 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoalitions of Large Language Models Increase the Robustness of AI Agents
Aug 02, 2024
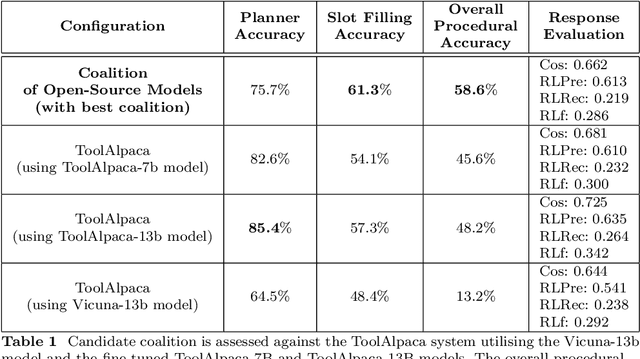
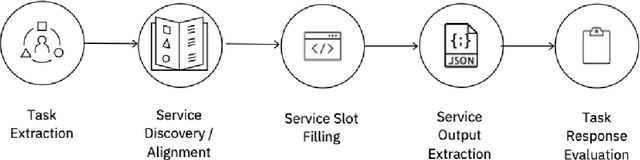
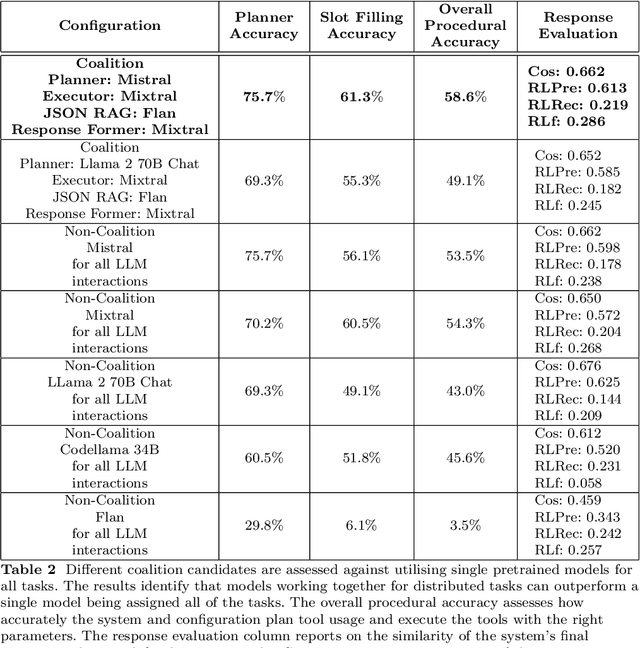
The emergence of Large Language Models (LLMs) have fundamentally altered the way we interact with digital systems and have led to the pursuit of LLM powered AI agents to assist in daily workflows. LLMs, whilst powerful and capable of demonstrating some emergent properties, are not logical reasoners and often struggle to perform well at all sub-tasks carried out by an AI agent to plan and execute a workflow. While existing studies tackle this lack of proficiency by generalised pretraining at a huge scale or by specialised fine-tuning for tool use, we assess if a system comprising of a coalition of pretrained LLMs, each exhibiting specialised performance at individual sub-tasks, can match the performance of single model agents. The coalition of models approach showcases its potential for building robustness and reducing the operational costs of these AI agents by leveraging traits exhibited by specific models. Our findings demonstrate that fine-tuning can be mitigated by considering a coalition of pretrained models and believe that this approach can be applied to other non-agentic systems which utilise LLMs.
Can we Constrain Concept Bottleneck Models to Learn Semantically Meaningful Input Features?
