 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing Explanation-Related Interactions in Collaborative Perception-Cognition-Communication-Action
Nov 19, 2024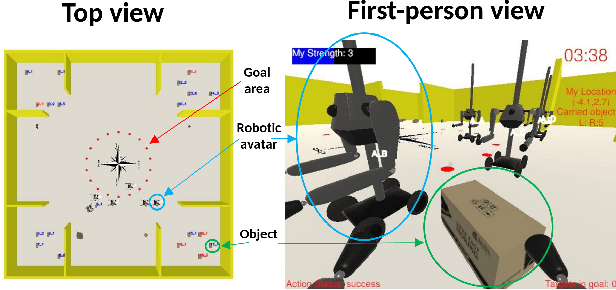
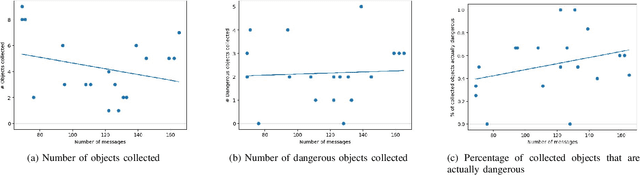
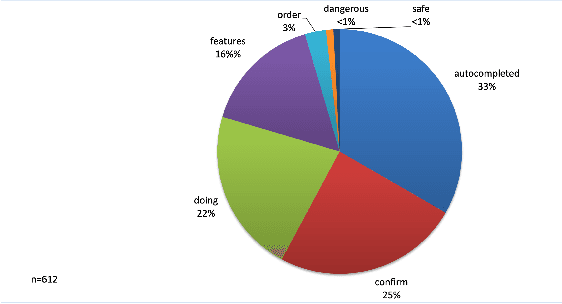

Effective communication is essential in collaborative tasks, so AI-equipped robots working alongside humans need to be able to explain their behaviour in order to cooperate effectively and earn trust. We analyse and classify communications among human participants collaborating to complete a simulated emergency response task. The analysis identifies messages that relate to various kinds of interactive explanations identified in the explainable AI literature. This allows us to understand what type of explanations humans expect from their teammates in such settings, and thus where AI-equipped robots most need explanation capabilities. We find that most explanation-related messages seek clarification in the decisions or actions taken. We also confirm that messages have an impact on the performance of our simulated task.
* 4 pages, 3 figures, published as a Late Breaking Report in RO-MAN 2024
Can we Constrain Concept Bottleneck Models to Learn Semantically Meaningful Input Features?
Feb 01, 2024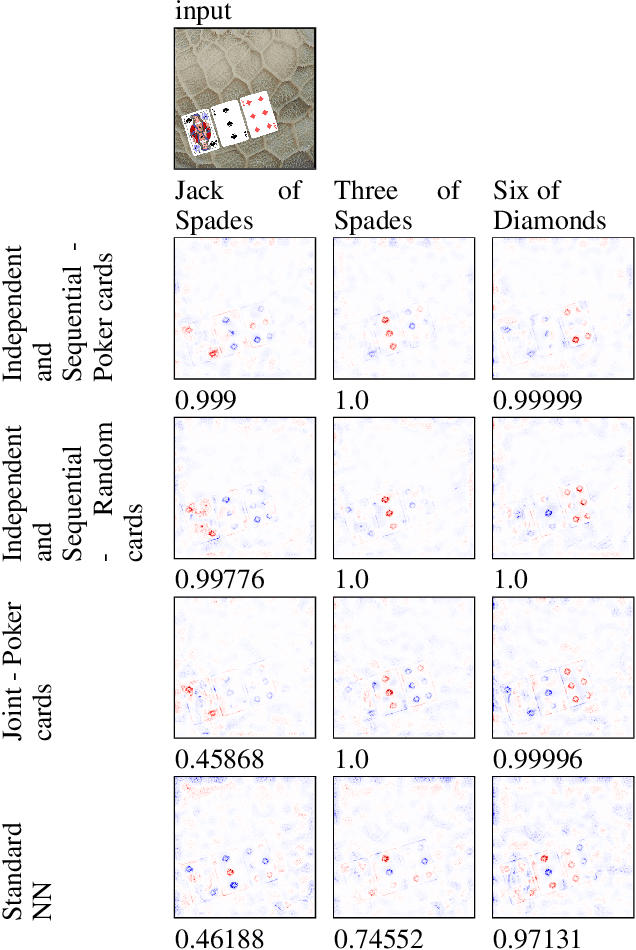
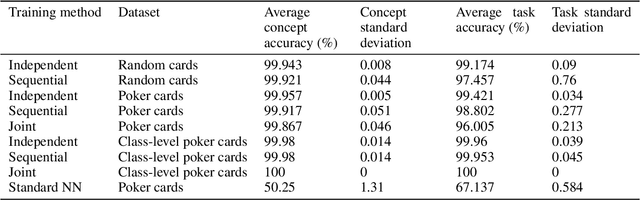
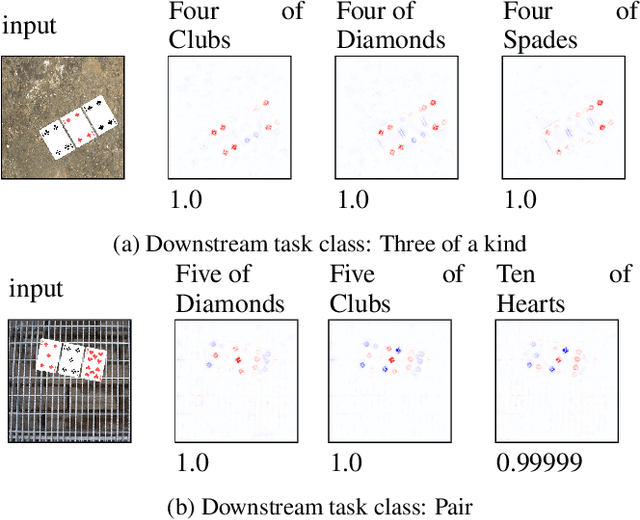

Concept Bottleneck Models (CBMs) are considered inherently interpretable because they first predict a set of human-defined concepts before using these concepts to predict the output of a downstream task. For inherent interpretability to be fully realised, and ensure trust in a model's output, we need to guarantee concepts are predicted based on semantically mapped input features. For example, one might expect the pixels representing a broken bone in an image to be used for the prediction of a fracture. However, current literature indicates this is not the case, as concept predictions are often mapped to irrelevant input features. We hypothesise that this occurs when concept annotations are inaccurate or how input features should relate to concepts is unclear. In general, the effect of dataset labelling on concept representations in CBMs remains an understudied area. Therefore, in this paper, we examine how CBMs learn concepts from datasets with fine-grained concept annotations. We demonstrate that CBMs can learn concept representations with semantic mapping to input features by removing problematic concept correlations, such as two concepts always appearing together. To support our evaluation, we introduce a new synthetic image dataset based on a playing cards domain, which we hope will serve as a benchmark for future CBM research. For validation, we provide empirical evidence on a real-world dataset of chest X-rays, to demonstrate semantically meaningful concepts can be learned in real-world applications.
