 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Open-Schema Entity Structure Discovery
Jun 04, 2025Entity structure extraction, which aims to extract entities and their associated attribute-value structures from text, is an essential task for text understanding and knowledge graph construction. Existing methods based on large language models (LLMs) typically rely heavily on predefined entity attribute schemas or annotated datasets, often leading to incomplete extraction results. To address these challenges, we introduce Zero-Shot Open-schema Entity Structure Discovery (ZOES), a novel approach to entity structure extraction that does not require any schema or annotated samples. ZOES operates via a principled mechanism of enrichment, refinement, and unification, based on the insight that an entity and its associated structure are mutually reinforcing. Experiments demonstrate that ZOES consistently enhances LLMs' ability to extract more complete entity structures across three different domains, showcasing both the effectiveness and generalizability of the method. These findings suggest that such an enrichment, refinement, and unification mechanism may serve as a principled approach to improving the quality of LLM-based entity structure discovery in various scenarios.
A framework for fostering transparency in shared artificial intelligence models by increasing visibility of contributions
Mar 05, 2021
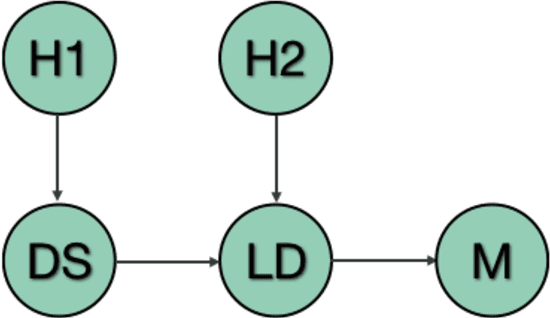

Increased adoption of artificial intelligence (AI) systems into scientific workflows will result in an increasing technical debt as the distance between the data scientists and engineers who develop AI system components and scientists, researchers and other users grows. This could quickly become problematic, particularly where guidance or regulations change and once-acceptable best practice becomes outdated, or where data sources are later discredited as biased or inaccurate. This paper presents a novel method for deriving a quantifiable metric capable of ranking the overall transparency of the process pipelines used to generate AI systems, such that users, auditors and other stakeholders can gain confidence that they will be able to validate and trust the data sources and contributors in the AI systems that they rely on. The methodology for calculating the metric, and the type of criteria that could be used to make judgements on the visibility of contributions to systems are evaluated through models published at ModelHub and PyTorch Hub, popular archives for sharing science resources, and is found to be helpful in driving consideration of the contributions made to generating AI systems and approaches towards effective documentation and improving transparency in machine learning assets shared within scientific communities.
Synthetic Ground Truth Generation for Evaluating Generative Policy Models
Apr 26, 2019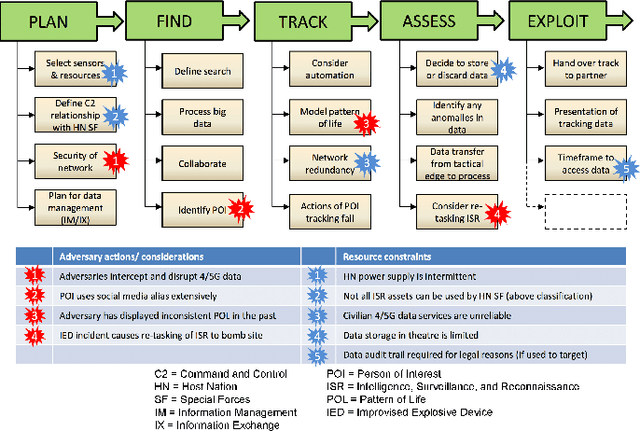
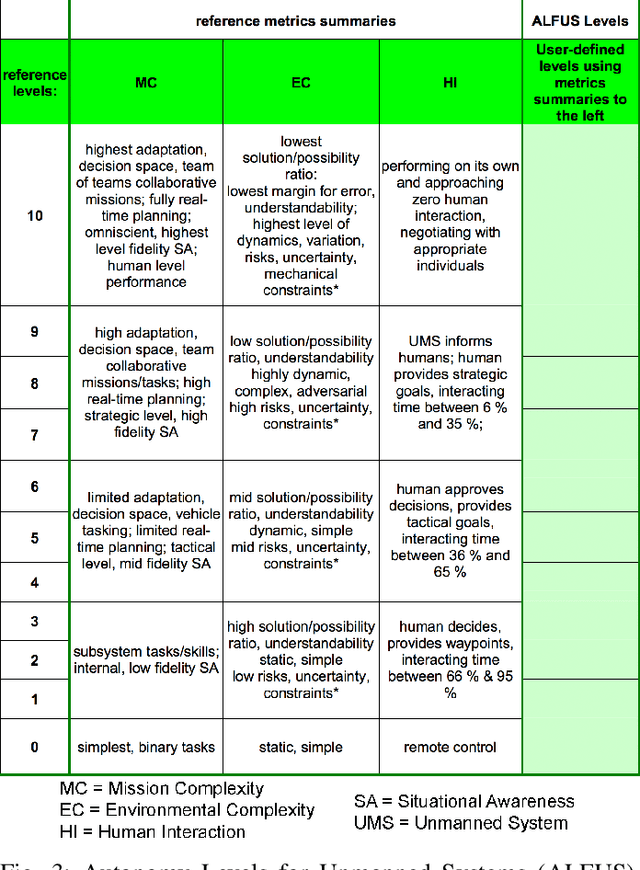