Feb 01, 2024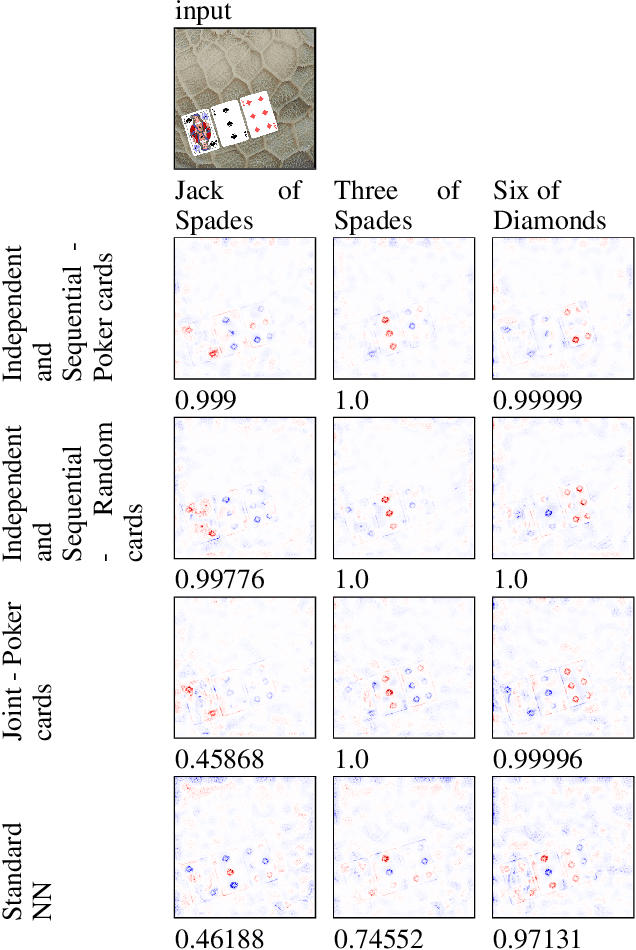
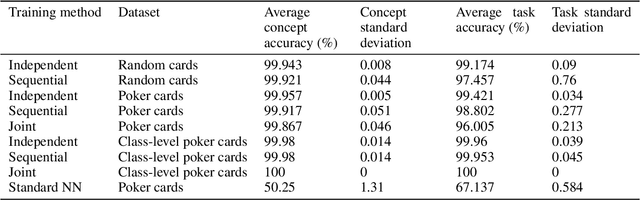
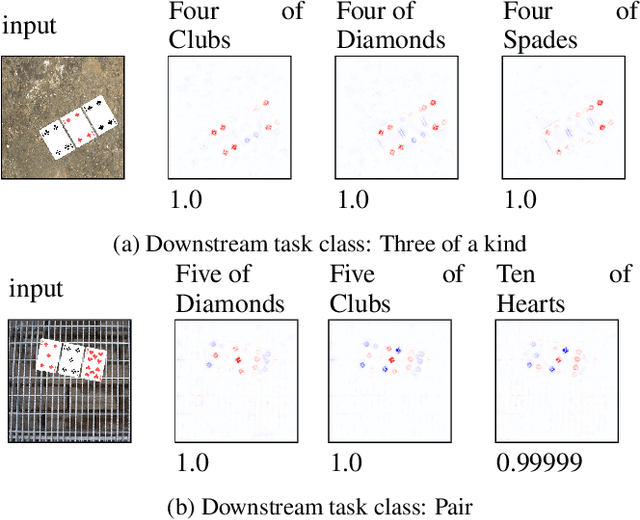

Concept Bottleneck Models (CBMs) are considered inherently interpretable because they first predict a set of human-defined concepts before using these concepts to predict the output of a downstream task. For inherent interpretability to be fully realised, and ensure trust in a model's output, we need to guarantee concepts are predicted based on semantically mapped input features. For example, one might expect the pixels representing a broken bone in an image to be used for the prediction of a fracture. However, current literature indicates this is not the case, as concept predictions are often mapped to irrelevant input features. We hypothesise that this occurs when concept annotations are inaccurate or how input features should relate to concepts is unclear. In general, the effect of dataset labelling on concept representations in CBMs remains an understudied area. Therefore, in this paper, we examine how CBMs learn concepts from datasets with fine-grained concept annotations. We demonstrate that CBMs can learn concept representations with semantic mapping to input features by removing problematic concept correlations, such as two concepts always appearing together. To support our evaluation, we introduce a new synthetic image dataset based on a playing cards domain, which we hope will serve as a benchmark for future CBM research. For validation, we provide empirical evidence on a real-world dataset of chest X-rays, to demonstrate semantically meaningful concepts can be learned in real-world applications.
