 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSAQA: Time Series Analysis Question And Answering Benchmark
Jan 30, 2026Time series data are integral to critical applications across domains such as finance, healthcare, transportation, and environmental science. While recent work has begun to explore multi-task time series question answering (QA), current benchmarks remain limited to forecasting and anomaly detection tasks. We introduce TSAQA, a novel unified benchmark designed to broaden task coverage and evaluate diverse temporal analysis capabilities. TSAQA integrates six diverse tasks under a single framework ranging from conventional analysis, including anomaly detection and classification, to advanced analysis, such as characterization, comparison, data transformation, and temporal relationship analysis. Spanning 210k samples across 13 domains, the dataset employs diverse formats, including true-or-false (TF), multiple-choice (MC), and a novel puzzling (PZ), to comprehensively assess time series analysis. Zero-shot evaluation demonstrates that these tasks are challenging for current Large Language Models (LLMs): the best-performing commercial LLM, Gemini-2.5-Flash, achieves an average score of only 65.08. Although instruction tuning boosts open-source performance: the best-performing open-source model, LLaMA-3.1-8B, shows significant room for improvement, highlighting the complexity of temporal analysis for LLMs.
Agentic Reasoning for Large Language Models
Jan 18, 2026Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.
AutoTool: Dynamic Tool Selection and Integration for Agentic Reasoning
Dec 15, 2025Agentic reinforcement learning has advanced large language models (LLMs) to reason through long chain-of-thought trajectories while interleaving external tool use. Existing approaches assume a fixed inventory of tools, limiting LLM agents' adaptability to new or evolving toolsets. We present AutoTool, a framework that equips LLM agents with dynamic tool-selection capabilities throughout their reasoning trajectories. We first construct a 200k dataset with explicit tool-selection rationales across 1,000+ tools and 100+ tasks spanning mathematics, science, code generation, and multimodal reasoning. Building on this data foundation, AutoTool employs a dual-phase optimization pipeline: (i) supervised and RL-based trajectory stabilization for coherent reasoning, and (ii) KL-regularized Plackett-Luce ranking to refine consistent multi-step tool selection. Across ten diverse benchmarks, we train two base models, Qwen3-8B and Qwen2.5-VL-7B, with AutoTool. With fewer parameters, AutoTool consistently outperforms advanced LLM agents and tool-integration methods, yielding average gains of 6.4% in math & science reasoning, 4.5% in search-based QA, 7.7% in code generation, and 6.9% in multimodal understanding. In addition, AutoTool exhibits stronger generalization by dynamically leveraging unseen tools from evolving toolsets during inference.
ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs
Jun 23, 2025



Process Reward Models (PRMs) have recently emerged as a powerful framework for supervising intermediate reasoning steps in large language models (LLMs). Previous PRMs are primarily trained on model final output responses and struggle to evaluate intermediate thinking trajectories robustly, especially in the emerging setting of trajectory-response outputs generated by frontier reasoning models like Deepseek-R1. In this work, we introduce ReasonFlux-PRM, a novel trajectory-aware PRM explicitly designed to evaluate the trajectory-response type of reasoning traces. ReasonFlux-PRM incorporates both step-level and trajectory-level supervision, enabling fine-grained reward assignment aligned with structured chain-of-thought data. We adapt ReasonFlux-PRM to support reward supervision under both offline and online settings, including (i) selecting high-quality model distillation data for downstream supervised fine-tuning of smaller models, (ii) providing dense process-level rewards for policy optimization during reinforcement learning, and (iii) enabling reward-guided Best-of-N test-time scaling. Empirical results on challenging downstream benchmarks such as AIME, MATH500, and GPQA-Diamond demonstrate that ReasonFlux-PRM-7B selects higher quality data than strong PRMs (e.g., Qwen2.5-Math-PRM-72B) and human-curated baselines. Furthermore, our derived ReasonFlux-PRM-7B yields consistent performance improvements, achieving average gains of 12.1% in supervised fine-tuning, 4.5% in reinforcement learning, and 6.3% in test-time scaling. We also release our efficient ReasonFlux-PRM-1.5B for resource-constrained applications and edge deployment. Projects: https://github.com/Gen-Verse/ReasonFlux
Zero-Shot Open-Schema Entity Structure Discovery
Jun 04, 2025Entity structure extraction, which aims to extract entities and their associated attribute-value structures from text, is an essential task for text understanding and knowledge graph construction. Existing methods based on large language models (LLMs) typically rely heavily on predefined entity attribute schemas or annotated datasets, often leading to incomplete extraction results. To address these challenges, we introduce Zero-Shot Open-schema Entity Structure Discovery (ZOES), a novel approach to entity structure extraction that does not require any schema or annotated samples. ZOES operates via a principled mechanism of enrichment, refinement, and unification, based on the insight that an entity and its associated structure are mutually reinforcing. Experiments demonstrate that ZOES consistently enhances LLMs' ability to extract more complete entity structures across three different domains, showcasing both the effectiveness and generalizability of the method. These findings suggest that such an enrichment, refinement, and unification mechanism may serve as a principled approach to improving the quality of LLM-based entity structure discovery in various scenarios.
Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning
May 22, 2025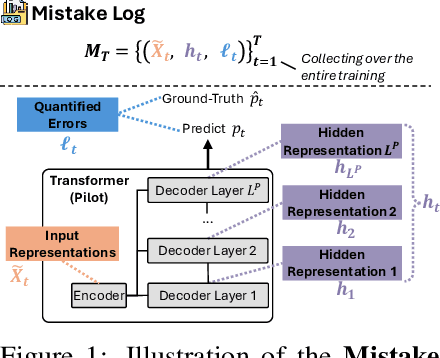
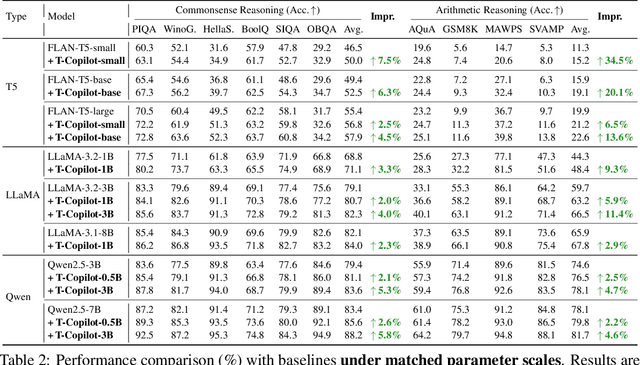
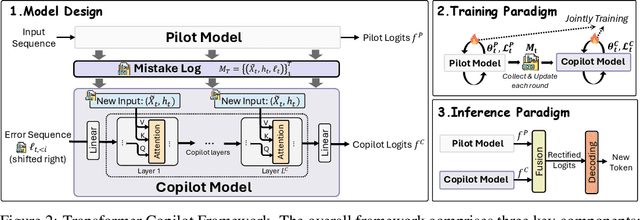
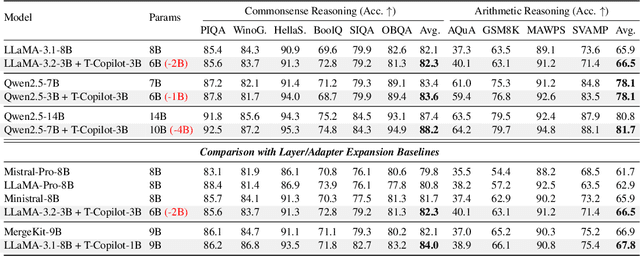
Large language models are typically adapted to downstream tasks through supervised fine-tuning on domain-specific data. While standard fine-tuning focuses on minimizing generation loss to optimize model parameters, we take a deeper step by retaining and leveraging the model's own learning signals, analogous to how human learners reflect on past mistakes to improve future performance. We first introduce the concept of Mistake Log to systematically track the model's learning behavior and recurring errors throughout fine-tuning. Treating the original transformer-based model as the Pilot, we correspondingly design a Copilot model to refine the Pilot's inference performance via logits rectification. We name the overall Pilot-Copilot framework the Transformer Copilot, which introduces (i) a novel Copilot model design, (ii) a joint training paradigm where the Copilot continuously learns from the evolving Mistake Log alongside the Pilot, and (iii) a fused inference paradigm where the Copilot rectifies the Pilot's logits for enhanced generation. We provide both theoretical and empirical analyses on our new learning framework. Experiments on 12 benchmarks spanning commonsense, arithmetic, and recommendation tasks demonstrate that Transformer Copilot consistently improves performance by up to 34.5%, while introducing marginal computational overhead to Pilot models and exhibiting strong scalability and transferability.
