 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Foundation Models in Neuro-Symbolic Learning and Reasoning
Feb 02, 2024Neuro-Symbolic AI (NeSy) holds promise to ensure the safe deployment of AI systems, as interpretable symbolic techniques provide formal behaviour guarantees. The challenge is how to effectively integrate neural and symbolic computation, to enable learning and reasoning from raw data. Existing pipelines that train the neural and symbolic components sequentially require extensive labelling, whereas end-to-end approaches are limited in terms of scalability, due to the combinatorial explosion in the symbol grounding problem. In this paper, we leverage the implicit knowledge within foundation models to enhance the performance in NeSy tasks, whilst reducing the amount of data labelling and manual engineering. We introduce a new architecture, called NeSyGPT, which fine-tunes a vision-language foundation model to extract symbolic features from raw data, before learning a highly expressive answer set program to solve a downstream task. Our comprehensive evaluation demonstrates that NeSyGPT has superior accuracy over various baselines, and can scale to complex NeSy tasks. Finally, we highlight the effective use of a large language model to generate the programmatic interface between the neural and symbolic components, significantly reducing the amount of manual engineering required.
Can we Constrain Concept Bottleneck Models to Learn Semantically Meaningful Input Features?
Feb 01, 2024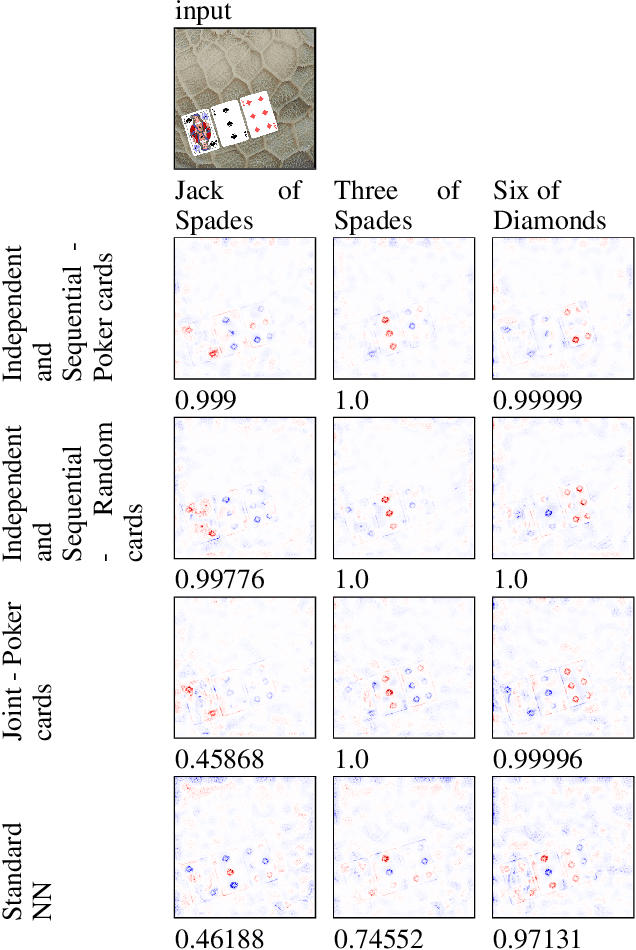
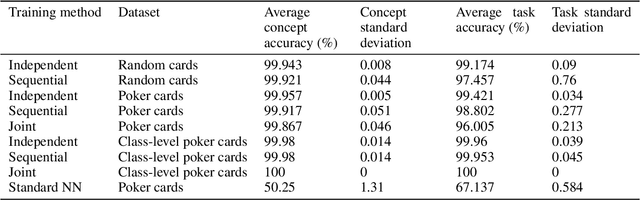
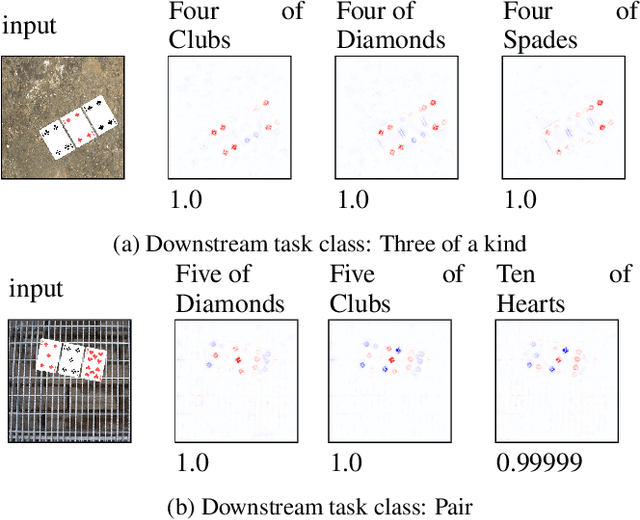

Concept Bottleneck Models (CBMs) are considered inherently interpretable because they first predict a set of human-defined concepts before using these concepts to predict the output of a downstream task. For inherent interpretability to be fully realised, and ensure trust in a model's output, we need to guarantee concepts are predicted based on semantically mapped input features. For example, one might expect the pixels representing a broken bone in an image to be used for the prediction of a fracture. However, current literature indicates this is not the case, as concept predictions are often mapped to irrelevant input features. We hypothesise that this occurs when concept annotations are inaccurate or how input features should relate to concepts is unclear. In general, the effect of dataset labelling on concept representations in CBMs remains an understudied area. Therefore, in this paper, we examine how CBMs learn concepts from datasets with fine-grained concept annotations. We demonstrate that CBMs can learn concept representations with semantic mapping to input features by removing problematic concept correlations, such as two concepts always appearing together. To support our evaluation, we introduce a new synthetic image dataset based on a playing cards domain, which we hope will serve as a benchmark for future CBM research. For validation, we provide empirical evidence on a real-world dataset of chest X-rays, to demonstrate semantically meaningful concepts can be learned in real-world applications.