Towards a Deeper Understanding of Concept Bottleneck Models Through End-to-End Explanation
Feb 07, 2023Concept Bottleneck Models (CBMs) first map raw input(s) to a vector of human-defined concepts, before using this vector to predict a final classification. We might therefore expect CBMs capable of predicting concepts based on distinct regions of an input. In doing so, this would support human interpretation when generating explanations of the model's outputs to visualise input features corresponding to concepts. The contribution of this paper is threefold: Firstly, we expand on existing literature by looking at relevance both from the input to the concept vector, confirming that relevance is distributed among the input features, and from the concept vector to the final classification where, for the most part, the final classification is made using concepts predicted as present. Secondly, we report a quantitative evaluation to measure the distance between the maximum input feature relevance and the ground truth location; we perform this with the techniques, Layer-wise Relevance Propagation (LRP), Integrated Gradients (IG) and a baseline gradient approach, finding LRP has a lower average distance than IG. Thirdly, we propose using the proportion of relevance as a measurement for explaining concept importance.
An Experimentation Platform for Explainable Coalition Situational Understanding
Nov 09, 2020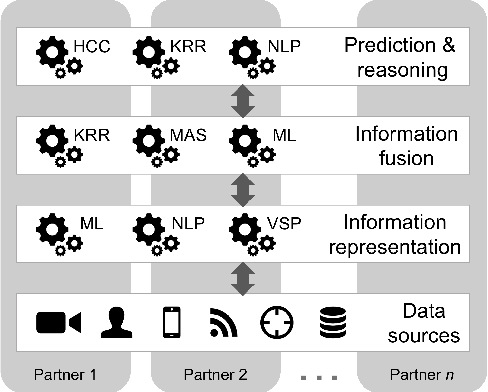
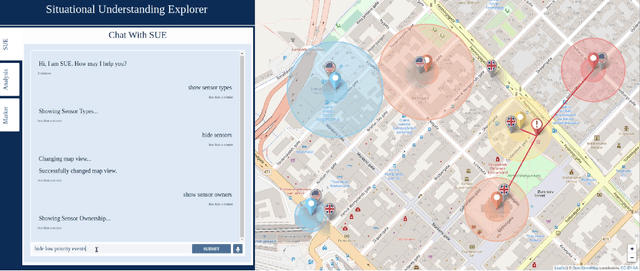
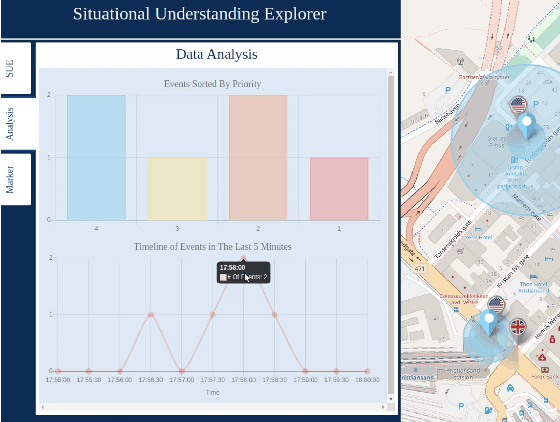
We present an experimentation platform for coalition situational understanding research that highlights capabilities in explainable artificial intelligence/machine learning (AI/ML) and integration of symbolic and subsymbolic AI/ML approaches for event processing. The Situational Understanding Explorer (SUE) platform is designed to be lightweight, to easily facilitate experiments and demonstrations, and open. We discuss our requirements to support coalition multi-domain operations with emphasis on asset interoperability and ad hoc human-machine teaming in a dense urban terrain setting. We describe the interface functionality and give examples of SUE applied to coalition situational understanding tasks.
Towards human-agent knowledge fusion (HAKF) in support of distributed coalition teams
Oct 23, 2020
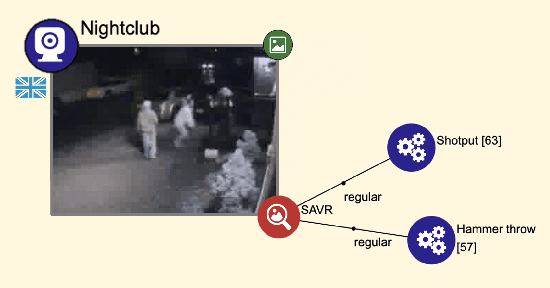
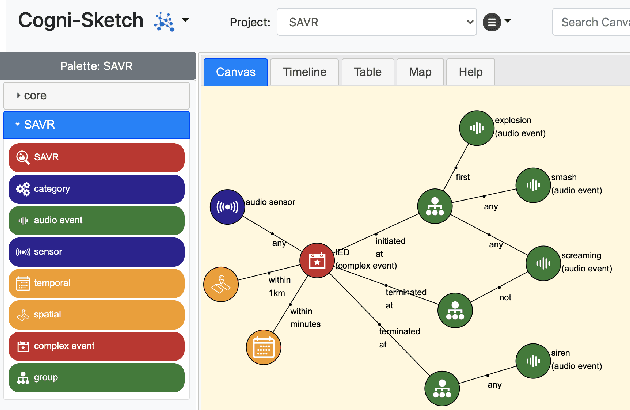
Future coalition operations can be substantially augmented through agile teaming between human and machine agents, but in a coalition context these agents may be unfamiliar to the human users and expected to operate in a broad set of scenarios rather than being narrowly defined for particular purposes. In such a setting it is essential that the human agents can rapidly build trust in the machine agents through appropriate transparency of their behaviour, e.g., through explanations. The human agents are also able to bring their local knowledge to the team, observing the situation unfolding and deciding which key information should be communicated to the machine agents to enable them to better account for the particular environment. In this paper we describe the initial steps towards this human-agent knowledge fusion (HAKF) environment through a recap of the key requirements, and an explanation of how these can be fulfilled for an example situation. We show how HAKF has the potential to bring value to both human and machine agents working as part of a distributed coalition team in a complex event processing setting with uncertain sources.
