 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeciding Fast and Slow: The Role of Cognitive Biases in AI-assisted Decision-making
Oct 15, 2020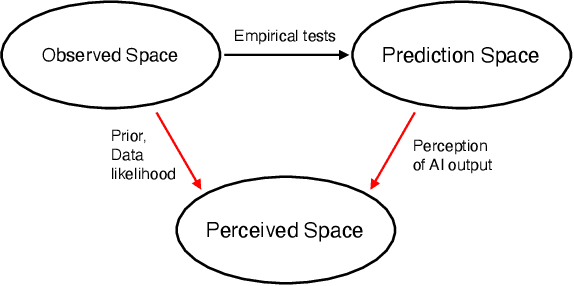
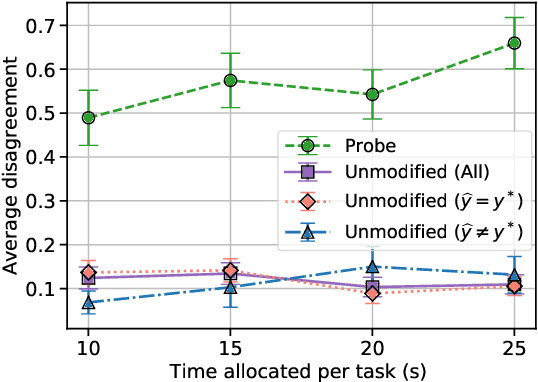
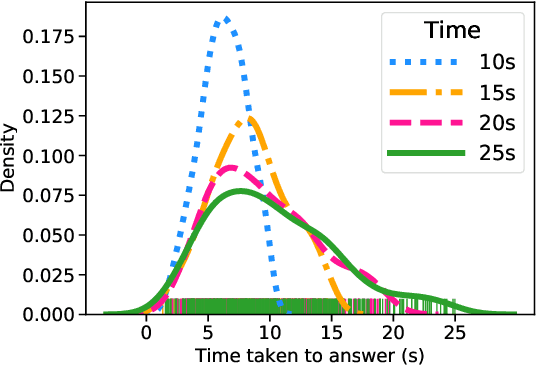
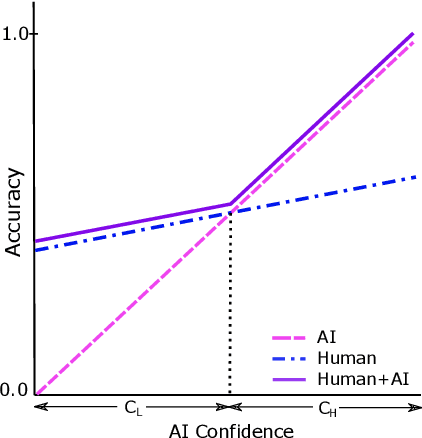
Several strands of research have aimed to bridge the gap between artificial intelligence (AI) and human decision-makers in AI-assisted decision-making, where humans are the consumers of AI model predictions and the ultimate decision-makers in high-stakes applications. However, people's perception and understanding is often distorted by their cognitive biases, like confirmation bias, anchoring bias, availability bias, to name a few. In this work, we use knowledge from the field of cognitive science to account for cognitive biases in the human-AI collaborative decision-making system and mitigate their negative effects. To this end, we mathematically model cognitive biases and provide a general framework through which researchers and practitioners can understand the interplay between cognitive biases and human-AI accuracy. We then focus on anchoring bias, a bias commonly witnessed in human-AI partnerships. We devise a cognitive science-driven, time-based approach to de-anchoring. A user experiment shows the effectiveness of this approach in human-AI collaborative decision-making. Using the results from this first experiment, we design a time allocation strategy for a resource constrained setting so as to achieve optimal human-AI collaboration under some assumptions. A second user study shows that our time allocation strategy can effectively debias the human when the AI model has low confidence and is incorrect.