Towards a Deeper Understanding of Concept Bottleneck Models Through End-to-End Explanation
Feb 07, 2023Concept Bottleneck Models (CBMs) first map raw input(s) to a vector of human-defined concepts, before using this vector to predict a final classification. We might therefore expect CBMs capable of predicting concepts based on distinct regions of an input. In doing so, this would support human interpretation when generating explanations of the model's outputs to visualise input features corresponding to concepts. The contribution of this paper is threefold: Firstly, we expand on existing literature by looking at relevance both from the input to the concept vector, confirming that relevance is distributed among the input features, and from the concept vector to the final classification where, for the most part, the final classification is made using concepts predicted as present. Secondly, we report a quantitative evaluation to measure the distance between the maximum input feature relevance and the ground truth location; we perform this with the techniques, Layer-wise Relevance Propagation (LRP), Integrated Gradients (IG) and a baseline gradient approach, finding LRP has a lower average distance than IG. Thirdly, we propose using the proportion of relevance as a measurement for explaining concept importance.
Inductive Learning of Complex Knowledge from Raw Data
May 25, 2022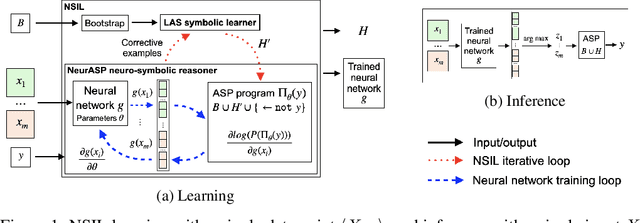
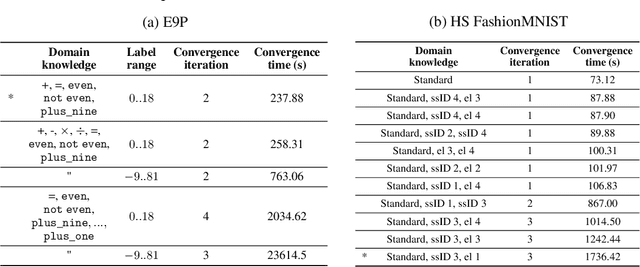
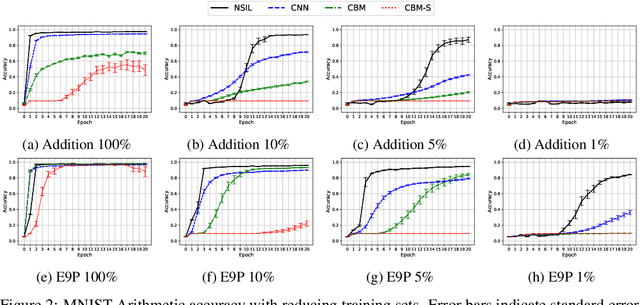
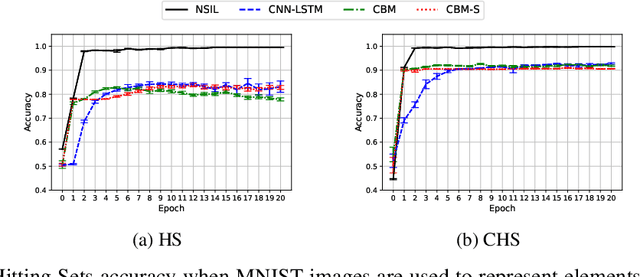
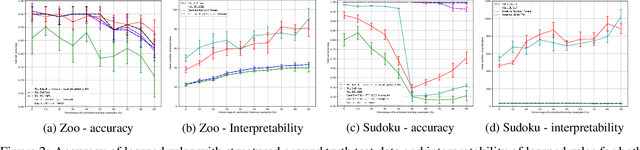
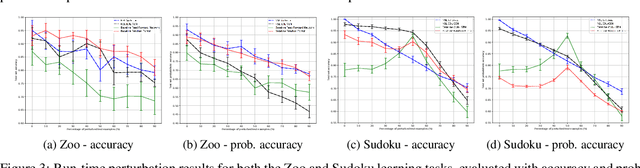
One of the ultimate goals of Artificial Intelligence is to learn generalised and human-interpretable knowledge from raw data. Neuro-symbolic reasoning approaches partly tackle this problem by improving the training of a neural network using a manually engineered symbolic knowledge base. In the case where symbolic knowledge is learned from raw data, this knowledge lacks the expressivity required to solve complex problems. In this paper, we introduce Neuro-Symbolic Inductive Learner (NSIL), an approach that trains a neural network to extract latent concepts from raw data, whilst learning symbolic knowledge that solves complex problems, defined in terms of these latent concepts. The novelty of our approach is a method for biasing a symbolic learner to learn improved knowledge, based on the in-training performance of both neural and symbolic components. We evaluate NSIL on two problem domains that require learning knowledge with different levels of complexity, and demonstrate that NSIL learns knowledge that is not possible to learn with other neuro-symbolic systems, whilst outperforming baseline models in terms of accuracy and data efficiency.
