 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan we Constrain Concept Bottleneck Models to Learn Semantically Meaningful Input Features?
Paper and Code
Feb 01, 2024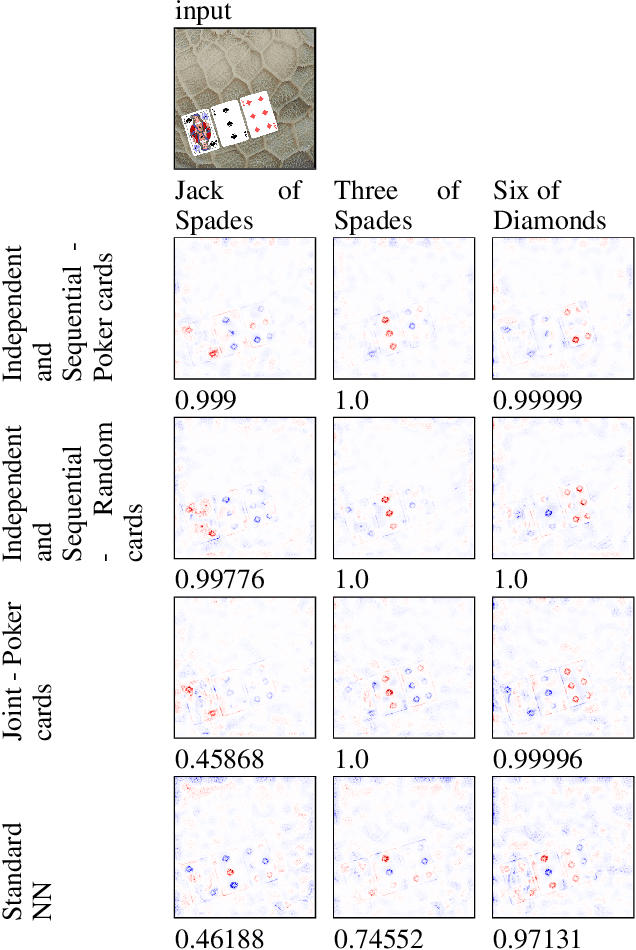
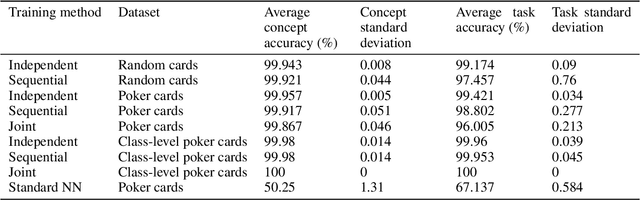
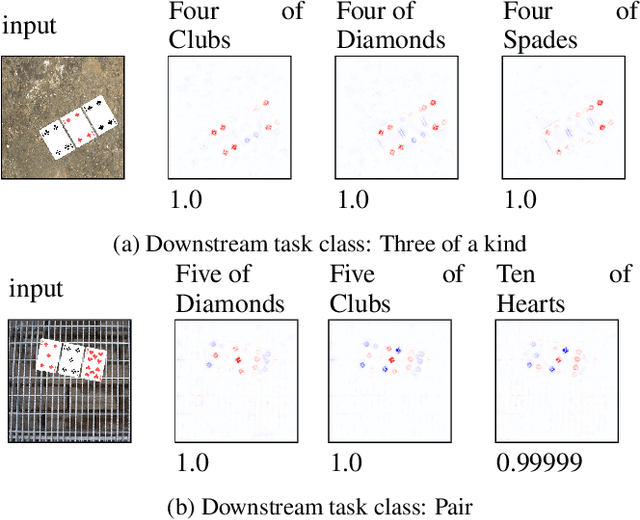

Concept Bottleneck Models (CBMs) are considered inherently interpretable because they first predict a set of human-defined concepts before using these concepts to predict the output of a downstream task. For inherent interpretability to be fully realised, and ensure trust in a model's output, we need to guarantee concepts are predicted based on semantically mapped input features. For example, one might expect the pixels representing a broken bone in an image to be used for the prediction of a fracture. However, current literature indicates this is not the case, as concept predictions are often mapped to irrelevant input features. We hypothesise that this occurs when concept annotations are inaccurate or how input features should relate to concepts is unclear. In general, the effect of dataset labelling on concept representations in CBMs remains an understudied area. Therefore, in this paper, we examine how CBMs learn concepts from datasets with fine-grained concept annotations. We demonstrate that CBMs can learn concept representations with semantic mapping to input features by removing problematic concept correlations, such as two concepts always appearing together. To support our evaluation, we introduce a new synthetic image dataset based on a playing cards domain, which we hope will serve as a benchmark for future CBM research. For validation, we provide empirical evidence on a real-world dataset of chest X-rays, to demonstrate semantically meaningful concepts can be learned in real-world applications.