Explaining Motion Relevance for Activity Recognition in Video Deep Learning Models
Mar 31, 2020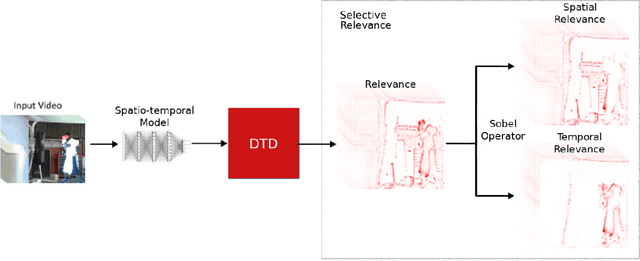
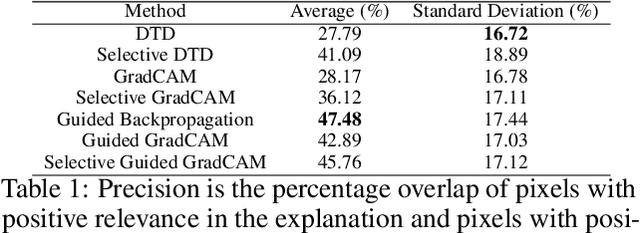
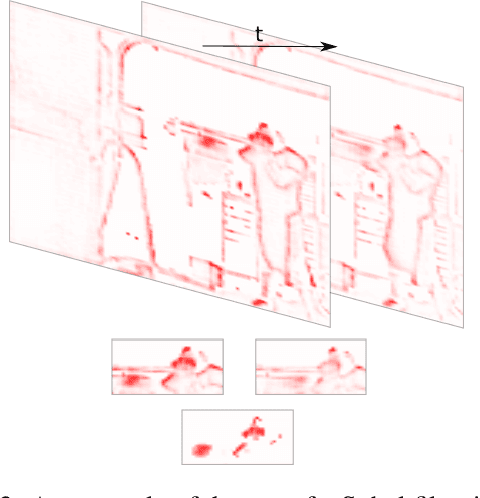

A small subset of explainability techniques developed initially for image recognition models has recently been applied for interpretability of 3D Convolutional Neural Network models in activity recognition tasks. Much like the models themselves, the techniques require little or no modification to be compatible with 3D inputs. However, these explanation techniques regard spatial and temporal information jointly. Therefore, using such explanation techniques, a user cannot explicitly distinguish the role of motion in a 3D model's decision. In fact, it has been shown that these models do not appropriately factor motion information into their decision. We propose a selective relevance method for adapting the 2D explanation techniques to provide motion-specific explanations, better aligning them with the human understanding of motion as conceptually separate from static spatial features. We demonstrate the utility of our method in conjunction with several widely-used 2D explanation methods, and show that it improves explanation selectivity for motion. Our results show that the selective relevance method can not only provide insight on the role played by motion in the model's decision -- in effect, revealing and quantifying the model's spatial bias -- but the method also simplifies the resulting explanations for human consumption.