Towards a Deeper Understanding of Concept Bottleneck Models Through End-to-End Explanation
Feb 07, 2023Concept Bottleneck Models (CBMs) first map raw input(s) to a vector of human-defined concepts, before using this vector to predict a final classification. We might therefore expect CBMs capable of predicting concepts based on distinct regions of an input. In doing so, this would support human interpretation when generating explanations of the model's outputs to visualise input features corresponding to concepts. The contribution of this paper is threefold: Firstly, we expand on existing literature by looking at relevance both from the input to the concept vector, confirming that relevance is distributed among the input features, and from the concept vector to the final classification where, for the most part, the final classification is made using concepts predicted as present. Secondly, we report a quantitative evaluation to measure the distance between the maximum input feature relevance and the ground truth location; we perform this with the techniques, Layer-wise Relevance Propagation (LRP), Integrated Gradients (IG) and a baseline gradient approach, finding LRP has a lower average distance than IG. Thirdly, we propose using the proportion of relevance as a measurement for explaining concept importance.
An Experimentation Platform for Explainable Coalition Situational Understanding
Nov 09, 2020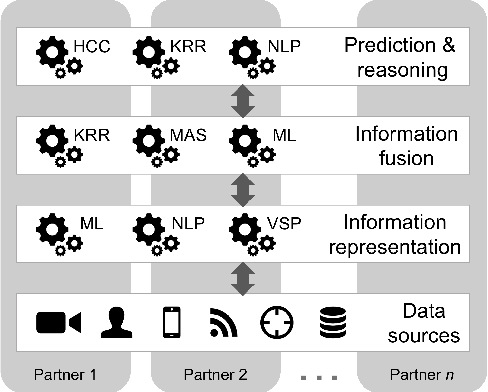
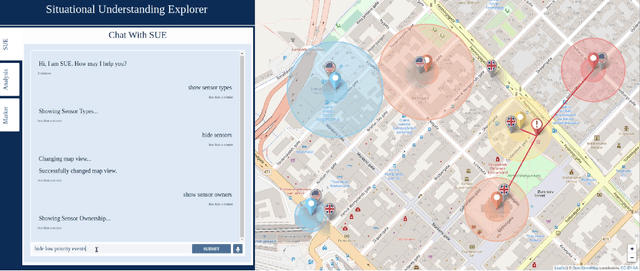
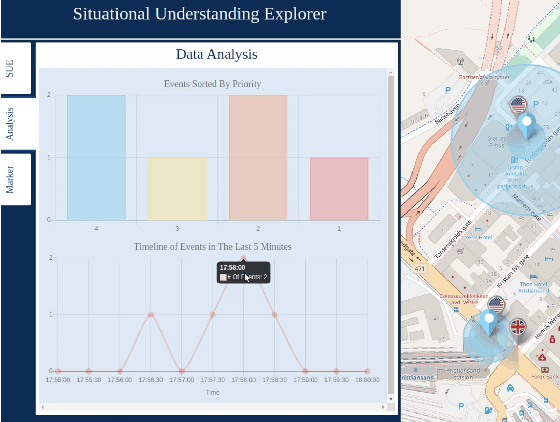
We present an experimentation platform for coalition situational understanding research that highlights capabilities in explainable artificial intelligence/machine learning (AI/ML) and integration of symbolic and subsymbolic AI/ML approaches for event processing. The Situational Understanding Explorer (SUE) platform is designed to be lightweight, to easily facilitate experiments and demonstrations, and open. We discuss our requirements to support coalition multi-domain operations with emphasis on asset interoperability and ad hoc human-machine teaming in a dense urban terrain setting. We describe the interface functionality and give examples of SUE applied to coalition situational understanding tasks.