberg, 2022), which is powered by a generative large language model (LLM). Through the design process we highlight the importance of sensemaking and human-AI communication to leverage complementary strengths of humans and generative models in collaborative auditing. To evaluate the effectiveness of the augmented tool, AdaTest++, we conduct user studies with participants auditing two commercial language models: OpenAI's GPT-3 and Azure's sentiment analysis model. Qualitative analysis shows that AdaTest++ effectively leverages human strengths such as schematization, hypothesis formation and testing. Further, with our tool, participants identified a variety of failures modes, covering 26 different topics over 2 tasks, that have been shown before in formal audits and also those previously under-reported.
How do Authors' Perceptions of their Papers Compare with Co-authors' Perceptions and Peer-review Decisions?
Nov 22, 2022



How do author perceptions match up to the outcomes of the peer-review process and perceptions of others? In a top-tier computer science conference (NeurIPS 2021) with more than 23,000 submitting authors and 9,000 submitted papers, we survey the authors on three questions: (i) their predicted probability of acceptance for each of their papers, (ii) their perceived ranking of their own papers based on scientific contribution, and (iii) the change in their perception about their own papers after seeing the reviews. The salient results are: (1) Authors have roughly a three-fold overestimate of the acceptance probability of their papers: The median prediction is 70% for an approximately 25% acceptance rate. (2) Female authors exhibit a marginally higher (statistically significant) miscalibration than male authors; predictions of authors invited to serve as meta-reviewers or reviewers are similarly calibrated, but better than authors who were not invited to review. (3) Authors' relative ranking of scientific contribution of two submissions they made generally agree (93%) with their predicted acceptance probabilities, but there is a notable 7% responses where authors think their better paper will face a worse outcome. (4) The author-provided rankings disagreed with the peer-review decisions about a third of the time; when co-authors ranked their jointly authored papers, co-authors disagreed at a similar rate -- about a third of the time. (5) At least 30% of respondents of both accepted and rejected papers said that their perception of their own paper improved after the review process. The stakeholders in peer review should take these findings into account in setting their expectations from peer review.
A Unifying Framework for Combining Complementary Strengths of Humans and ML toward Better Predictive Decision-Making
Apr 22, 2022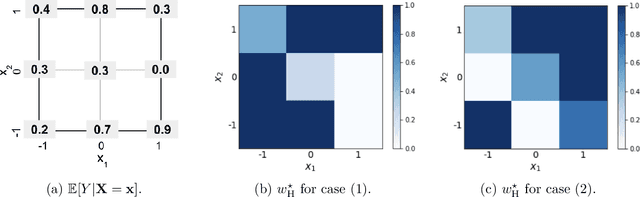
Hybrid human-ML systems are increasingly in charge of consequential decisions in a wide range of domains. A growing body of work has advanced our understanding of these systems by providing empirical and theoretical analyses. However, existing empirical results are mixed, and theoretical proposals are often incompatible with each other. Our goal in this work is to bring much-needed organization to this field by offering a unifying framework for understanding conditions under which combining complementary strengths of human and ML leads to higher quality decisions than those produced by them individually -- a state to which we refer to as human-ML complementarity. We focus specifically on the context of human-ML predictive decision-making systems and investigate optimal ways of combining human and ML-based predictive decisions, accounting for the underlying causes of variation in their judgments. Within this scope, we present two crucial contributions. First, drawing upon prior literature in human psychology, machine learning, and human-computer interaction, we introduce a taxonomy characterizing a wide variety of criteria across which human and machine decision-making differ. Building on our taxonomy, our second contribution presents a unifying optimization-based framework for formalizing how human and ML predictive decisions should be aggregated optimally. We show that our proposed framework encompasses several existing models of human-ML complementarity as special cases. Last but not least, the exploratory analysis of our framework offers a critical piece of insight for future work in this area: the mechanism by which we combine human-ML judgments should be informed by the underlying causes of their diverging decisions.
A Large Scale Randomized Controlled Trial on Herding in Peer-Review Discussions
Nov 30, 2020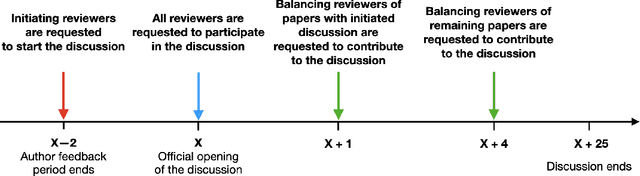

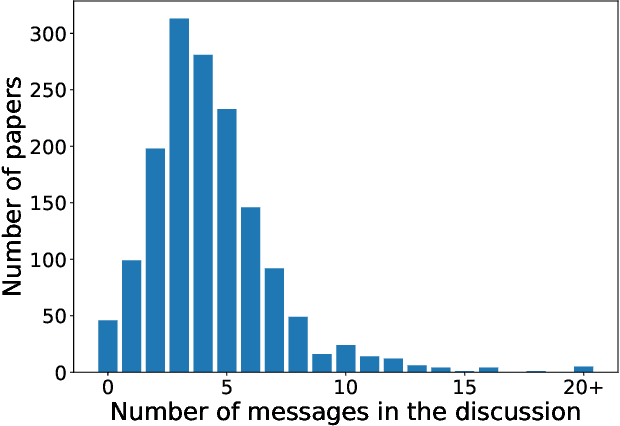

Peer review is the backbone of academia and humans constitute a cornerstone of this process, being responsible for reviewing papers and making the final acceptance/rejection decisions. Given that human decision making is known to be susceptible to various cognitive biases, it is important to understand which (if any) biases are present in the peer-review process and design the pipeline such that the impact of these biases is minimized. In this work, we focus on the dynamics of between-reviewers discussions and investigate the presence of herding behaviour therein. In that, we aim to understand whether reviewers and more senior decision makers get disproportionately influenced by the first argument presented in the discussion when (in case of reviewers) they form an independent opinion about the paper before discussing it with others. Specifically, in conjunction with the review process of ICML 2020 -- a large, top tier machine learning conference -- we design and execute a randomized controlled trial with the goal of testing for the conditional causal effect of the discussion initiator's opinion on the outcome of a paper.