Sanity Checks for Saliency Metrics
Nov 29, 2019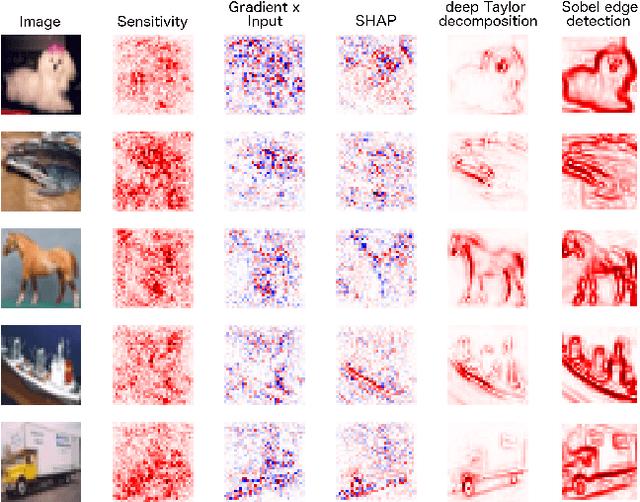
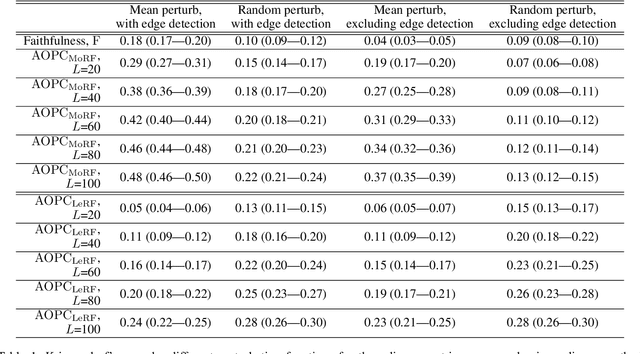
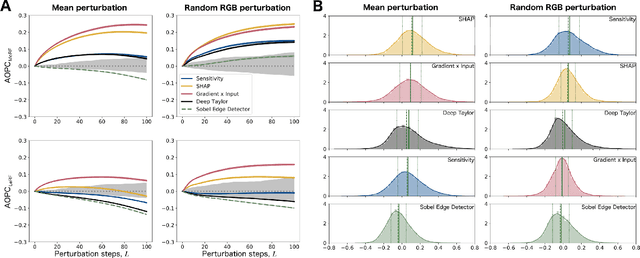
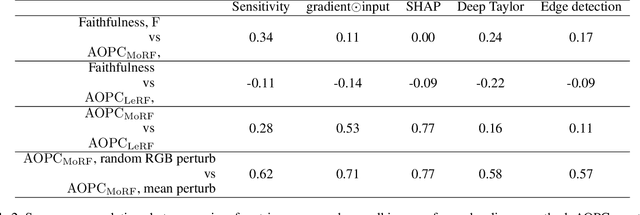
Saliency maps are a popular approach to creating post-hoc explanations of image classifier outputs. These methods produce estimates of the relevance of each pixel to the classification output score, which can be displayed as a saliency map that highlights important pixels. Despite a proliferation of such methods, little effort has been made to quantify how good these saliency maps are at capturing the true relevance of the pixels to the classifier output (i.e. their "fidelity"). We therefore investigate existing metrics for evaluating the fidelity of saliency methods (i.e. saliency metrics). We find that there is little consistency in the literature in how such metrics are calculated, and show that such inconsistencies can have a significant effect on the measured fidelity. Further, we apply measures of reliability developed in the psychometric testing literature to assess the consistency of saliency metrics when applied to individual saliency maps. Our results show that saliency metrics can be statistically unreliable and inconsistent, indicating that comparative rankings between saliency methods generated using such metrics can be untrustworthy.
Illuminated Decision Trees with Lucid
Sep 03, 2019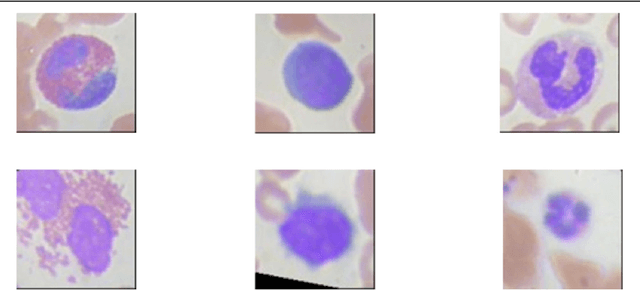

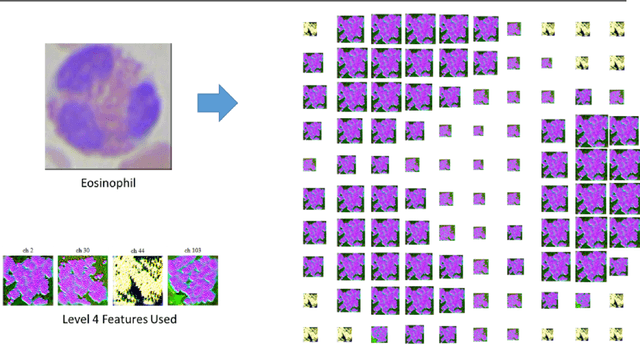
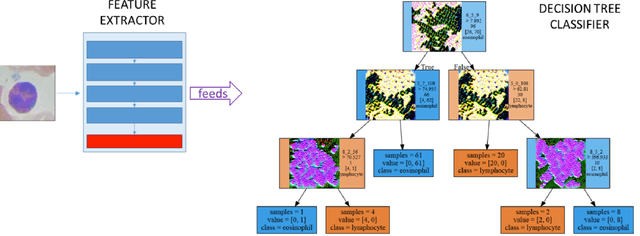
The Lucid methods described by Olah et al. (2018) provide a way to inspect the inner workings of neural networks trained on image classification tasks using feature visualization. Such methods have generally been applied to networks trained on visually rich, large-scale image datasets like ImageNet, which enables them to produce enticing feature visualizations. To investigate these methods further, we applied them to classifiers trained to perform the much simpler (in terms of dataset size and visual richness), yet challenging task of distinguishing between different kinds of white blood cell from microscope images. Such a task makes generating useful feature visualizations difficult, as the discriminative features are inherently hard to identify and interpret. We address this by presenting the "Illuminated