 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Chest X-ray Pathology Models using Textual Concepts
Jun 30, 2024


Deep learning models have revolutionized medical imaging and diagnostics, yet their opaque nature poses challenges for clinical adoption and trust. Amongst approaches to improve model interpretability, concept-based explanations aim to provide concise and human understandable explanations of any arbitrary classifier. However, such methods usually require a large amount of manually collected data with concept annotation, which is often scarce in the medical domain. In this paper, we propose Conceptual Counterfactual Explanations for Chest X-ray (CoCoX) that leverage existing vision-language models (VLM) joint embedding space to explain black-box classifier outcomes without the need for annotated datasets. Specifically, we utilize textual concepts derived from chest radiography reports and a pre-trained chest radiography-based VLM to explain three common cardiothoracic pathologies. We demonstrate that the explanations generated by our method are semantically meaningful and faithful to underlying pathologies.
Training Deep Neural Networks with Constrained Learning Parameters
Sep 01, 2020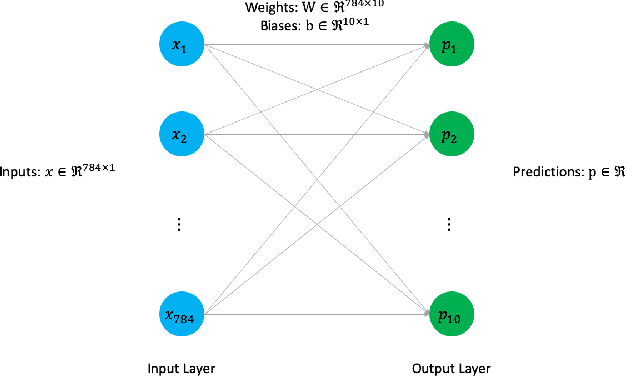
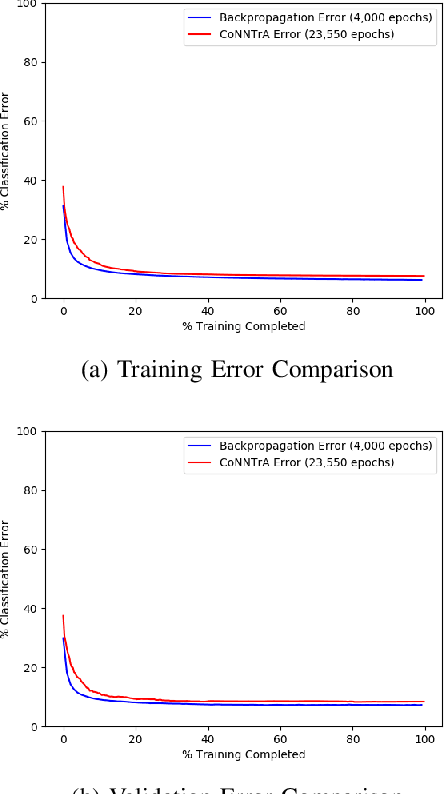
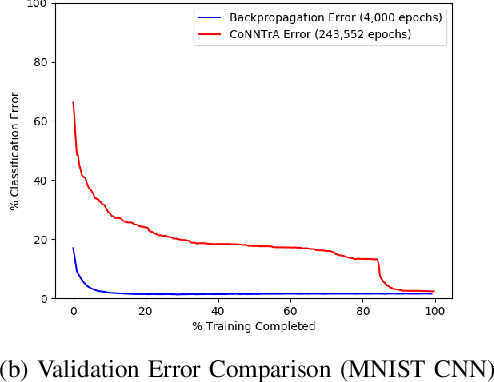
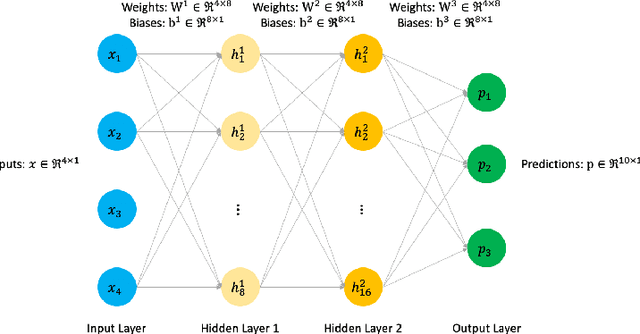
Today's deep learning models are primarily trained on CPUs and GPUs. Although these models tend to have low error, they consume high power and utilize large amount of memory owing to double precision floating point learning parameters. Beyond the Moore's law, a significant portion of deep learning tasks would run on edge computing systems, which will form an indispensable part of the entire computation fabric. Subsequently, training deep learning models for such systems will have to be tailored and adopted to generate models that have the following desirable characteristics: low error, low memory, and low power. We believe that deep neural networks (DNNs), where learning parameters are constrained to have a set of finite discrete values, running on neuromorphic computing systems would be instrumental for intelligent edge computing systems having these desirable characteristics. To this extent, we propose the Combinatorial Neural Network Training Algorithm (CoNNTrA), that leverages a coordinate gradient descent-based approach for training deep learning models with finite discrete learning parameters. Next, we elaborate on the theoretical underpinnings and evaluate the computational complexity of CoNNTrA. As a proof of concept, we use CoNNTrA to train deep learning models with ternary learning parameters on the MNIST, Iris and ImageNet data sets and compare their performance to the same models trained using Backpropagation. We use following performance metrics for the comparison: (i) Training error; (ii) Validation error; (iii) Memory usage; and (iv) Training time. Our results indicate that CoNNTrA models use 32x less memory and have errors at par with the Backpropagation models.
Knowledge Integration for Disease Characterization: A Breast Cancer Example
Jul 20, 2018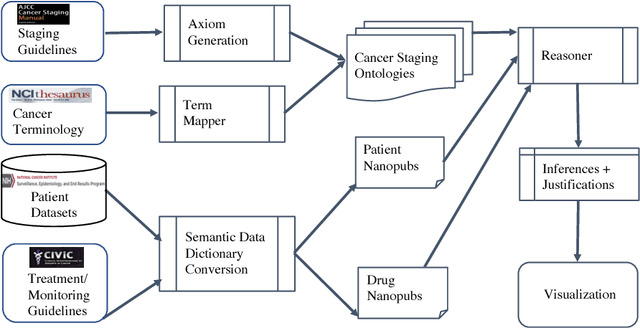