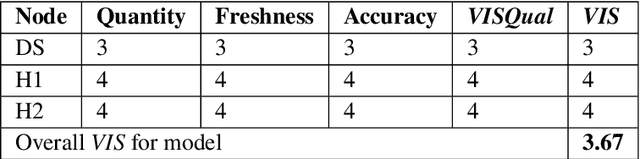
Generative Policy-based Models aim to enable a coalition of systems, be they devices or services to adapt according to contextual changes such as environmental factors, user preferences and different tasks whilst adhering to various constraints and regulations as directed by a managing party or the collective vision of the coalition. Recent developments have proposed new architectures to realize the potential of GPMs but as the complexity of systems and their associated requirements increases, there is an emerging requirement to have scenarios and associated datasets to realistically evaluate GPMs with respect to the properties of the operating environment, be it the future battlespace or an autonomous organization. In order to address this requirement, in this paper, we present a method of applying an agile knowledge representation framework to model requirements, both individualistic and collective that enables synthetic generation of ground truth data such that advanced GPMs can be evaluated robustly in complex environments. We also release conceptual models, annotated datasets, as well as means to extend the data generation approach so that similar datasets can be developed for varying complexities and different situations.
Feature-based reformulation of entities in triple pattern queries
Jul 04, 2018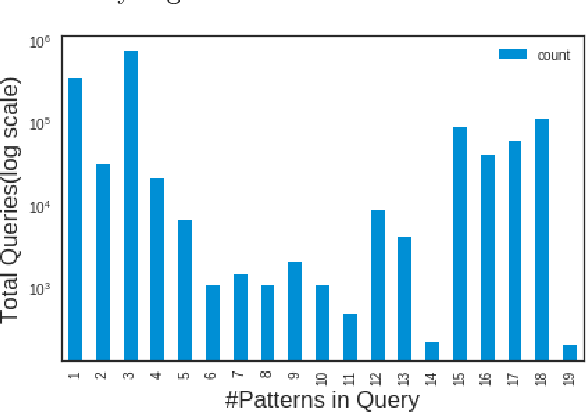
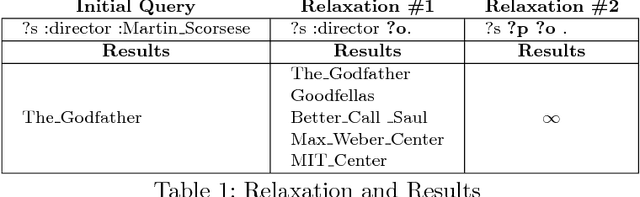
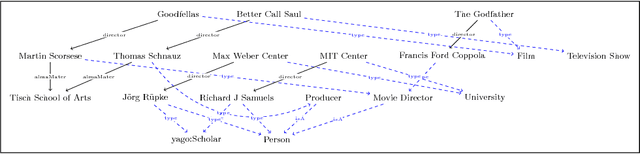

Knowledge graphs encode uniquely identifiable entities to other entities or literal values by means of relationships, thus enabling semantically rich querying over the stored data. Typically, the semantics of such queries are often crisp thereby resulting in crisp answers. Query log statistics show that a majority of the queries issued to knowledge graphs are often entity centric queries. When a user needs additional answers the state-of-the-art in assisting users is to rewrite the original query resulting in a set of approximations. Several strategies have been proposed in past to address this. They typically move up the taxonomy to relax a specific element to a more generic element. Entities don't have a taxonomy and they end up being generalized. To address this issue, in this paper, we propose an entity centric reformulation strategy that utilizes schema information and entity features present in the graph to suggest rewrites. Once the features are identified, the entity in concern is reformulated as a set of features. Since entities can have a large number of features, we introduce strategies that select the top-k most relevant and {informative ranked features and augment them to the original query to create a valid reformulation. We then evaluate our approach by showing that our reformulation strategy produces results that are more informative when compared with state-of-the-art