Explainable AI for Intelligence Augmentation in Multi-Domain Operations
Oct 16, 2019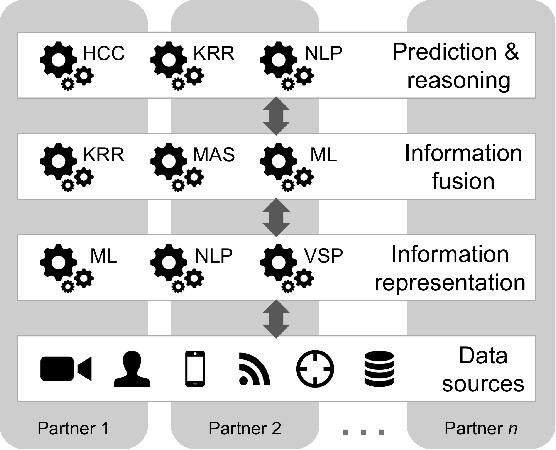
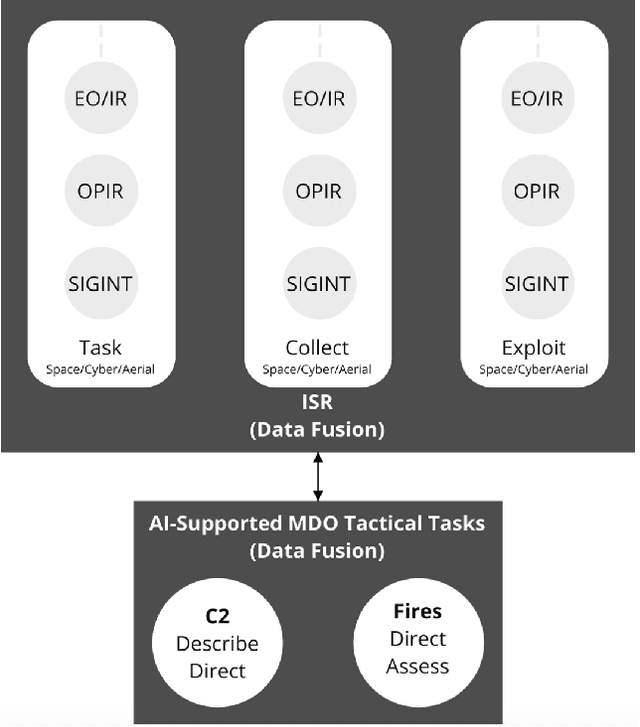
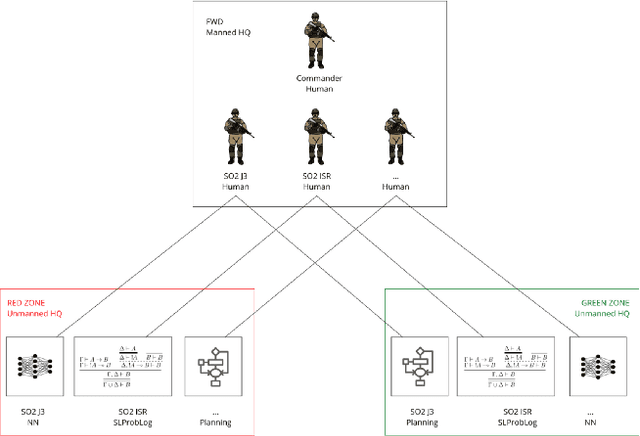
Central to the concept of multi-domain operations (MDO) is the utilization of an intelligence, surveillance, and reconnaissance (ISR) network consisting of overlapping systems of remote and autonomous sensors, and human intelligence, distributed among multiple partners. Realising this concept requires advancement in both artificial intelligence (AI) for improved distributed data analytics and intelligence augmentation (IA) for improved human-machine cognition. The contribution of this paper is threefold: (1) we map the coalition situational understanding (CSU) concept to MDO ISR requirements, paying particular attention to the need for assured and explainable AI to allow robust human-machine decision-making where assets are distributed among multiple partners; (2) we present illustrative vignettes for AI and IA in MDO ISR, including human-machine teaming, dense urban terrain analysis, and enhanced asset interoperability; (3) we appraise the state-of-the-art in explainable AI in relation to the vignettes with a focus on human-machine collaboration to achieve more rapid and agile coalition decision-making. The union of these three elements is intended to show the potential value of a CSU approach in the context of MDO ISR, grounded in three distinct use cases, highlighting how the need for explainability in the multi-partner coalition setting is key.