Decision Tree" approach, in which we use a neural network trained on the task as a feature extractor, then learn a decision tree based on these features, and provide Lucid visualizations for each node in the tree. We demonstrate our approach with several examples, showing how this approach could be useful both in model development and debugging, and when explaining model outputs to non-experts.
Stakeholders in Explainable AI
Sep 29, 2018

There is general consensus that it is important for artificial intelligence (AI) and machine learning systems to be explainable and/or interpretable. However, there is no general consensus over what is meant by 'explainable' and 'interpretable'. In this paper, we argue that this lack of consensus is due to there being several distinct stakeholder communities. We note that, while the concerns of the individual communities are broadly compatible, they are not identical, which gives rise to different intents and requirements for explainability/interpretability. We use the software engineering distinction between validation and verification, and the epistemological distinctions between knowns/unknowns, to tease apart the concerns of the stakeholder communities and highlight the areas where their foci overlap or diverge. It is not the purpose of the authors of this paper to 'take sides' - we count ourselves as members, to varying degrees, of multiple communities - but rather to help disambiguate what stakeholders mean when they ask 'Why?' of an AI.
Interpretable to Whom? A Role-based Model for Analyzing Interpretable Machine Learning Systems
Jun 20, 2018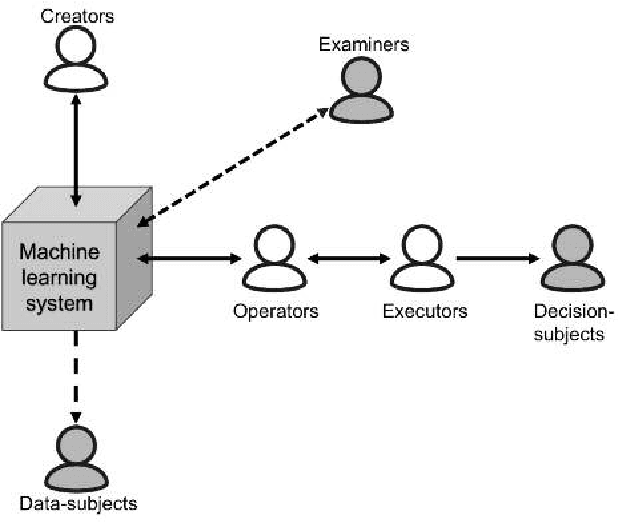
Several researchers have argued that a machine learning system's interpretability should be defined in relation to a specific agent or task: we should not ask if the system is interpretable, but to whom is it interpretable. We describe a model intended to help answer this question, by identifying different roles that agents can fulfill in relation to the machine learning system. We illustrate the use of our model in a variety of scenarios, exploring how an agent's role influences its goals, and the implications for defining interpretability. Finally, we make suggestions for how our model could be useful to interpretability researchers, system developers, and regulatory bodies auditing machine learning systems.