 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiVA: Gradient-Informed Bases for Vector-Based Adaptation
Apr 23, 2026As model sizes continue to grow, parameter-efficient fine-tuning has emerged as a powerful alternative to full fine-tuning. While LoRA is widely adopted among these methods, recent research has explored vector-based adaptation methods due to their extreme parameter efficiency. However, these methods typically require substantially higher ranks than LoRA to match its performance, leading to increased training costs. This work introduces GiVA, a gradient-based initialization strategy for vector-based adaptation. It achieves training times comparable to LoRA and maintains the extreme parameter efficiency of vector-based adaptation. We evaluate GiVA across diverse benchmarks, including natural language understanding, natural language generation, and image classification. Experiments show that our approach consistently outperforms or achieves performance competitive with existing vector-based adaptation methods and LoRA while reducing rank requirements by a factor of eight ($8\times$).
Integrating Arithmetic Learning Improves Mathematical Reasoning in Smaller Models
Feb 18, 2025While large models pre-trained on high-quality data exhibit excellent performance across various reasoning tasks, including mathematical reasoning (e.g. GSM8k, MultiArith), specializing smaller models to excel at mathematical reasoning remains a challenging problem. Common approaches to address this challenge include knowledge distillation, where smaller student models learn from large pre-trained teacher models, and data augmentation, such as rephrasing questions. Despite these efforts, smaller models struggle with arithmetic computations, leading to errors in mathematical reasoning. In this work, we focus on leveraging a programmatically generated arithmetic dataset to enhance the reasoning capabilities of smaller models. We investigate two key approaches to incorporate this dataset -- (1) intermediate fine-tuning, where a model is fine-tuned on the arithmetic dataset before being trained on a reasoning dataset, and (2) integrating the arithmetic dataset into the instruction-tuning mixture, allowing the model to learn arithmetic skills alongside general instruction-following abilities. Our experiments on multiple reasoning benchmarks demonstrate that incorporating an arithmetic dataset, whether through targeted fine-tuning or within the instruction-tuning mixture, enhances the models' arithmetic capabilities, which in turn improves their mathematical reasoning performance.
E-Gen: Leveraging E-Graphs to Improve Continuous Representations of Symbolic Expressions
Jan 24, 2025As vector representations have been pivotal in advancing natural language processing (NLP), some prior research has concentrated on creating embedding techniques for mathematical expressions by leveraging mathematically equivalent expressions. While effective, these methods are limited by the training data. In this work, we propose augmenting prior algorithms with larger synthetic dataset, using a novel e-graph-based generation scheme. This new mathematical dataset generation scheme, E-Gen, improves upon prior dataset-generation schemes that are limited in size and operator types. We use this dataset to compare embedding models trained with two methods: (1) training the model to generate mathematically equivalent expressions, and (2) training the model using contrastive learning to group mathematically equivalent expressions explicitly. We evaluate the embeddings generated by these methods against prior work on both in-distribution and out-of-distribution language processing tasks. Finally, we compare the performance of our embedding scheme against state-of-the-art large language models and demonstrate that embedding-based language processing methods perform better than LLMs on several tasks, demonstrating the necessity of optimizing embedding methods for the mathematical data modality.
STEM-POM: Evaluating Language Models Math-Symbol Reasoning in Document Parsing
Nov 01, 2024
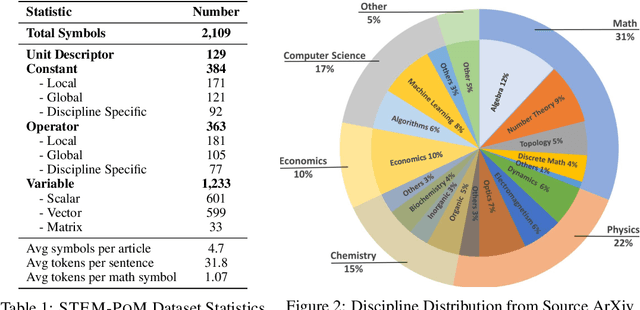


Advances in large language models (LLMs) have spurred research into enhancing their reasoning capabilities, particularly in math-rich STEM documents. While LLMs can generate equations or solve math-related queries, their ability to fully understand and interpret abstract mathematical symbols in long, math-rich documents remains limited. In this paper, we introduce STEM-PoM, a comprehensive benchmark dataset designed to evaluate LLMs' reasoning abilities on math symbols within contextual scientific text. The dataset, sourced from real-world ArXiv documents, contains over 2K math symbols classified as main attributes of variables, constants, operators, and unit descriptors, with additional sub-attributes including scalar/vector/matrix for variables and local/global/discipline-specific labels for both constants and operators. Our extensive experiments show that state-of-the-art LLMs achieve an average of 20-60% accuracy under in-context learning and 50-60% accuracy with fine-tuning, revealing a significant gap in their mathematical reasoning capabilities. STEM-PoM fuels future research of developing advanced Math-AI models that can robustly handle math symbols.
Mathematical Derivation Graphs: A Task for Summarizing Equation Dependencies in STEM Manuscripts
Oct 26, 2024Recent advances in natural language processing (NLP), particularly with the emergence of large language models (LLMs), have significantly enhanced the field of textual analysis. However, while these developments have yielded substantial progress in analyzing textual data, applying analysis to mathematical equations and their relationships within texts has produced mixed results. In this paper, we take the initial steps toward understanding the dependency relationships between mathematical expressions in STEM articles. Our dataset, sourced from a random sampling of the arXiv corpus, contains an analysis of 107 published STEM manuscripts whose inter-equation dependency relationships have been hand-labeled, resulting in a new object we refer to as a derivation graph that summarizes the mathematical content of the manuscript. We exhaustively evaluate analytical and NLP-based models to assess their capability to identify and extract the derivation relationships for each article and compare the results with the ground truth. Our comprehensive testing finds that both analytical and NLP models (including LLMs) achieve $\sim$40-50% F1 scores for extracting derivation graphs from articles, revealing that the recent advances in NLP have not made significant inroads in comprehending mathematical texts compared to simpler analytic models. While current approaches offer a solid foundation for extracting mathematical information, further research is necessary to improve accuracy and depth in this area.
Highlighting Named Entities in Input for Auto-Formulation of Optimization Problems
Dec 26, 2022Operations research deals with modeling and solving real-world problems as mathematical optimization problems. While solving mathematical systems is accomplished by analytical software, formulating a problem as a set of mathematical operations has been typically done manually by domain experts. However, recent machine learning models have shown promise in converting textual problem descriptions to corresponding mathematical formulations. In this paper, we present an approach that converts linear programming word problems into meaning representations that are structured and can be used by optimization solvers. Our approach uses the named entity-based enrichment to augment the input and achieves state-of-the-art accuracy, winning the second task of the NL4Opt competition (https://nl4opt.github.io).