gl2vec: Learning Feature Representation Using Graphlets for Directed Networks
Dec 13, 2018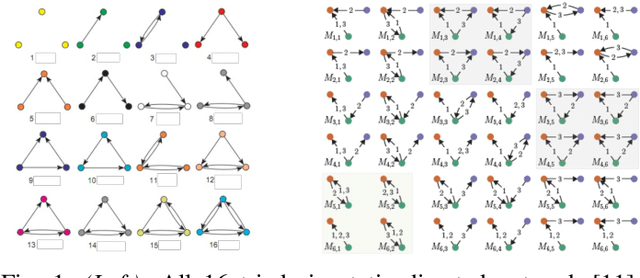
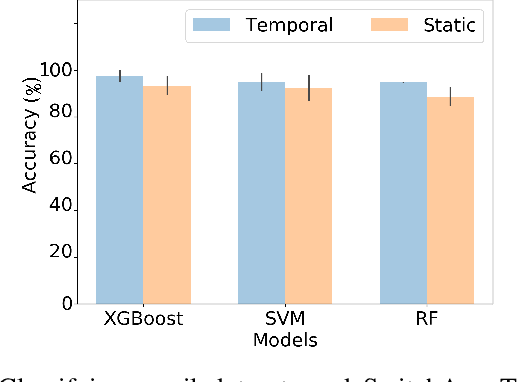
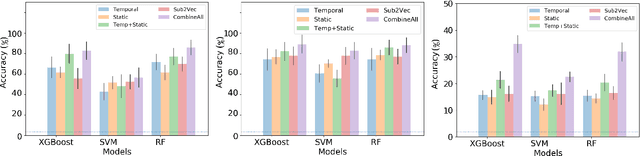
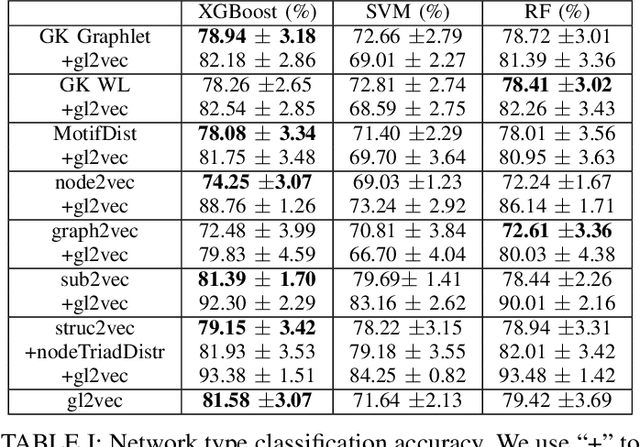
Learning network representations has a variety of applications, such as network classification. Most existing work in this area focuses on static undirected networks and do not account for presence of directed edges or temporarily changes. Furthermore, most work focuses on node representations that do poorly on tasks like network classification. In this paper, we propose a novel, flexible and scalable network embedding methodology, \emph{gl2vec}, for network classification in both static and temporal directed networks. \emph{gl2vec} constructs vectors for feature representation using static or temporal network graphlet distributions and a null model for comparing them against random graphs. We argue that \emph{gl2vec} can be used to classify and compare networks of varying sizes and time period with high accuracy. We demonstrate the efficacy and usability of \emph{gl2vec} over existing state-of-the-art methods on network classification tasks such as network type classification and subgraph identification in several real-world static and temporal directed networks. Experimental results further show that \emph{gl2vec}, concatenated with a wide range of state-of-the-art methods, improves classification accuracy by up to $10\%$ in real-world applications such as detecting departments for subgraphs in an email network or identifying mobile users given their app switching behaviors represented as static or temporal directed networks.