GTR: Graph-Table-RAG for Cross-Table Question Answering
Apr 03, 2025Beyond pure text, a substantial amount of knowledge is stored in tables. In real-world scenarios, user questions often require retrieving answers that are distributed across multiple tables. GraphRAG has recently attracted much attention for enhancing LLMs' reasoning capabilities by organizing external knowledge to address ad-hoc and complex questions, exemplifying a promising direction for cross-table question answering. In this paper, to address the current gap in available data, we first introduce a multi-table benchmark, MutliTableQA, comprising 60k tables and 25k user queries collected from real-world sources. Then, we propose the first Graph-Table-RAG framework, namely GTR, which reorganizes table corpora into a heterogeneous graph, employs a hierarchical coarse-to-fine retrieval process to extract the most relevant tables, and integrates graph-aware prompting for downstream LLMs' tabular reasoning. Extensive experiments show that GTR exhibits superior cross-table question-answering performance while maintaining high deployment efficiency, demonstrating its real-world practical applicability.
Language in the Flow of Time: Time-Series-Paired Texts Weaved into a Unified Temporal Narrative
Feb 13, 2025While many advances in time series models focus exclusively on numerical data, research on multimodal time series, particularly those involving contextual textual information commonly encountered in real-world scenarios, remains in its infancy. Consequently, effectively integrating the text modality remains challenging. In this work, we highlight an intuitive yet significant observation that has been overlooked by existing works: time-series-paired texts exhibit periodic properties that closely mirror those of the original time series. Building on this insight, we propose a novel framework, Texts as Time Series (TaTS), which considers the time-series-paired texts to be auxiliary variables of the time series. TaTS can be plugged into any existing numerical-only time series models and enable them to handle time series data with paired texts effectively. Through extensive experiments on both multimodal time series forecasting and imputation tasks across benchmark datasets with various existing time series models, we demonstrate that TaTS can enhance predictive performance and achieve outperformance without modifying model architectures.
PageRank Bandits for Link Prediction
Nov 03, 2024Link prediction is a critical problem in graph learning with broad applications such as recommender systems and knowledge graph completion. Numerous research efforts have been directed at solving this problem, including approaches based on similarity metrics and Graph Neural Networks (GNN). However, most existing solutions are still rooted in conventional supervised learning, which makes it challenging to adapt over time to changing customer interests and to address the inherent dilemma of exploitation versus exploration in link prediction. To tackle these challenges, this paper reformulates link prediction as a sequential decision-making process, where each link prediction interaction occurs sequentially. We propose a novel fusion algorithm, PRB (PageRank Bandits), which is the first to combine contextual bandits with PageRank for collaborative exploitation and exploration. We also introduce a new reward formulation and provide a theoretical performance guarantee for PRB. Finally, we extensively evaluate PRB in both online and offline settings, comparing it with bandit-based and graph-based methods. The empirical success of PRB demonstrates the value of the proposed fusion approach. Our code is released at https://github.com/jiaruzouu/PRB.
STEM-POM: Evaluating Language Models Math-Symbol Reasoning in Document Parsing
Nov 01, 2024
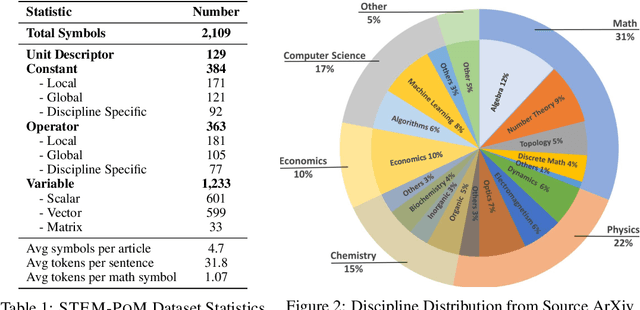


Advances in large language models (LLMs) have spurred research into enhancing their reasoning capabilities, particularly in math-rich STEM documents. While LLMs can generate equations or solve math-related queries, their ability to fully understand and interpret abstract mathematical symbols in long, math-rich documents remains limited. In this paper, we introduce STEM-PoM, a comprehensive benchmark dataset designed to evaluate LLMs' reasoning abilities on math symbols within contextual scientific text. The dataset, sourced from real-world ArXiv documents, contains over 2K math symbols classified as main attributes of variables, constants, operators, and unit descriptors, with additional sub-attributes including scalar/vector/matrix for variables and local/global/discipline-specific labels for both constants and operators. Our extensive experiments show that state-of-the-art LLMs achieve an average of 20-60% accuracy under in-context learning and 50-60% accuracy with fine-tuning, revealing a significant gap in their mathematical reasoning capabilities. STEM-PoM fuels future research of developing advanced Math-AI models that can robustly handle math symbols.