FF-NSL: Feed-Forward Neural-Symbolic Learner
Jul 02, 2021
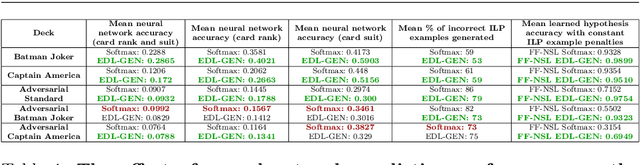

Inductive Logic Programming (ILP) aims to learn generalised, interpretable hypotheses in a data-efficient manner. However, current ILP systems require training examples to be specified in a structured logical form. To address this problem, this paper proposes a neural-symbolic learning framework, called Feed-Forward Neural-Symbolic Learner (FF-NSL), that integrates state-of-the-art ILP systems, based on the Answer Set semantics, with Neural Networks (NNs), in order to learn interpretable hypotheses from labelled unstructured data. To demonstrate the generality and robustness of FF-NSL, we use two datasets subject to distributional shifts, for which pre-trained NNs may give incorrect predictions with high confidence. Experimental results show that FF-NSL outperforms tree-based and neural-based approaches by learning more accurate and interpretable hypotheses with fewer examples.
NSL: Hybrid Interpretable Learning From Noisy Raw Data
Dec 09, 2020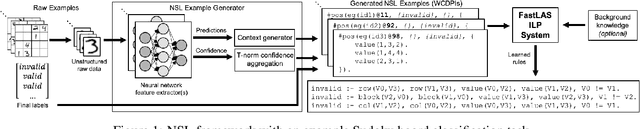
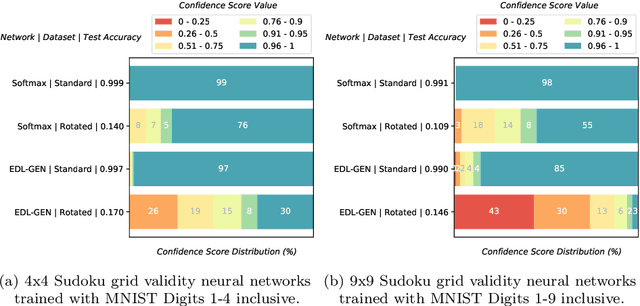
Inductive Logic Programming (ILP) systems learn generalised, interpretable rules in a data-efficient manner utilising existing background knowledge. However, current ILP systems require training examples to be specified in a structured logical format. Neural networks learn from unstructured data, although their learned models may be difficult to interpret and are vulnerable to data perturbations at run-time. This paper introduces a hybrid neural-symbolic learning framework, called NSL, that learns interpretable rules from labelled unstructured data. NSL combines pre-trained neural networks for feature extraction with FastLAS, a state-of-the-art ILP system for rule learning under the answer set semantics. Features extracted by the neural components define the structured context of labelled examples and the confidence of the neural predictions determines the level of noise of the examples. Using the scoring function of FastLAS, NSL searches for short, interpretable rules that generalise over such noisy examples. We evaluate our framework on propositional and first-order classification tasks using the MNIST dataset as raw data. Specifically, we demonstrate that NSL is able to learn robust rules from perturbed MNIST data and achieve comparable or superior accuracy when compared to neural network and random forest baselines whilst being more general and interpretable.