Hows and Whys of Artificial Intelligence for Public Sector Decisions: Explanation and Evaluation
Oct 19, 2018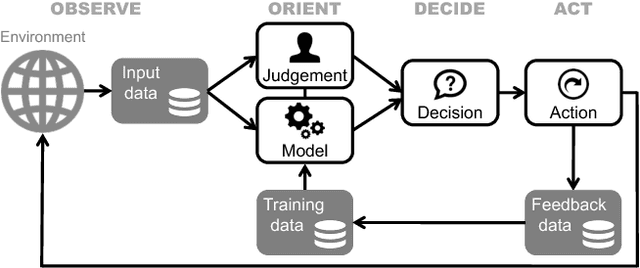
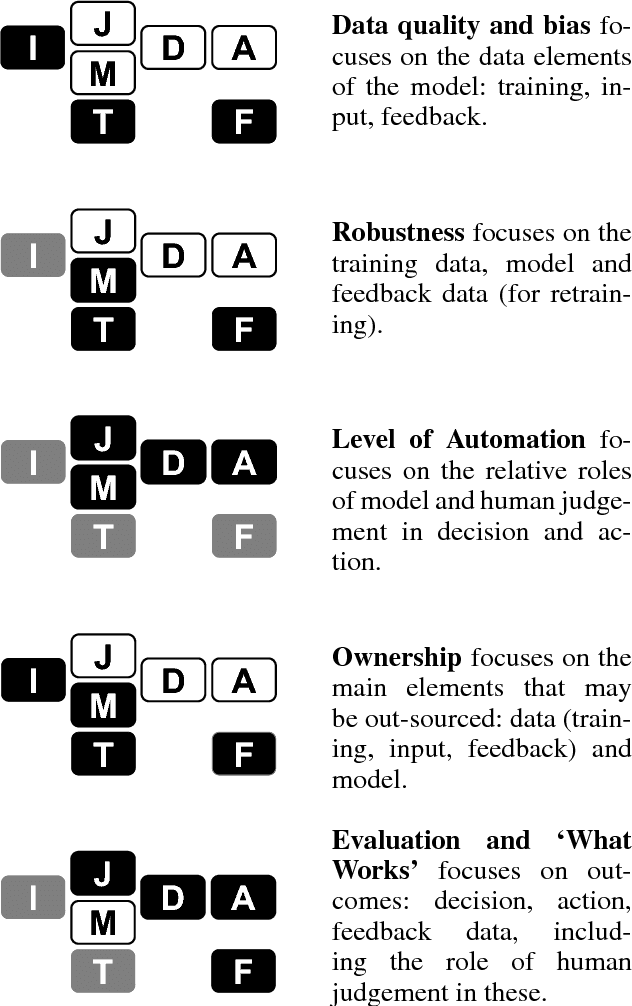
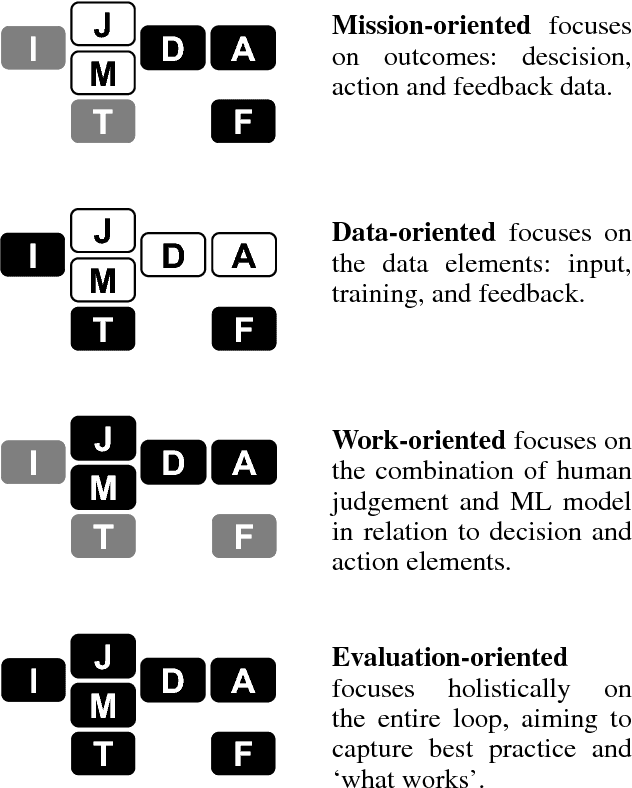
Evaluation has always been a key challenge in the development of artificial intelligence (AI) based software, due to the technical complexity of the software artifact and, often, its embedding in complex sociotechnical processes. Recent advances in machine learning (ML) enabled by deep neural networks has exacerbated the challenge of evaluating such software due to the opaque nature of these ML-based artifacts. A key related issue is the (in)ability of such systems to generate useful explanations of their outputs, and we argue that the explanation and evaluation problems are closely linked. The paper models the elements of a ML-based AI system in the context of public sector decision (PSD) applications involving both artificial and human intelligence, and maps these elements against issues in both evaluation and explanation, showing how the two are related. We consider a number of common PSD application patterns in the light of our model, and identify a set of key issues connected to explanation and evaluation in each case. Finally, we propose multiple strategies to promote wider adoption of AI/ML technologies in PSD, where each is distinguished by a focus on different elements of our model, allowing PSD policy makers to adopt an approach that best fits their context and concerns.
Stakeholders in Explainable AI
Sep 29, 2018