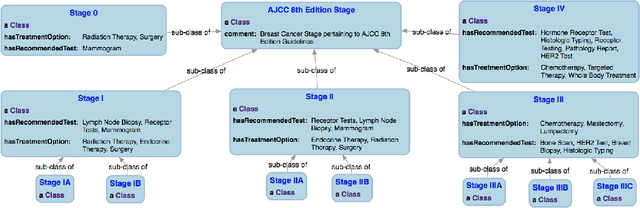
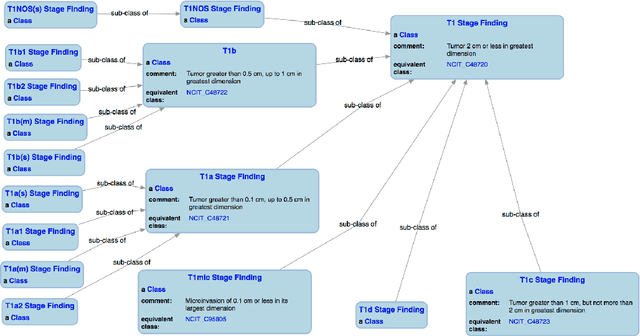
With the rapid advancements in cancer research, the information that is useful for characterizing disease, staging tumors, and creating treatment and survivorship plans has been changing at a pace that creates challenges when physicians try to remain current. One example involves increasing usage of biomarkers when characterizing the pathologic prognostic stage of a breast tumor. We present our semantic technology approach to support cancer characterization and demonstrate it in our end-to-end prototype system that collects the newest breast cancer staging criteria from authoritative oncology manuals to construct an ontology for breast cancer. Using a tool we developed that utilizes this ontology, physician-facing applications can be used to quickly stage a new patient to support identifying risks, treatment options, and monitoring plans based on authoritative and best practice guidelines. Physicians can also re-stage existing patients or patient populations, allowing them to find patients whose stage has changed in a given patient cohort. As new guidelines emerge, using our proposed mechanism, which is grounded by semantic technologies for ingesting new data from staging manuals, we have created an enriched cancer staging ontology that integrates relevant data from several sources with very little human intervention.
Feature-based reformulation of entities in triple pattern queries
Jul 04, 2018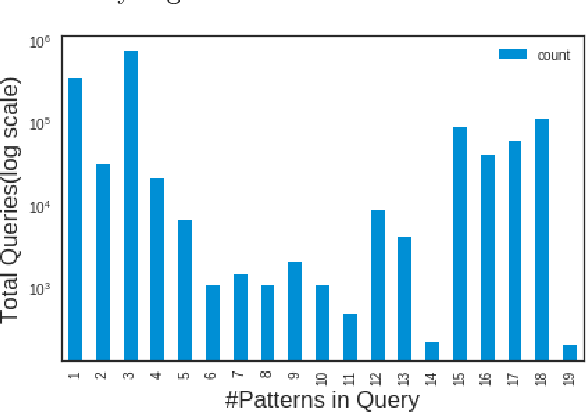
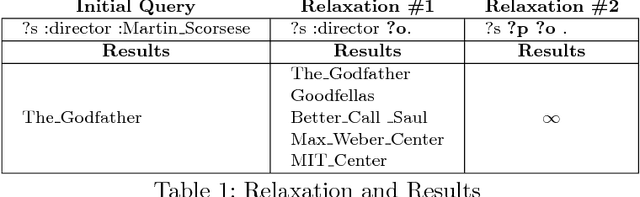
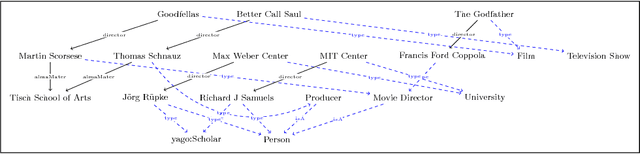

Knowledge graphs encode uniquely identifiable entities to other entities or literal values by means of relationships, thus enabling semantically rich querying over the stored data. Typically, the semantics of such queries are often crisp thereby resulting in crisp answers. Query log statistics show that a majority of the queries issued to knowledge graphs are often entity centric queries. When a user needs additional answers the state-of-the-art in assisting users is to rewrite the original query resulting in a set of approximations. Several strategies have been proposed in past to address this. They typically move up the taxonomy to relax a specific element to a more generic element. Entities don't have a taxonomy and they end up being generalized. To address this issue, in this paper, we propose an entity centric reformulation strategy that utilizes schema information and entity features present in the graph to suggest rewrites. Once the features are identified, the entity in concern is reformulated as a set of features. Since entities can have a large number of features, we introduce strategies that select the top-k most relevant and {informative ranked features and augment them to the original query to create a valid reformulation. We then evaluate our approach by showing that our reformulation strategy produces results that are more informative when compared with state-of-the-art