Synthetic Ground Truth Generation for Evaluating Generative Policy Models
Apr 26, 2019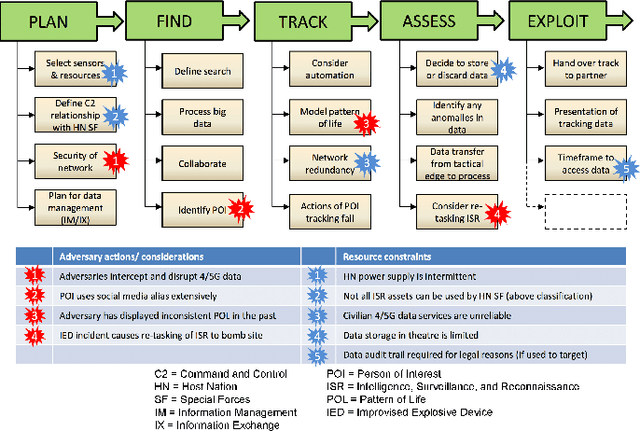
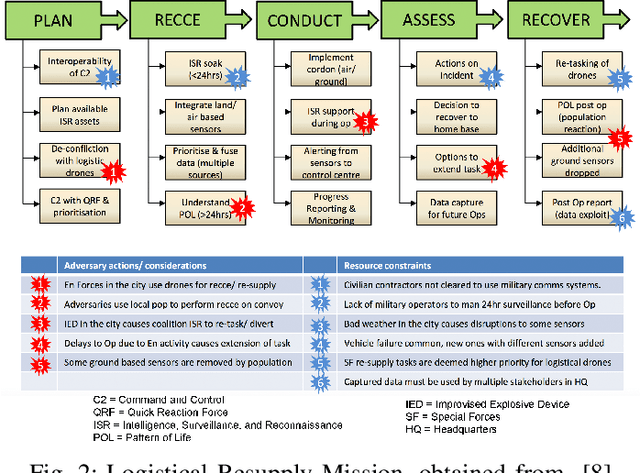
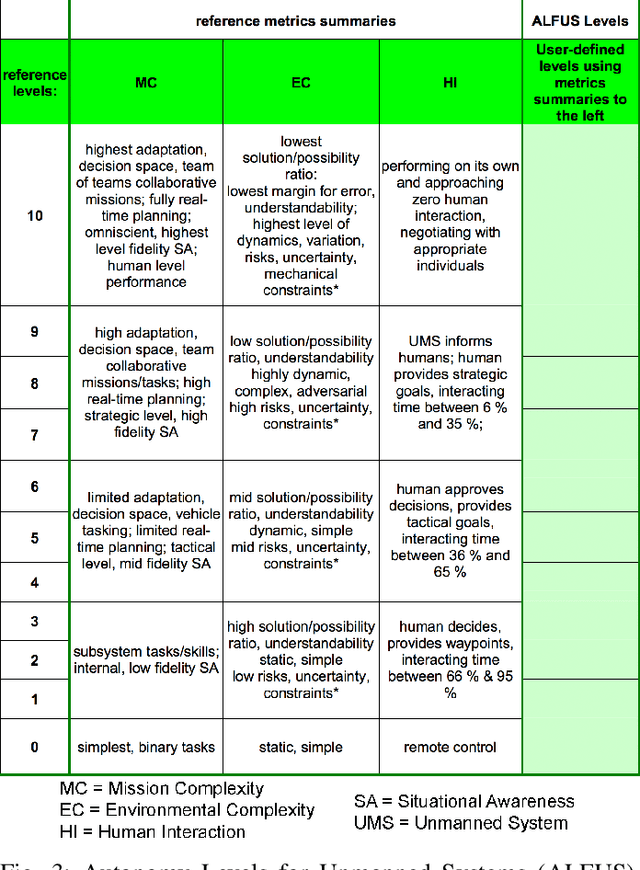

Generative Policy-based Models aim to enable a coalition of systems, be they devices or services to adapt according to contextual changes such as environmental factors, user preferences and different tasks whilst adhering to various constraints and regulations as directed by a managing party or the collective vision of the coalition. Recent developments have proposed new architectures to realize the potential of GPMs but as the complexity of systems and their associated requirements increases, there is an emerging requirement to have scenarios and associated datasets to realistically evaluate GPMs with respect to the properties of the operating environment, be it the future battlespace or an autonomous organization. In order to address this requirement, in this paper, we present a method of applying an agile knowledge representation framework to model requirements, both individualistic and collective that enables synthetic generation of ground truth data such that advanced GPMs can be evaluated robustly in complex environments. We also release conceptual models, annotated datasets, as well as means to extend the data generation approach so that similar datasets can be developed for varying complexities and different situations.