There is general consensus that it is important for artificial intelligence (AI) and machine learning systems to be explainable and/or interpretable. However, there is no general consensus over what is meant by 'explainable' and 'interpretable'. In this paper, we argue that this lack of consensus is due to there being several distinct stakeholder communities. We note that, while the concerns of the individual communities are broadly compatible, they are not identical, which gives rise to different intents and requirements for explainability/interpretability. We use the software engineering distinction between validation and verification, and the epistemological distinctions between knowns/unknowns, to tease apart the concerns of the stakeholder communities and highlight the areas where their foci overlap or diverge. It is not the purpose of the authors of this paper to 'take sides' - we count ourselves as members, to varying degrees, of multiple communities - but rather to help disambiguate what stakeholders mean when they ask 'Why?' of an AI.
Network Classification in Temporal Networks Using Motifs
Aug 07, 2018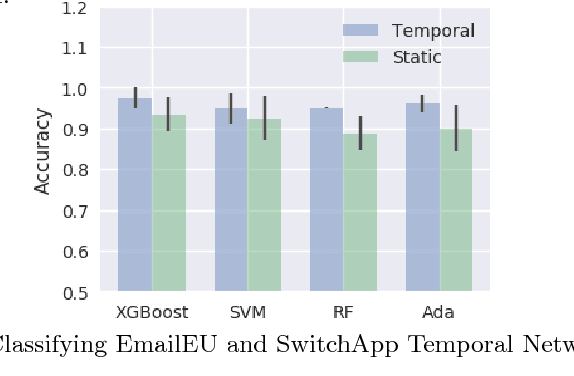
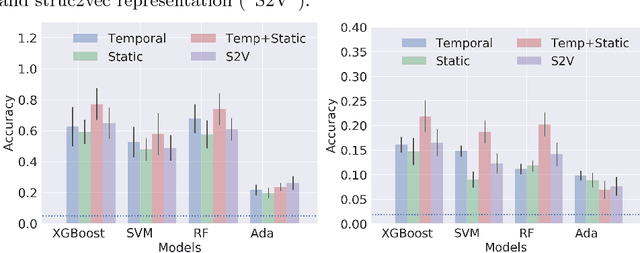
Network classification has a variety of applications, such as detecting communities within networks and finding similarities between those representing different aspects of the real world. However, most existing work in this area focus on examining static undirected networks without considering directed edges or temporality. In this paper, we propose a new methodology that utilizes feature representation for network classification based on the temporal motif distribution of the network and a null model for comparing against random graphs. Experimental results show that our method improves accuracy by up $10\%$ compared to the state-of-the-art embedding method in network classification, for tasks such as classifying network type, identifying communities in email exchange network, and identifying users given their app-switching behaviors.